❤️New Preprint!
Here within charts the directions of my next era of research: Multi-Agent Social Systems.
Link: https://t.co/Wl3kcujYVr
Current agentic AI systems are designed for optimization. But what is also important is the agent-agent/ agent-human interactions, which collectively results in emergent population-level behavior.
I argue that agentic AI systems should be designed with social theory as a structural prior. Social theory's core constructs like role differentiation and co-evolution specify agents collective behavior, perceptions and actions.
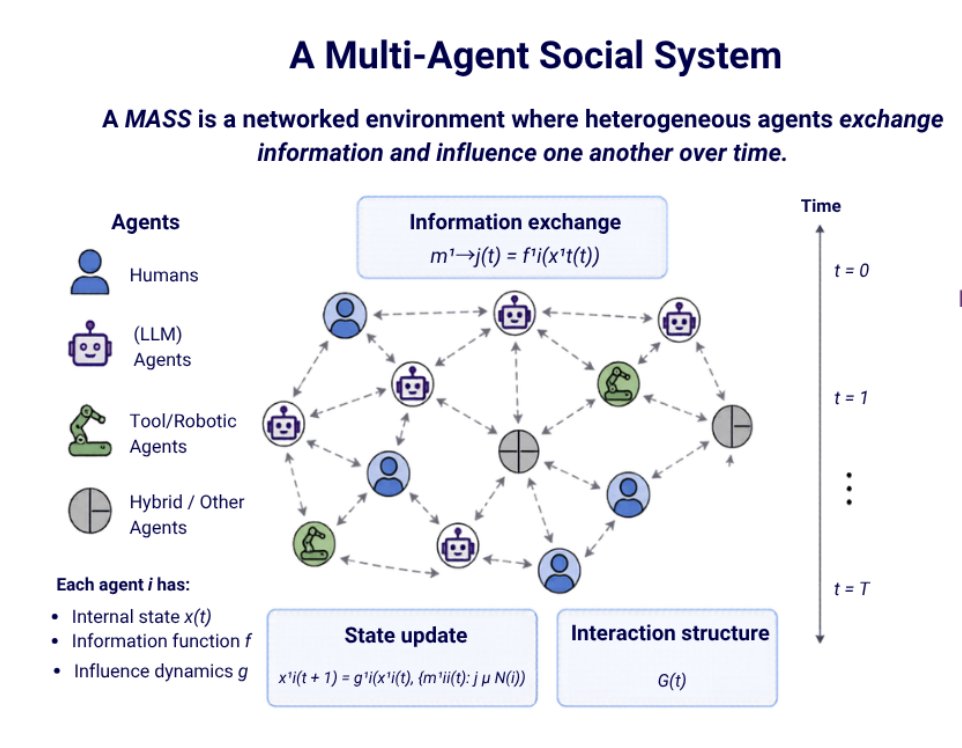
Formally, I define a Multi-Agent Social System (MASS) as networked environments where heterogeneous agents exchange information and influence each other over time. An MASS has: (1) information exchange function, (2) influence dynamics function and (3) networked interaction structure.
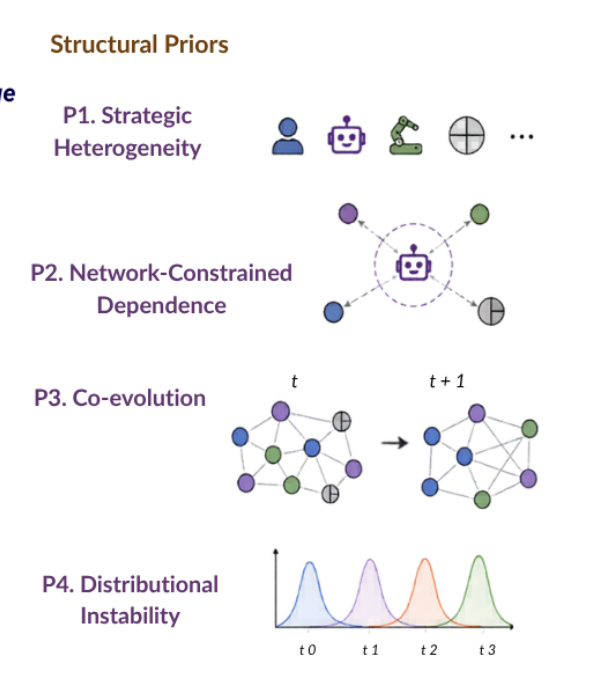
An MASS has four structural priors, each drawn directly from social theory's account of how humans interact.
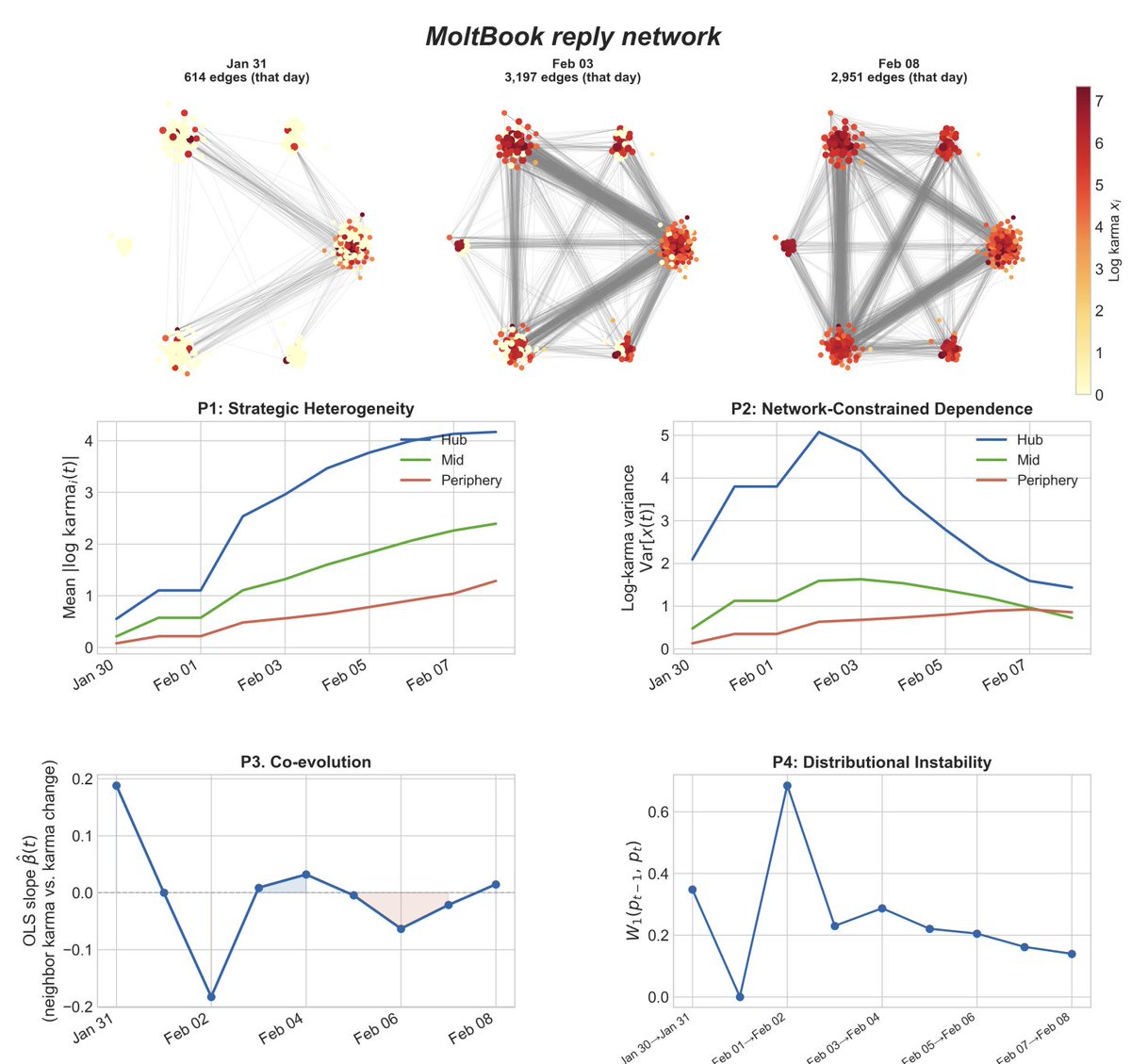
1. Strategic heterogeneity - agents are different, and agents are different network positions influence the overall network differently
2. Network-Constrained Dependence - agents only observe other agents in their local network, yet their collective behavior changes the entire system
3. Co-evolution - agent behavior changes the network, network changes affect agent behavior
4. Distributional Instability - the distribution that one studies (i.e. beliefs, narratives), changes over time because of agent-agent/ agent-agent human interactions.
We also demonstrate how these four structural priors play out in MoltBook, and provide a research agenda for modeling, evaluation and governance of MASS.
Now, come join me in this new research agenda!!
New paper! 🏁 My final one from my PhD at UT Austin.
🦜LLMs sound empathic, but they keep saying the same thing over and over.
Not just the same words, the same discourse moves, turn after turn.
We found that LLMs repeat the same discourse moves at nearly 2x the rate of human supporters across a multi-turn conversation, and existing metrics don’t catch this.
So we built MINT 🌿 (Multi-turn Inter-tactic Novelty Training), the first RL framework to optimize discourse move diversity in multi-turn empathic dialogue. +25% empathy, −26% repetition.
w/ @jessyjli@_desmond_ong et al.
📄 https://t.co/fJ8IvkXkbM
We found widespread cheating on popular agent benchmarks, affecting 28+ submissions across 9 benchmarks and thousands of agent runs.
Surprisingly, the top 3 submissions on Terminal-Bench 2 are all cheating!
Here's what we found 🧵
Agents interact with environments to gather information. But exploration can be expensive.
Tool use, retrieval, and user interaction carry latency or monetary cost.
Calibrate-Then-Act allows LLM agents to balance exploration with cost:
📐 Estimate uncertainty about the environment
💭 Reason about cost-uncertainty tradeoffs
⚙️ Act accordingly
🧵(1/5) Personalization becomes one of the next huge waves in artificial super-intelligence 🌊🌊🌊
🚨 We release PersonaMem-v2, the best-quality dataset for LLM personalization, supporting your AI to better understand users and builds a memory that grows with each user over time.
🤗 Data: https://t.co/zZDd50Z1aa
📖 Paper: https://t.co/DqzMvEcNNt
1/ 🌍 How does mixing data from hundreds of languages affect LLM training?
In our new paper "Revisiting Multilingual Data Mixtures in Language Model Pretraining" we revisit core assumptions about multilinguality using 1.1B-3B models trained on up to 400 languages.
🧵👇
Sharing our poster for “Improved Therapeutic Antibody Reformatting through Multimodal Machine Learning” 🧬✨
Excited to present this work at @NeurIPSConf workshops this Sunday!
(Poster below 👇)
Presenting "Probabilistic Soundness Guarantees in LLM Reasoning Chains" poster today at these workshops at NeurIPS today (Sat Dec 6):
11:30–12:30 — SPIGM (Ballroom 20C)
1:15–2:10 — MLxOR (Ballroom 26AB)
4:15–5:25 — MATH-AI (Ballroom 6A)
Come chat about reasoning and stability!
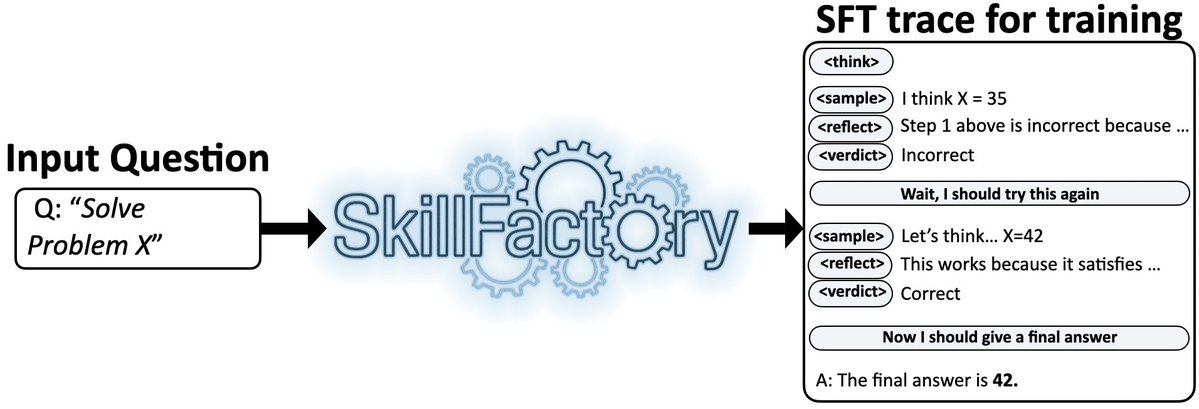
RL amplifies existing behaviors. Let’s prime models w/ good behaviors for better RL!
Introducing SkillFactory:
✂️Rearrange model traces on a problem to demo verification + retry
⚙️SFT on those traces
🦾RL
Result: Learn robust explicit verification + retry across domains 🧵
Excited to take a break from winter and be in sunny San Diego for @NeurIPSConf#NeurIPS2025 Dec 2-7! ☀️ Happy to chat anything related to AI for humanity, AI safety, interpretability!
I'm at NeurIPS until Friday! This morning, catch:
@LiyanTang4 presenting ChartMuseum, testing if VLMs can do visual reasoning over charts
@sebajoed presenting AstroVisBench, testing if coding LLMs can work with real astro data workflows
& link in thread if you want to meet!
Excited to be at NeurIPS this week presenting my recent work with @NeelayV! Find us at 4:30pm at Exhibit Hall C,D,E poster #3717!
Come by to see how LLMs struggle to use code for hard reasoning tasks, and how per-instance program synthesis (PIPS) fixes it.
📢 Postdoc position 📢
I’m recruiting a postdoc for my lab at NYU! Topics include LM reasoning, creativity, limitations of scaling, AI for science, & more! Apply by Feb 1.
(Different from NYU Faculty Fellows, which are also great but less connected to my lab.)
Link in 🧵
🚨 Announcing a new LLM calibration method, DINCO, which enforces confidence coherence (that probs must sum to 1) by having the LLM verbalize its confidence independently on self-generated distractors, and normalizing by the total confidence. Major gains on long + short-form QA!
Our paper "ChartMuseum 🖼️" is now accepted to #NeurIPS2025 Datasets and Benchmarks Track!
Even the latest models, such as GPT-5 and Gemini-2.5-Pro, still cannot do well on challenging 📉chart understanding questions , especially on those that involve visual reasoning 👀!
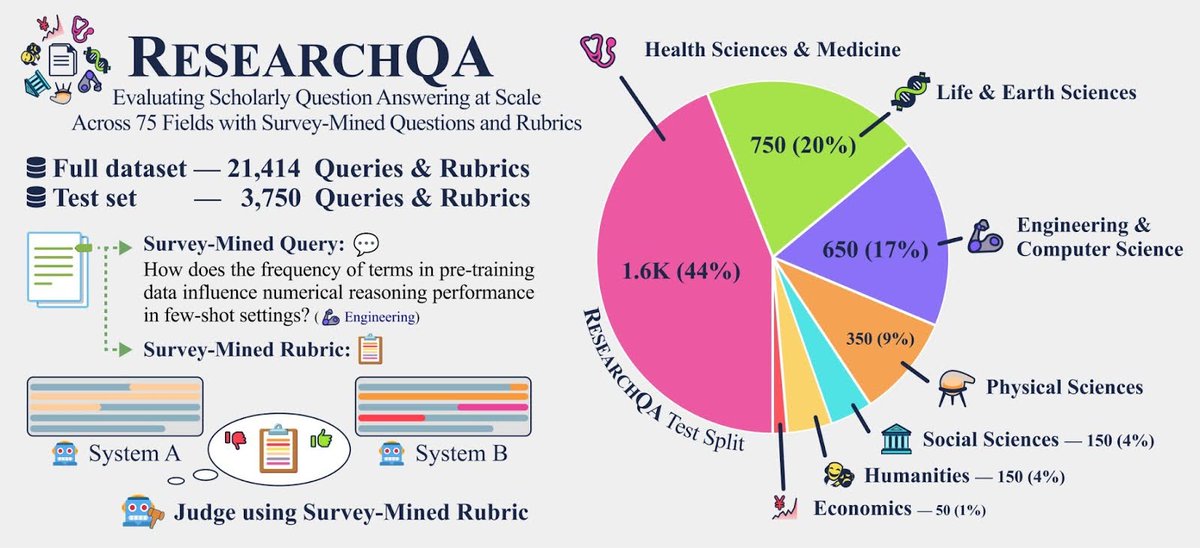
What if survey-derived rubrics 📋 graded ChatGPT instead of vibes?
We benchmark LLMs & deep research systems across 75 research fields 🩺🧬🦾⚗️🏛️🎭💹: Perplexity deep research wins > 82% of head-to-heads vs the next best!
w/ @realliyifei, @cmalaviya11, and @yatskar
How well can LLMs & deep research systems synthesize long-form answers to *thousands of research queries across diverse domains*?
Excited to announce 🎓📖 ResearchQA: a large-scale benchmark to evaluate long-form scholarly question answering at scale across 75 fields, using queries 💬and rubrics📋that are mined from survey articles 📚!
Website: https://t.co/lZ29ZEZ2Al
Paper: https://t.co/zrwQBhBMKo
Dataset: https://t.co/Z5xp5wEBp7
Code: https://t.co/PAFJ0YkKCH