Introducing a limited preview of GPT-5.6 Sol, our next generation frontier model, as well as GPT-5.6 Terra, a balanced model for efficient, everyday work, and GPT-5.6 Luna, a fast and affordable model for high-volume work.
https://t.co/OoM83SyISN
I’m excited to share that I’ll be joining OpenAI and look forward to working with the exceptional team there.
It was a difficult decision to move on. I’m incredibly proud of the amazing team at Google and everything we’ve built together. It has been an honor and a pleasure to work with all of you.
OpenAI frontier models and Codex are now generally available on AWS, giving enterprises a new way to build on Amazon Bedrock with OpenAI through the security, compliance, and governance workflows they already use.
This is also the beginning of a broader expansion of OpenAI capabilities on AWS, including future availability for cybersecurity capabilities like Daybreak.
https://t.co/vMws0YU6Q3
Why AI Progress Suddenly Feels Real - my conversation with @yanndubs, who co-leads the Post-Training Frontiers team at @OpenAI
00:00 - Intro
01:30 - Why recent AI progress feels like a step function
04:13 - Model reliability & the emotional rollercoaster of shipping GPT-5.5
07:33 - How OpenAI structures vertical and horizontal teams
09:49 - Improving model efficiency and test-time compute
12:32 - Yann's journey from Switzerland to OpenAI
15:37 - Reasoning in 2026: Real-world utility vs verifiable rewards
18:34 - GPT-5.5 Thinking vs Pro: Scaling test-time compute
20:09 - How reasoning models become more efficient
23:23 - Pre-training scaling and overcoming the data wall
27:03 - Multimodal data, synthetic data, and embodied AI
31:05 - Demystifying mid-training and post-training
37:21 - Does RL create new capabilities in AI?
38:53 - The challenges and frontier of scaling RL
43:09 - Is building AI models a craft or a strict science
48:21 - How AI models generalize across different domains
54:18 - How reinforcement learning cures AI hallucinations
56:04 - Negative generalization and conflicting instructions
58:05 - Can RL scale to law, medicine, and the broader economy?
1:00:19 - The evaluation bottleneck and Model as a Judge
1:04:21 - Continuous AI progress & continual learning
1:08:49 - Will foundation models eat the agent harness
1:11:23 - Why startups should focus on the last mile of AI
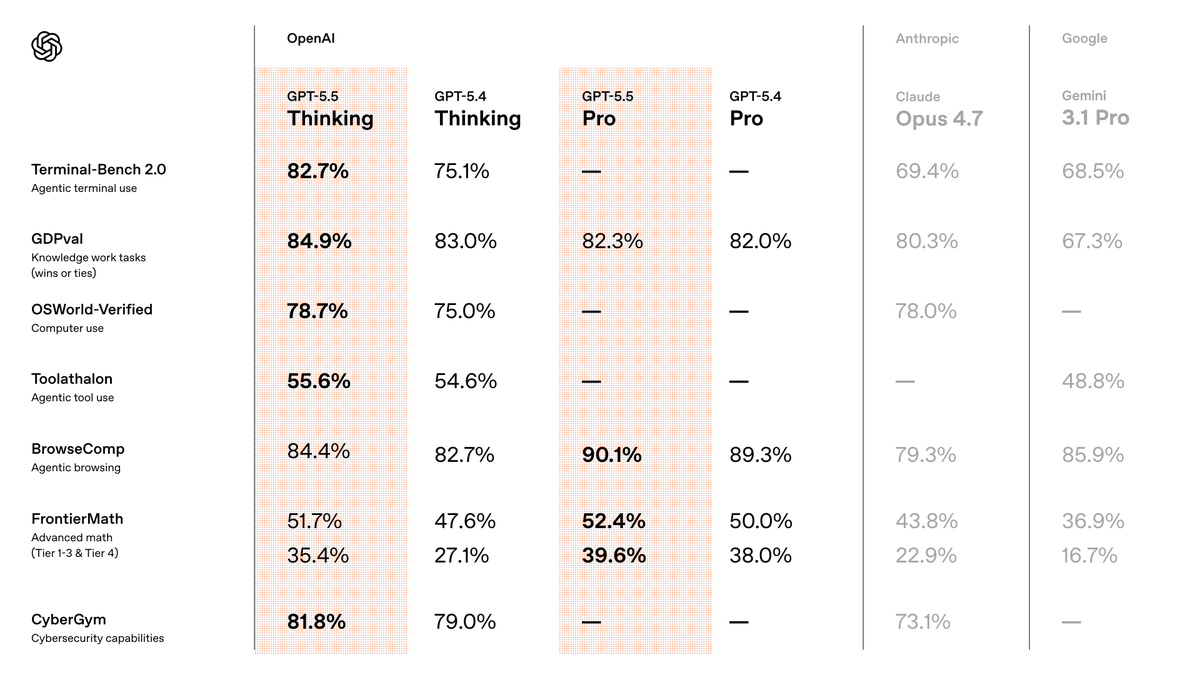
GPT-5.5 reaches state-of-the-art results across key evals for agentic coding, computer use, tool use, advanced math, and cybersecurity tasks.
82.7% on Terminal-Bench 2.0
78.7% on OSWorld-Verified
55.6% on Toolathlon
35.4% on FrontierMath Tier 4
81.8% on CyberGym
> in the course of days, of multiple runs, with the same tools at disposal, GPT 5.4 was able to made *all* the progresses, and Opus only minor things.
👏👏
During the last week I executed very long autonomous sessions of Claude Code Opus 4.6 and Codex GPT 5.4 (both at max thinking budget), in cloned directories (refreshed every time one was behind). I burned a lot of (flat rate, my OSS free account + my PRO account) of tokens...
GPT-5.4 Thinking and GPT-5.4 Pro are rolling out now in ChatGPT.
GPT-5.4 is also now available in the API and Codex.
GPT-5.4 brings our advances in reasoning, coding, and agentic workflows into one frontier model.
I know this is pretty well established at this point, but Codex 5.3 is a much more effective model than Opus 4.6. I went back and forth on both for a bit, but haven’t touched Opus at all now for a full week. First model to get me off of Opus… ever. Good job Codex team.