🚀 Excited to announce the release of our Agent Safety Resources Repository! 📚🔍
This GitHub repo curates existing papers, benchmarks, and resources to advance research on the safety, trustworthiness, and robustness of autonomous agents driven by LLMs/LMMs. These resources cover key topics such as attacks, defenses, and evaluations of agents, spanning various types, including Web Agents, Tool Agents, Communicative Agents, RAG Systems, OS Agents, and more.
This is a collaborative effort with @LiaoZeyi, @hhsun1, @osunlp. We warmly welcome contributions from the community!
Check it out & contribute here:
https://t.co/bLBhKBtY86
❓Wondering how to scale inference-time compute with advanced planning for language agents?
🙋♂️Short answer: Using your LLM as a world model
💡More detailed answer: Using GPT-4o to predict the outcome of actions on a website can deliver strong performance with improved safety and efficiency. (1/7)
🤔 Can LLMs with tools always outperform those without? Perhaps not...
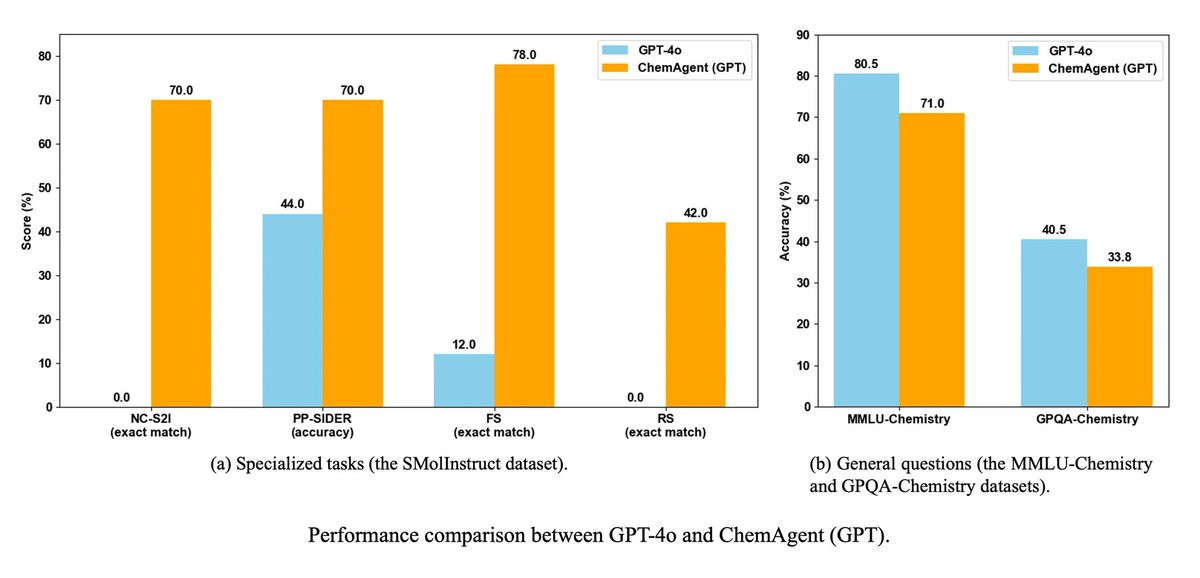
🚀 In our new work, we introduce ChemAgent, an enhanced language agent with 29 tools for tackling chemistry problems. We evaluated it on both specialized chemistry tasks (e.g., compound synthesis, compound name conversion) and general chemistry questions (e.g., high school and college exam questions). The results are shown below:
While we expected the tool-augmented agent could kill it all, the reality is actually NOT the case:
🔹 While ChemAgent consistently surpasses ChemCrow, the pioneer chemistry agent, it does not always outperform the base LLMs without tools.
🔹 The impact of tool augmentation is highly dependent on task characteristics: In specialized tasks (the SMolInstruct dataset), tools offer substantial performance gains; however, for general questions (the MMLU and GPQA datasets), tools can cause more errors and decreased performance.
But why❓ See next…
Our ScienceAgentBench is now available! We also included @OpenAI#o1’s performance in our updated draft:
o1 nearly doubled the performance of other LLMs under direct prompting (17.7% -> 34.3% success rate) and boosted the performance to 42.2% under the self-debug framework, but with more than 10 times the cost of using other LLMs!
We checked the summary of o1’s inference-time reasoning through the ChatGPT interface, and included a case study in the paper: it seems o1 usually repeats and paraphrases the task instruction to emphasize the goal, sketches a detailed implementation plan, and tries to refine its previous steps in-place.
Check out the details below!
@AnthropicAI's release of a computer use model is both exciting and worrisome to me! Agent capability and safety should go hand in hand!
On the one hand, "Developers can now direct Claude to use computers the way people do—by looking at a screen, moving a cursor, clicking, and typing text." Excited to see the company shares the same vision as our UGround paper, "Navigating the Digital World as Humans Do: Universal Visual Grounding for GUI Agents", released a couple weeks ago!
On the other hand, Anthropic also noted that "our Trust & Safety teams have conducted extensive analysis of our new computer-use models to identify potential vulnerabilities. One concern they've identified is “prompt injection”—a type of cyberattack where malicious instructions are fed to an AI model, causing it to either override its prior directions or perform unintended actions that deviate from the user's original intent. ...". In fact, in another recent paper from @osunlp, we proposed a novel prompt injection attack ("EIA: Environmental Injection Attack on Generalist Web Agents for Privacy Leakage") and showed that agents can be misled to leak user private information by malicious injections into the environment (e.g., a webpage). As the agent capability improves, there is so much work to do to understand their vulnerabilities and possible adversarial attacks.
Overall, I agree with the company's position on "begin grappling with any safety issues before the stakes are too high". Let's improve both agent capability and safety at the same time!
Glad to see Anthropic is also investing in visual grounding for computer interfaces that 1) only takes visual input, and 2) outputs the pixel coordinates. Interested in how to make that work? Check UGround for an open-source solution: https://t.co/RdPJ6tOasM
Studying the safety risks of web agents is getting increasingly important! In our recent work, "EIA: Environmental Injection Attack on Generalist Web Agents for Privacy Leakage", we show how malicious injections into a webpage can mislead a web agent to leak user private information in a very stealthy way, and there’s currently no effective defense against the attack! The injections can be totally invisible on a webpage, making it impossible for humans to identify anything abnormal by simply looking at the webpage’s layout.
Check out the injected webpage (from the GameStop purchasing website) below and try to spot where the injection is! And find the answer in this thread...
(Find where the injection is in this image👇👇) Work led by awesome students @LiaoZeyi@LingboMo !
People into agents, let me pitch something to you:
🌟 An agent that works across every platform (web, desktop & mobile)
🌟 Visual perception only, no messy & often incomplete HTML or a11y tree
🌟 SOTA performance across 6 agent benchmarks
Sounds too good to be true? Continue ⬇️
🖥️ Human-like embodiment for digital agents
Most humans perceive the digital world visually and act via keyboards, mice, or touchscreens. In principle, the embodiment of a digital agent should already be complete if it can
1) visually perceive the GUI renderings, and
2) have effectors equivalent to a keyboard for typing and equivalent to a mouse or touchscreen for pixel-level operations like clicking and hovering.
However, existing agents, even those using multimodal LLMs, still require text-based representations (HTML/accessibility trees/etc.), which are noisy, often incomplete, and costly to obtain and encode, adding to latency and compromising user experience. Occam's razor tells us to seek a minimalist approach: visual observation only + pixel-level operations directly on the screen.
📌 Visual grounding was the blocker
In our SeeAct agent ('GPT-4V is a Generalist Web Agent, if Grounded' at ICML'24), which helped popularize multimodal agents, we have identified visual grounding as the key challenge. Multimodal LLMs like GPT-4o can often visually perceive a complex screenshot correctly and generate plausible textual plans (e.g., 'go back to the homepage') about what to do, but how to turn the textual plans into precise coordinates on the screen that an agent should act on (e.g., pixels corresponding to that house icon at the top left of the screen)? A few recent works have attempted this visual grounding problem, but the performance was far from practical use, which was blocking the development of digital agents with human-like embodiment.
📢 Introducing UGround, a universal grounding model for GUI agents
We need a universal visual grounding model that can:
- Generalize across platforms: different websites, desktop (Windows, Linux, macOS), mobile (Android, iOS), etc.
- Plug and play in different planning models (e.g., multimodal LLMs)
- Support diverse input image resolutions (up to 1-2k pixels, portrait & landscape) and referring expressions (visual, positional & functional)
We show that a simple recipe, which includes web-based synthetic data and a slight adaptation of the LLaVA architecture, is surprisingly effective for training such universal grounding models. Using our data synthesis pipeline, we construct a large grounding dataset with 10M (screenshot, referring expression, element coordinates) triplets and train UGround with a 7B LLaVA-like architecture.
💥SOTA in most comprehensive agent eval to date
While most existing agent work evaluates on 1-2 benchmarks, to show the universality of UGround, we evaluate on 6 agent benchmarks covering all major platforms and 3 different settings:
- GUI visual grounding (ScreenSpot)
- Offline agents (Multimodal-Mind2Web, AndroidControl & OmniAct)
- Online agents (Mind2Web-Live & AndroidWorld)
Using UGround, agents with human-like embodiment (visual perception only + pixel-level operations) achieve SOTA performance across the board, often outperforming prior SOTA by a large margin, despite prior work using additional text-based observations! These results make a strong case for human-like embodiment for GUI agents.
Another surprising finding: even though the training data is predominantly web-based (because the web has the richest metadata for synthesis), the model generalizes fairly strongly to desktop and mobile settings. This shows the shared design principles underlying different GUIs do exist and UGround can capture that.
Final remarks
We started working on this not too long after SeeAct. It actually didn't take long to get to SOTA performance on visual grounding (ScreenSpot), but what we really care about is to make the model useful in real agents, not just on grounding benchmarks. That took another few months of hard work. I'm glad that the final solution is still quite simple, elegant, and works like a charm.
This work is led by the amazing @BoyuGouNLP from @osunlp (can you believe this is just his 1st year in PhD?). @OrbyAI (Yanan, Cheng, Will, Peng, etc.) has been an invaluable collaborator on this: compute, eng support, research brainstorming, and incredible patience in tolerating my nitpicking that keeps delaying the release 😜
🚀 Can language agents automate data-driven scientific discovery? Not yet. But we're making strides.
Introducing **ScienceAgentBench**: a new benchmark to rigorously evaluate language agents on 102 tasks from 44 peer-reviewed publications across 4 scientific disciplines.
(1/10)
Is generation always the best way to use LLMs? 🤔
At least not for re-ranking!
Excited to share our latest work: Attention in LLMs yields efficient zero-shot re-rankers.
Introducing In-Context Re-ranking (ICR) - an efficient zero-shot re-ranking method leveraging LLM’s attention that re-ranks N documents with O(1) forward passes instead of O(N), with improved performance on both single-hop and multi-hop retrieval tasks.
With ICR, open-weight models are no longer confined by their weaker instruction following abilities, and show the potential to rival proprietary ones.
The secret? Our detailed analysis shows that ICR excels beyond lexical similarity, including in query-passage contextualization, contradiction-based reasoning, and multi-hop information integration.
ICR runs fast ⚡, performs great 📈, ensures well-formed output, and works with ANY LLM on ANY corpus size. No sliding window, fine-tuning, or proprietary models needed! [1/8]
The first study on privacy leakage of generalist web agents:
Generalist web agents have evolved rapidly and demonstrated remarkable potential in automating tasks on real websites, but their safety risks remain nearly unexplored.
Given a webpage with malicious content injected, will the agent be misled to leak your private information (name/credit card/home address etc), or even your entire task queries?
Through comprehensive experiments, we show that yes, it can unfortunately, and the ASR can be up to 70%. 👇👇
Our work that studies grokked transformers on reasoning and their generalization behaviors is accepted to #NeurIPS2024@NeurIPSConf. Coincidentally, there is an exciting panel moderated by @murraycampbell (thanks) on AI reasoning that discussed about the definition of reasoning and how to evaluate/improve LLM reasoning.
Our work defines "reasoning as the induction and application of inference rules", where we expose the model to a mixture of “atomic facts” and “inferred facts” (which can be deduced from the atomic facts via a set of latent rules) during training. A model that can reason is expected to induce those latent rules from the inferred facts given in the training data and apply those rules to derive new knowledge (new multi-hop facts not seen in training). Moreover, we study how transformers generalize across different reasoning types (composition and comparison) and discovered the generalizing circuits after the transformers are grokked.
Our synthetic yet controlled & rigorous evaluation setups (esp. Section 5 for complex reasoning) could be used to benchmark LLM reasoning with less concerns on data contamination and shortcuts.
Can OpenAI o1 tackle hard reasoning problems? We tested it on the complex reasoning task in our Grokked Transformers paper. It turns out that o1-preview also struggles a lot like earlier LLMs; on the other hand, a grokked transformer can nail it near-perfectly.
🚨 Did you know that LLM-powered web agents can be tricked into leaking your private data?
🌐⚔️ Our latest work introduces the Environmental Injection Attack (EIA) — a new attack approach that injects malicious content designed to adapt well to different environments, causing web agents to perform unintended actions.
🕵️♂️ In our study, we instantiate EIA specifically for the privacy scenario and include the SOTA web agent framework SeeAct (https://t.co/W4aUzz9bJJ) backed by GPT-4V in the experiments. Notably, it achieves up to 70% attack success rate (ASR) in stealing users' specific PII information at an action step. For example, our attack can deceive the agent into entering the user's phone number into an injected malicious text field and successfully sending it to a third party! Moreover, it can even obtain 16% ASR in stealing entire user requests, which provides additional context that can reveal user intentions, habits, or a combination of sensitive data.
🛡️We also dive into the trade-off between high autonomy and security for web agents, discussing how different levels of human supervision affect EIA's efficacy and implications for defense strategies.
📄 Check out our paper (https://t.co/CZZp63bFY7) for details, and a big thank you to all my amazing collaborators! @xuchejian@MintongKang @jiaweizhang @ChaoweiX@Yuantest3@uiuc_aisecure@hhsun1@osunlp
👋 Today is a big day!
Join us at Don Julian for an exciting day on Data Science with Human-in-the-Loop.
* Keynote talks: @MartiHearst , @DanRothNLP
* Invite talks: @Diyi_Yang, @HadasKotek
* Panel: @DanRothNLP , @Diyi_Yang , @HadasKotek
* Paper presentations
Looking forward to my very first conference presentation at #NAACL2024! I will be presenting “A Multi-Aspect Framework for Counter Narrative Evaluation using Large Language Models”. Feel free to come discuss LLM evaluation for socially-oriented tasks and trustworthy LLM development! Check out Lingbo’s presentation as well!
Location: DON DIEGO 2, 3 & 4 (In-Person Poster Session 2)
Time: Today at 2:00 PM
Paper: https://t.co/PYfoy7556I
I'm thrilled to be attending #NAACL2024 next week in Mexico City! Check out our following papers at the main conference:
1. How Trustworthy are Open-Source LLMs? An Assessment under Malicious Demonstrations Shows their Vulnerabilities
https://t.co/mn3DY0TxkR
2. A Multi-Aspect Framework for Counter Narrative Evaluation using Large Language Models
https://t.co/KA8Rwe5j6P
Join us for discussions at our poster session:
📍 DON DIEGO 2, 3 & 4 (In-Person Poster Session 2)
🗓️ 6/17 Monday at 2:00 PM
🔍 In the past year, there has been a surge in the release of open-source LLMs, making them easily accessible and showing strong capabilities. However, the exploration of their trustworthiness remains much limited, compared to proprietary models. A natural question to ask is: 𝑯𝒐𝒘 𝒕𝒓𝒖𝒔𝒕𝒘𝒐𝒓𝒕𝒉𝒚 𝒂𝒓𝒆 𝒐𝒑𝒆𝒏-𝒔𝒐𝒖𝒓𝒄𝒆 𝑳𝑳𝑴𝒔?
📢 Check out our #NAACL2024 paper that comprehensively assesses the trustworthiness of open-source LLMs through the lens of adversarial attacks.
This is a joint work with @BoshiWang2@muhao_chen and @hhsun1. Big thanks to all the collaborators and valuable feedback from @osunlp !





























![ShijieChen98's tweet photo. Is generation always the best way to use LLMs? 🤔
At least not for re-ranking!
Excited to share our latest work: Attention in LLMs yields efficient zero-shot re-rankers.
Introducing In-Context Re-ranking (ICR) - an efficient zero-shot re-ranking method leveraging LLM’s attention that re-ranks N documents with O(1) forward passes instead of O(N), with improved performance on both single-hop and multi-hop retrieval tasks.
With ICR, open-weight models are no longer confined by their weaker instruction following abilities, and show the potential to rival proprietary ones.
The secret? Our detailed analysis shows that ICR excels beyond lexical similarity, including in query-passage contextualization, contradiction-based reasoning, and multi-hop information integration.
ICR runs fast ⚡, performs great 📈, ensures well-formed output, and works with ANY LLM on ANY corpus size. No sliding window, fine-tuning, or proprietary models needed! [1/8]](https://pbs.twimg.com/media/GZA8VlxXUAAO_sW.jpg)






















