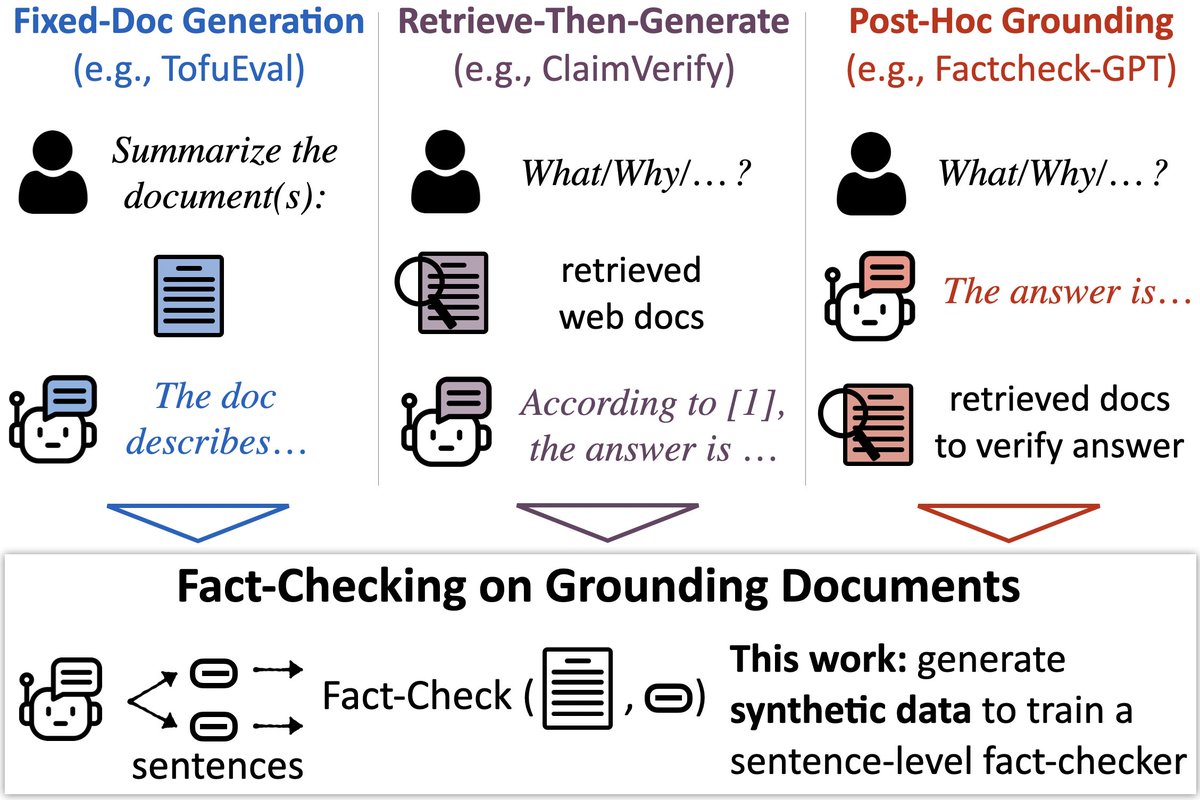
🔎📄New model & benchmark to check LLMs’ output against docs (e.g., fact-check RAG)
🕵️ MiniCheck: a model w/GPT-4 accuracy @ 400x cheaper
📚LLM-AggreFact: collects 10 human-labeled datasets of errors in model outputs
https://t.co/oFTS68mQOL
w/ @PhilippeLaban, @gregd_nlp 🧵
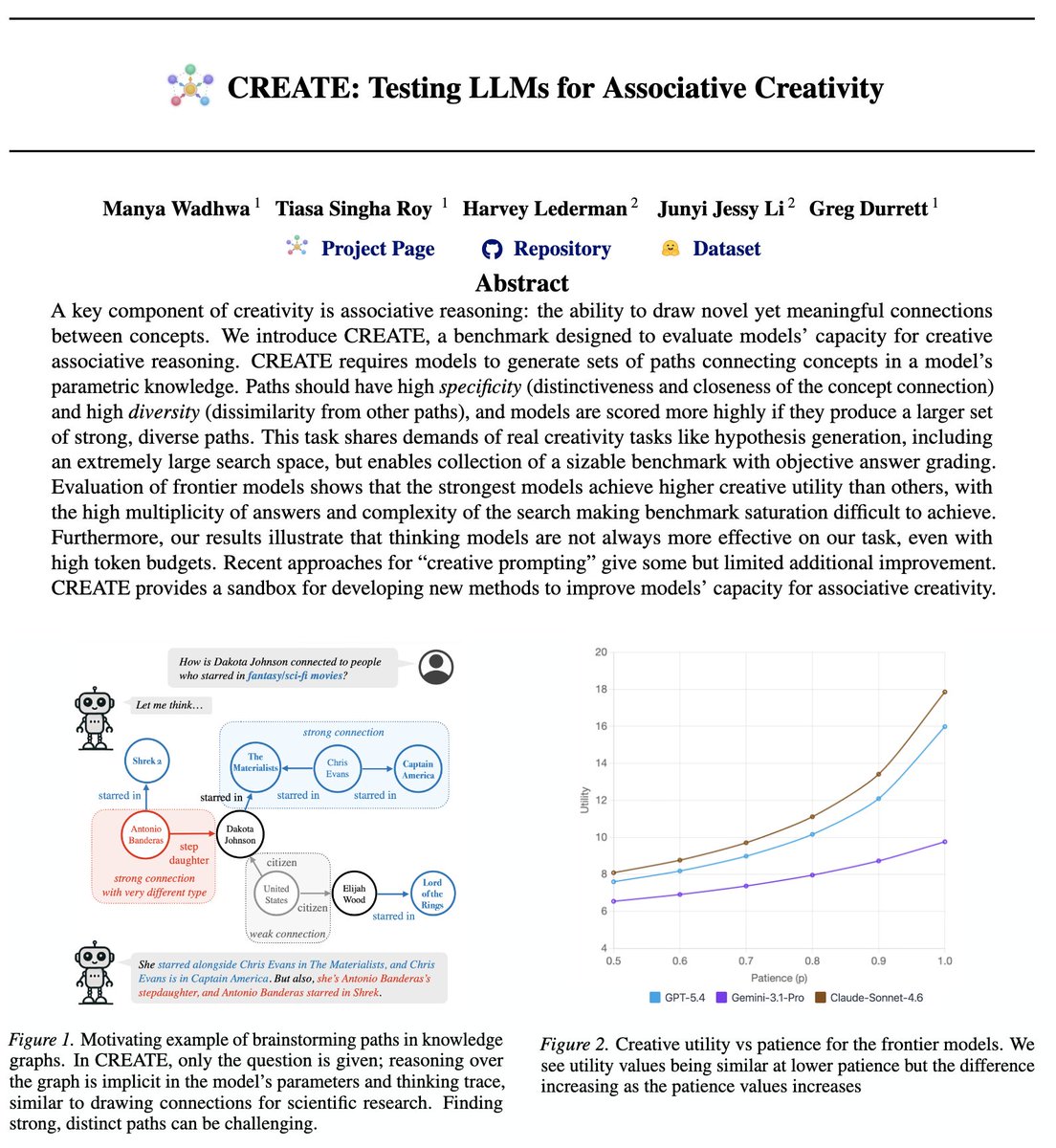
Check out Manya's benchmark for LLM creativity! Inspired by work on creativity in graphs (@AdtRaghunathan's "roll the dice" paper), CREATE isolates testing of creative insights for discovery. Future: understand how LLMs derive insights & how they can be better creative partners!
⚛️ Introducing CREATE, a benchmark for creative associative reasoning in LLMs.
Making novel, meaningful connections is key for scientific & creative works.
We objectively measure how well LLMs can do this. 🧵👇
Agents interact with environments to gather information. But exploration can be expensive.
Tool use, retrieval, and user interaction carry latency or monetary cost.
Calibrate-Then-Act allows LLM agents to balance exploration with cost:
📐 Estimate uncertainty about the environment
💭 Reason about cost-uncertainty tradeoffs
⚙️ Act accordingly
I'm at NeurIPS until Friday! This morning, catch:
@LiyanTang4 presenting ChartMuseum, testing if VLMs can do visual reasoning over charts
@sebajoed presenting AstroVisBench, testing if coding LLMs can work with real astro data workflows
& link in thread if you want to meet!
📢 Postdoc position 📢
I’m recruiting a postdoc for my lab at NYU! Topics include LM reasoning, creativity, limitations of scaling, AI for science, & more! Apply by Feb 1.
(Different from NYU Faculty Fellows, which are also great but less connected to my lab.)
Link in 🧵
Our paper "ChartMuseum 🖼️" is now accepted to #NeurIPS2025 Datasets and Benchmarks Track!
Even the latest models, such as GPT-5 and Gemini-2.5-Pro, still cannot do well on challenging 📉chart understanding questions , especially on those that involve visual reasoning 👀!
Introducing ChartMuseum🖼️, testing visual reasoning with diverse real-world charts!
✍🏻Entirely human-written questions by 13 CS researchers
👀Emphasis on visual reasoning – hard to be verbalized via text CoTs
📉Humans reach 93% but 63% from Gemini-2.5-Pro & 38% from Qwen2.5-72B
📢I'm joining NYU (Courant CS + Center for Data Science) starting this fall!
I’m excited to connect with new NYU colleagues and keep working on LLM reasoning, reliability, coding, creativity, and more!
I’m also looking to build connections in the NYC area more broadly. Please reach out if you're interested in chatting!
This move comes after 8 years working with incredible students and collaborators at UT Austin. Thank you to everyone who supported me in my first academic appointment; I look forward to continuing our collaborations but I will miss you! (and the breakfast tacos!)
LLMs trained to memorize new facts can’t use those facts well.🤔
We apply a hypernetwork to ✏️edit✏️ the gradients for fact propagation, improving accuracy by 2x on a challenging subset of RippleEdit!💡
Our approach, PropMEND, extends MEND with a new objective for propagation.
🤔 Recent mech interp work showed that retrieval heads can explain some long-context behavior. But can we use this insight for retrieval?
📣 Introducing QRHeads (query-focused retrieval heads) that enhance retrieval
Main contributions:
🔍 Better head detection: we find a different and more useful set of heads vs original retrieval head
📊Practical utility: a general-purpose retriever for long-context reasoning and re-ranking
Solving complex problems with CoT requires combining different skills.
We can do this by:
🧩Modify the CoT data format to be “composable” with other skills
🔥Train models on each skill
📌Combine those models
Lead to better 0-shot reasoning on tasks involving skill composition!
Check out ChartMuseum from @LiyanTang4@_grace_kim and many other collaborators from UT!
Charts questions take us beyond current benchmarks for math/multi-hop QA/etc., which CoT is very good at, to *visual reasoning*, which is hard to express with text CoT!
Introducing ChartMuseum🖼️, testing visual reasoning with diverse real-world charts!
✍🏻Entirely human-written questions by 13 CS researchers
👀Emphasis on visual reasoning – hard to be verbalized via text CoTs
📉Humans reach 93% but 63% from Gemini-2.5-Pro & 38% from Qwen2.5-72B
🆕paper: LLMs Get Lost in Multi-Turn Conversation
In real life, people don’t speak in perfect prompts.
So we simulate multi-turn conversations — less lab-like, more like real use.
We find that LLMs get lost in conversation.
👀What does that mean? 🧵1/N
📄https://t.co/xt2EfGRh7e
🚀Introducing CRUST-Bench, a dataset for C-to-Rust transpilation for full codebases 🛠️
A dataset of 100 real-world C repositories across various domains, each paired with:
🦀 Handwritten safe Rust interfaces.
🧪 Rust test cases to validate correctness.
🧵[1/6]


















![AnirudhKhatry's tweet photo. 🚀Introducing CRUST-Bench, a dataset for C-to-Rust transpilation for full codebases 🛠️
A dataset of 100 real-world C repositories across various domains, each paired with:
🦀 Handwritten safe Rust interfaces.
🧪 Rust test cases to validate correctness.
🧵[1/6] https://t.co/HR0iSmo9EL](https://pbs.twimg.com/media/GpO9WCJXMAAstQm.jpg)















![AnirudhKhatry's tweet photo. 🚀Introducing CRUST-Bench, a dataset for C-to-Rust transpilation for full codebases 🛠️
A dataset of 100 real-world C repositories across various domains, each paired with:
🦀 Handwritten safe Rust interfaces.
🧪 Rust test cases to validate correctness.
🧵[1/6] https://t.co/HR0iSmo9EL](https://pbs.twimg.com/media/GpO9WCKWQAALjAb.png)






























