Consultora de #EstrategiaDigital y @cibervoluntario
Soy La Nieta de la Matilde | Curiosidad de Niña | Alma #Vintage
Always Learning | MKT | Creatividad | Vida
Habéis hecho viral mi tuit de anteayer sobre el sindiós del acceso a las historias clínicas entre comunidades autónomas. Gracias por visibilizarlo.
Por si ayudara a otros, comparto algunas ideas sobre salud, tecnología y derechos:
1️⃣ Muchos teléfonos tienen la opción de consignar datos de salud, accesibles en caso de emergencia sin necesidad de desbloquear el dispositivo.
Si llegas inconsciente a un centro médico, un sanitario podría así conocer tu nombre, edad, alergias, medicación, enfermedades, contacto de emergencia…
Igualmente, si encuentras a alguien indispuesto, esto puede darte pistas de qué hacer y a quién avisar.
También es útil si pierdes tu teléfono: quien lo encuentre puede saber así tu nombre y a qué número llamar para devolvértelo.
2️⃣ Puedes acceder a tu historial médico en línea, con certificado digital, a través del servicio de Historia Clínica Digital del Sistema Nacional de Salud (HCDSNS).
Desde ahí puedes consultar y descargar tu historia clínica en todos los servicios autonómicos de salud. Puedes descargar informes, resultados de pruebas diagnósticas, de laboratorio, de imagen, tu historial médico resumido en inglés…
3️⃣ Personalmente, llevo mi historia clínica completa, desde 1988, en el móvil¹. Toda la HCDSNS y otros documentos míos, de la sanidad privada, etcétera.
Cuando voy al médico, se lo ofrezco. Suele rechazarlo para consultarlo él en su ordenador, pero yo siempre encuentro los datos y documentos antes, y a menudo tengo más datos yo que él.
El médico alucina, pero creo que es bueno tenerlo.
4️⃣ Por lo que explicaba hace un par de días —y que muchos, incluso sanitarios, habéis confirmado— parece que a veces los médicos de un territorio no pueden acceder a los datos médicos de un paciente fuera del territorio habitual de este. O tienen grandes dificultades.
Eso es muy grave y hay un marco legal muy claro al respecto: el RGPD², la LAP³ y la LCCSNS⁴, que yo conozca.
Pero, por lo que sea, parece que aún no va, o va a pedales…
5️⃣ Tenéis derecho, como usuarios de la sanidad pública, a obtener copia de vuestra historia clínica. Muchos servicios autonómicos de salud tienen una «app» móvil o servicio digital para esto.
También tenéis derecho a conocer la identidad de todos los profesionales sanitarios que intervienen en vuestra asistencia.
6️⃣ Como pincelada de hacia dónde va el futuro: ya podemos correr modelos de IA en local y hacerles preguntas como «revisa mis analíticas de sangre de los últimos 10 años y dime qué ves», «dime cuándo me rompí la clavícula y qué ligamento me desgarré», «dime qué antibiótico me recetaron cuando pesqué aquella bronquitis», «dime si soy alérgico a esto que me han recetado»…
No reemplaza a un médico, claro, pero es cada vez más útil, y pronto será una herramienta más al alcance de casi todos.
7️⃣ Existe un Registro Nacional de Instrucciones Previas. Cualquiera pueda inscribir su voluntad en el supuesto de quedar gravemente incapacitado, en una situación grave e irreversible, sin poder expresar su voluntad…
Puedes dejar por escrito si deseas acortar tu vida para acortar una agonía, donar o recibir órganos, cuidados paliativos, etcétera. Revísalo en tu comunidad autónoma. Es un un trámite sencillo, aunque suele requerir cita previa y personarse.
¡Ojalá esto ayude a alguien!
___
¹ Cifrado, securizado y respaldado, claro. No hagas esto si no tienes los conocimientos para hacerlo de forma segura.
² Reglamento 2016/679 General de Protección de Datos.
³ Ley 41/2002, básica reguladora de la autonomía del paciente y de derechos y obligaciones en materia de información y documentación clínica.
⁴ Ley 16/2003, de Cohesión y Calidad del Sistema Nacional de Salud (SNS).
* 10 días en Málaga este verano (6-16 Julio)
* Alojamiento y desplazamiento gratis
* Formación en ciberseguridad
* Organiza la Universidad de Málaga, patrocina Google
no hay mucho que pensar 😅
https://t.co/bLOW3LefYy
🔴 I NEED YOUR ATTENTION
I've spent a month helping Miriam with her case of metastatic cancer and I want to share the methodology I've been using because it's completely replicable.
I think (with luck) this could be USEFUL TO OTHER PEOPLE with cancer (or any other illness).
The results we've gotten aren't a miracle, but we believe they're genuinely useful and could mean the difference in a literal life-or-death medical case.
Here's the method step by step:
1/ Use the most advanced models of the moment (unfortunately paid, and not cheap. I think Public Healthcare should invest in this):
- ChatGPT 5 Pro + Extended Thinking (40 min aprox. of thinking per call)
- Claude Opus 4.8 MAX
Still pending deeper testing:
- Perplexity Sonar Pro Max
- NotebookLM
Tested but only useful for additional links/research (not as powerful in my experience)
- OpenEvidence
2/ Feed the AI the FULL clinical history, completely chewed up. This sounds dumb but it's critical.
- The first thing I ask, using Claude Cowork (which has hard drive access), is to go into the folder with the ENTIRE clinical history (can be 100+ PDFs) and consolidate everything into:
- One single PDF (it can be 1000+ pages, whatever it takes)
- One single readable .txt or .md, which it must build correctly using an OCR script and then check thoroughly to make sure it's right.
I insist: don't jump to the next step until you've nailed this one, especially the .txt.
3/ Once you have the above, use this prompt along with the .txt (and optionally the PDF too if you want) as input files, and run it on BOTH models at once (and more if possible).
👉 This prompt is insanely complex/advanced: https://t.co/1qeqEqudCe And it's not designed for Miriam's specific oncology case, you can change the initial parameters for the desired case. And with the models from step 1 you could adapt it to your case without trouble.
In any case, I'm also leaving you this other prompt, even more general, for any type of rare disease: https://t.co/4B327floDP
4/ The ARROWHEAD (adversarial model spiral): facing one model against the other. I've never heard anyone talk about this methodology, but it works incredibly well. The feeling is like sharpening a stake until it gets a gleaming point.
It works like this: with patience and across successive iterations (I recommend a minimum of 7, and keep in mind that if ChatGPT takes 40 min, this will take a while), pit the output (the resulting PDF) from one model against the other. With a simple prompt like:
"Another committee of experts says this. What do you think? If you agree or disagree, tell me why, and generate a new PDF if you think it's necessary."
Then you feed that result back to the opposite model. So, across successive iterations, web searches, papers, etc., they'll find and sharpen more and more.
When to stop? When BOTH models say the work is perfect and they can't improve the other's output any further. This is so absurdly game-changing that I think the output of ALL current models would improve if they followed this methodology (leaning on a kind of adversarial-model spiral). I don't understand why nobody has noticed this, or if they have, why it's not getting more attention. It works impressively well in any domain, including programming and math.
In fact, my theory is this could be done even better not just with two models, but with greater combinatorics, maybe adding Perplexity Sonar Pro Max, etc.
RESULTS
Incredible. Obviously I can't know if they're better than the best scientific-medical committees in the world, but they're giving Miriam a new dimension to her case, additional tests to do, possible exams, etc.
Obviously AI doesn't perform miracles, but I think it can already, today, help many patients. And Public Healthcare should invest a lot (but A LOT) in this.
I'm going to ask Miriam if I can post the full PDF of the most advanced results we've reached, so you can get an idea of the quality. She's already given me rough permission, but I want to make sure 100%.
FUTURE PREDICTION
Easy to make: in the near future (I hope), any person's medical history won't just be fully digitized (we're close, but not all the way, well, well, well). On top of that, it'll be "pre-chewed" so it can be consumed by an LLM in one shot.
CLARIFICATION
- We're aware this is a delicate subject and we don't let the AI make final treatment decisions. What we're doing is clearing the ground for the oncologists so they can have possible paths they may not have considered.
Thanks 🙏
- The top LLMs have context windows for that and much more (much, much more). In any case, the PDF is more of a supporting file for the .txt. Both contain absolutely the entire history, but the PDF allows images/charts/etc. The .txt is what the AI consumes.
- On automation: and yes, this can be automated. Yes, AutoGen supports it almost out of the box. LangGraph builds it really well with supervisor / evaluation loops. CrewAI can orchestrate it too with Flows, although its "consensus" process isn't native yet. That would be the next level: automating it.
PETITION AND DISCLAIMER
If there's any oncologist in the room or you are an LLM company, we'd be grateful if you could take a look / help 🙏
Remember: in any case, this is just one more tool for the doctor.
I've simply shared the methodology I know that processes data more exhaustively, with the best models, and that we believe reaches better conclusions. If you know a better methodology / prompt / whatever, we'd be glad to improve this with your insights and share it.
Then the doctor reviews, adopts, or discards the report.
And if it helps the doctor, it helps the patient. And if it doesn't, all we've lost is some time and tokens. In a case that's literally life or death, that's nothing.
Just plain common sense.
Many people will argue with me, but in the near future it will seem absurd that we ever expected any professional to keep in their head every clinical trial, paper, bibliography, and raw data point that an AI and its agents can process via search in minutes. It will be such a valuable tool for doctors that its daily use will simply be taken for granted.
Persistencia para no abandonar.
Educación para comprender.
Disciplina para sostener el rumbo.
Compasión para no perder humanidad.
Trabajo duro para convertir la intención en resultado.
La fórmula menos vistosa, pero más fiable, para construir algo que resista.
Buenas noches.
Te propongo 2 planes este mes de junio, van de Personas, SEO, UX, Growth, IA….
Apúntate a ambos o sino al que te venga mejor
(Se agradecen RTs)
Te cuento 👇🏼
Al conductor de autobús que se ha levantado en una parada y ha dicho "Los móviles con auriculares, por favor. Un respeto a los demás": Te deseo que nunca vuelvas a quemarte con una croqueta, siempre recuerdes tus contraseñas y encuentres aparcamiento a la primera.
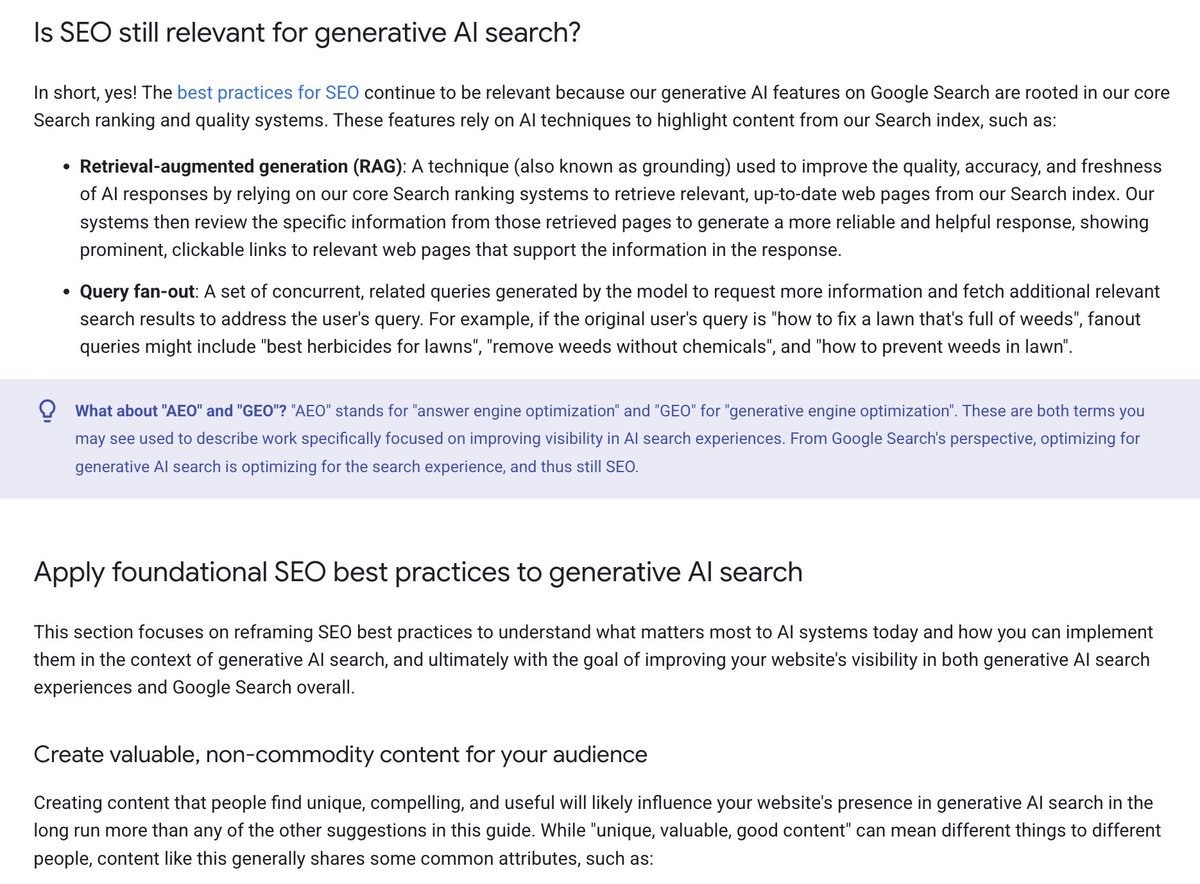
🚨 Google has published its official guidance on optimizing for generative AI experiences in Search, including AI Overviews and AI Mode 👇 Going through:
1. How SEO is still relevant for generative AI search:
The best practices for SEO continue to be relevant because their generative AI features on Google Search are rooted in our core Search ranking and quality systems.
2. How to Apply foundational SEO best practices to generative AI search:
** Creating valuable, non-commodity content for your audience: Providing a unique point of view, Creating non-commodity content that's helpful, reliable, and people-first, Organizing content in a way that helps your readers, adding high-quality images and video, focusing on what your users want, and avoid overdoing it.
** If you're using generative AI tools to assist in content creation, be sure that your work meets the standards of the Search Essentials and our spam policies.
** Building and maintain a clear technical structure: meeting the Search technical requirements, following crawling best practices, focusing on human readability and don't worry about perfect HTML code, if you're using JavaScript, be sure to follow JavaScript SEO best practices, providing a good page experience, reducing duplicate content.
3. Mythbusting generative AI search: what you don't need to do
Things you can ignore for Google Search:
** LLMS.txt files and other "special" markup
** "Chunking" content:
** Rewriting content just for AI systems
** Seeking inauthentic "mentions"
** Overfocusing on structured data
4. Explore agentic experiences
AI agents are autonomous systems that can perform tasks on behalf of people, such as booking a reservation or comparing product specifications, they can take many forms; for example, browser agents may access your website to gather the data they need to complete these tasks, such as analyzing visual renderings (like screenshots), inspecting the DOM structure, and interpreting the accessibility tree.
Check out the available agentic experiences and review the guide to agent-friendly website best practices recently published here: web(.)dev/articles/ai-agent-site-ux
Read the full Google guide here: developers(.)google(.)com/search/docs/fundamentals/ai-optimization-guide
PS: This is by far the most in-depth, actionable guide that Google has published so far for AI search, tackling some of the major misunderstandings and myths SEOs face in the day to day... thank you @googlesearchc team 🙌
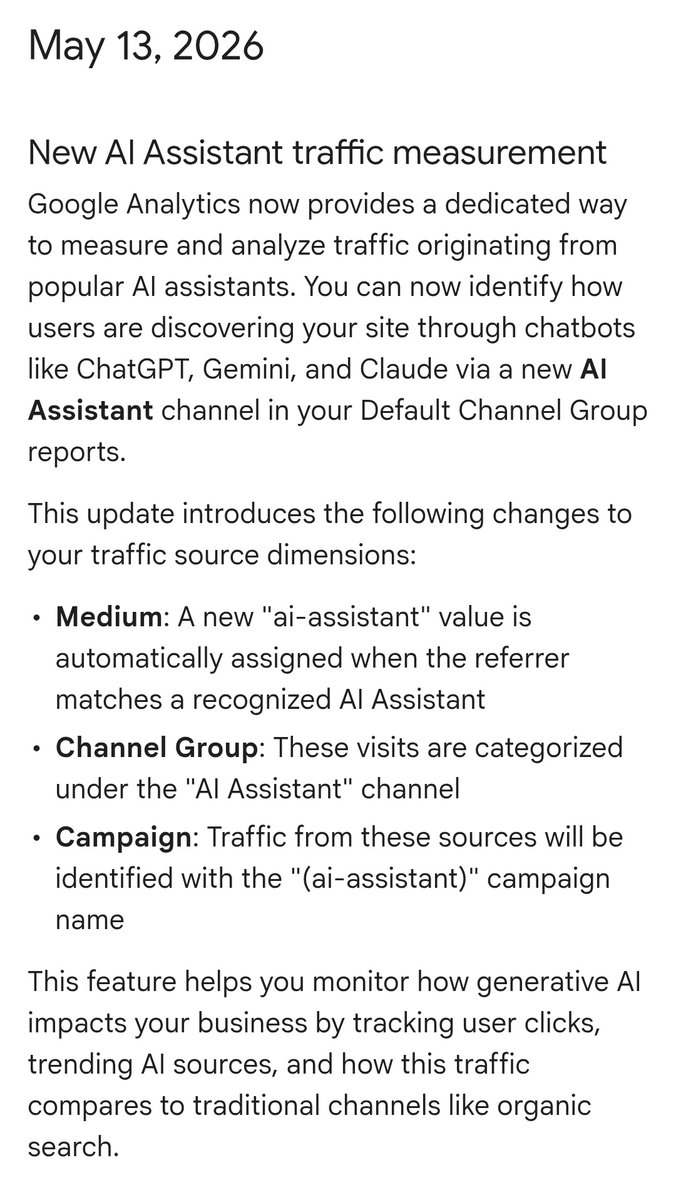
Google Analytics 4 indicará a partir de ahora el tráfico web que venga de la IA.
Google ha anunciado que la herramienta cuenta a partir de hoy con un nuevo canal para ello: 'AI Assistant'.
Así, desde ya será mucho más sencillo poder ver (y reportar) cuánto tráfico envía a tu web CharGPT, Gemini o Claude.
Puedes ver el anuncio en:
https://t.co/1w3Y08fTFv
Wishing a Happy Birthday to Sir David Attenborough. Thank you for the knowledge, passion, and hope you’ve passed on to all of us.
Celebrate 100 years of Sir David Attenborough with Ocean with David Attenborough on @DisneyPlus and @hulu
🌟 La Datolada 2026 - El Plan Completo
Un finde para aprender, debatir, reír, conectar y recordar por qué hacemos todo esto y por qué nos juntamos.
La magia de La Previa, el Banquete y la Gran Cena para quienes estén en presencial y con streaming gratuito para el resto.
Una nube gris oscurece el sector tecnológico.
Hay demasiado ruido, demasiados titulares populistas y demasiado MIEDO. Mucha gente se pregunta si su trabajo seguirá existiendo el año que viene.
Quiero que la @tarugoconf sea un antídoto contra eso: un lugar para distinguir la señal del ruido, entender lo que viene y salir de allí con más criterio, más contexto y, sobre todo, más ganas de seguir haciendo cosas.
Por eso, la próxima #TRG26 pivotará completamente alrededor de la #IA.
Pero ni desde el negacionismo ni desde el hype.
Ni desde el «esto no vale para nada», ni tampoco desde el «los programadores están obsoletos».
Hablaremos de IA desde el pragmatismo, no desde el fanatismo.
No para conocer herramientas que quizá queden obsoletas en pocos meses, sino para entender las reglas del juego: quién es quién, cómo funciona, cómo evoluciona, qué modelo de negocio la sostiene, qué límites técnicos tiene, qué retos legales abre y cómo cambia nuestra forma de trabajar.
Porque si no conocemos las reglas del juego, solo podremos ganar por pura suerte. Y mi objetivo es que quienes vengan a la TRG salgan de la conferencia con muchas, MUCHAS más posibilidades de ganar la partida.
Quedan 179 días para el evento y, desde hoy, intentaré informaros diariamente de novedades y avances.
Comenzamos 😘
📊 Fundación Cibervoluntarios presenta el estudio "Apropiación de la Tecnología en niños, niñas y adolescentes" #cibervoluntarios 👇🏼
https://t.co/rVyMAw4NXP
Acabo de publicar la comparativa salarial de 11 empresas de tecnología en España 👀💁♂️
Vamos a probar si los artículos de Tw mejoran la distribución ^__^
Si lo queréis leer en el blog de @getmanfred, aquí: https://t.co/zo5let3HCh
Dadle hamor 💪