Introducing Prism, a free workspace for scientists to write and collaborate on research, powered by GPT-5.2.
Available today to anyone with a ChatGPT personal account: https://t.co/9mTLAbxPdH
Introducing GPT-5.5
A new class of intelligence for real work and powering agents, built to understand complex goals, use tools, check its work, and carry more tasks through to completion. It marks a new way of getting computer work done.
Now available in ChatGPT and Codex.
Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.
Codex for (almost) everything.
It can now use apps on your Mac, connect to more of your tools, create images, learn from previous actions, remember how you like to work, and take on ongoing and repeatable tasks.
Say hello to Gemini 3.1 Flash Live. 🗣️
Our latest audio model delivers more natural conversations with improved function calling – making it more useful and informed. Here’s what’s new 🧵
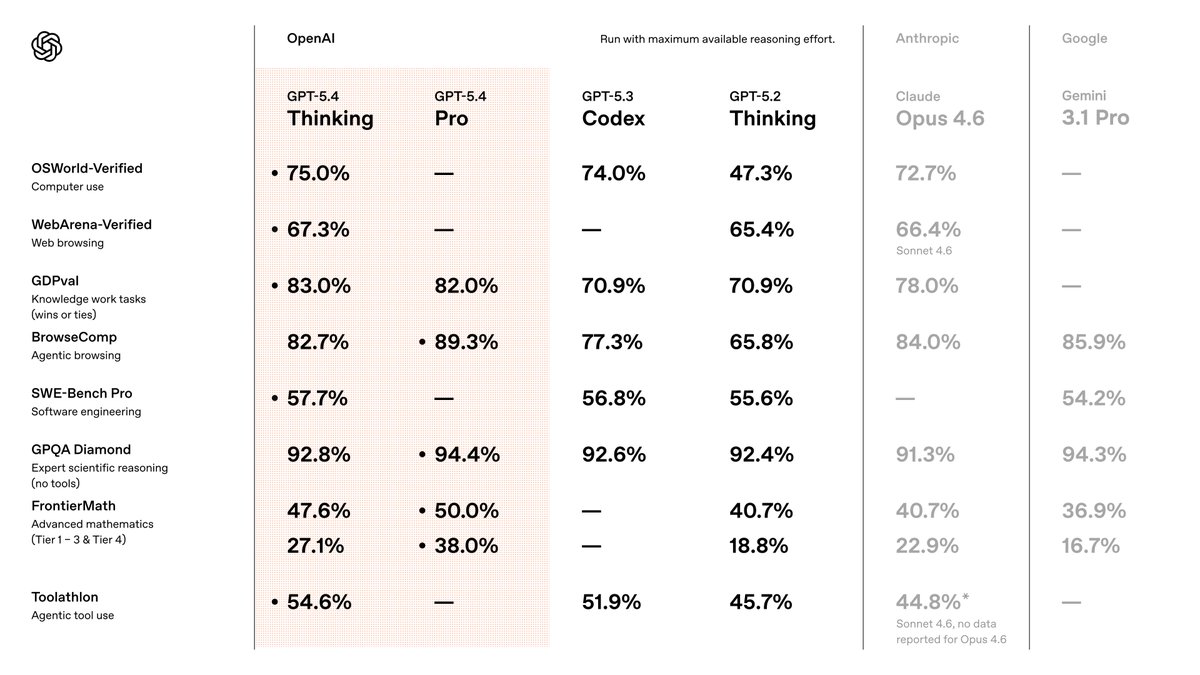
GPT-5.4 is launching, available now in the API and Codex and rolling out over the course of the day in ChatGPT.
It's much better at knowledge work and web search, and it has native computer use capabilities.
You can steer it mid-response, and it supports 1m tokens of context.
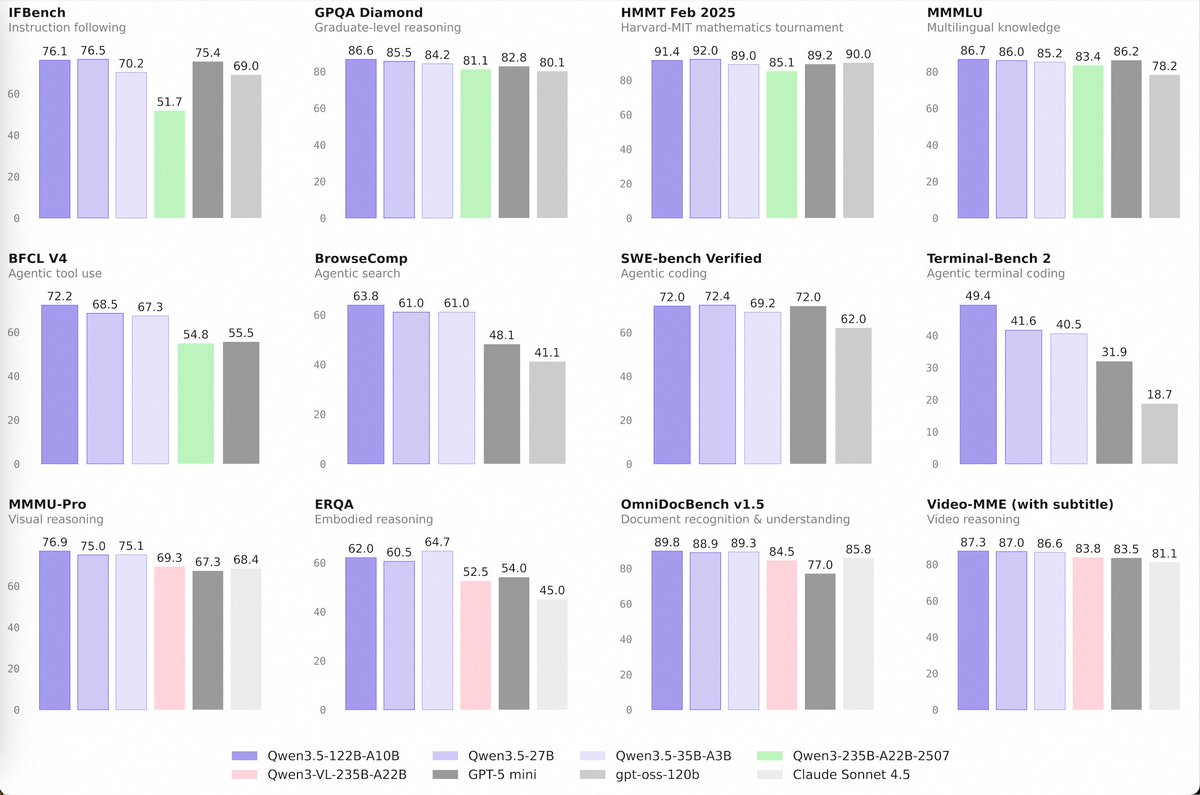
🚀 Introducing the Qwen 3.5 Medium Model Series
Qwen3.5-Flash · Qwen3.5-35B-A3B · Qwen3.5-122B-A10B · Qwen3.5-27B
✨ More intelligence, less compute.
• Qwen3.5-35B-A3B now surpasses Qwen3-235B-A22B-2507 and Qwen3-VL-235B-A22B — a reminder that better architecture, data quality, and RL can move intelligence forward, not just bigger parameter counts.
• Qwen3.5-122B-A10B and 27B continue narrowing the gap between medium-sized and frontier models — especially in more complex agent scenarios.
• Qwen3.5-Flash is the hosted production version aligned with 35B-A3B, featuring:
– 1M context length by default
– Official built-in tools
🔗 Hugging Face: https://t.co/wFMdX5pDjU
🔗 ModelScope: https://t.co/9NGXcIdCWI
🔗 Qwen3.5-Flash API: https://t.co/82ESSpaqAF
Try in Qwen Chat 👇
Flash: https://t.co/UkTL3JZxIK
27B: https://t.co/haKxG4lETy
35B-A3B: https://t.co/Oc1lYSTbwh
122B-A10B: https://t.co/hBMODXmh1o
Would love to hear what you build with it.
🚀 Qwen3.5-397B-A17B is here: The first open-weight model in the Qwen3.5 series.
🖼️Native multimodal. Trained for real-world agents.
✨Powered by hybrid linear attention + sparse MoE and large-scale RL environment scaling.
⚡8.6x–19.0x decoding throughput vs Qwen3-Max
🌍201 languages & dialects
📜Apache2.0 licensed
🔗Dive in:
GitHub: https://t.co/NzNdS9joAT
Chat: https://t.co/bg4tAU0Rhw
API:https://t.co/YiiyKTnHoU
Qwen Code: https://t.co/qqwj5nAger
Hugging Face: https://t.co/wFMdX5p5um
ModelScope: https://t.co/9NGXcId57a
blog: https://t.co/AW8UQStXaL