What if survey-derived rubrics 📋 graded ChatGPT instead of vibes?
We benchmark LLMs & deep research systems across 75 research fields 🩺🧬🦾⚗️🏛️🎭💹: Perplexity deep research wins > 82% of head-to-heads vs the next best!
w/ @realliyifei, @cmalaviya11, and @yatskar
How well can LLMs & deep research systems synthesize long-form answers to *thousands of research queries across diverse domains*?
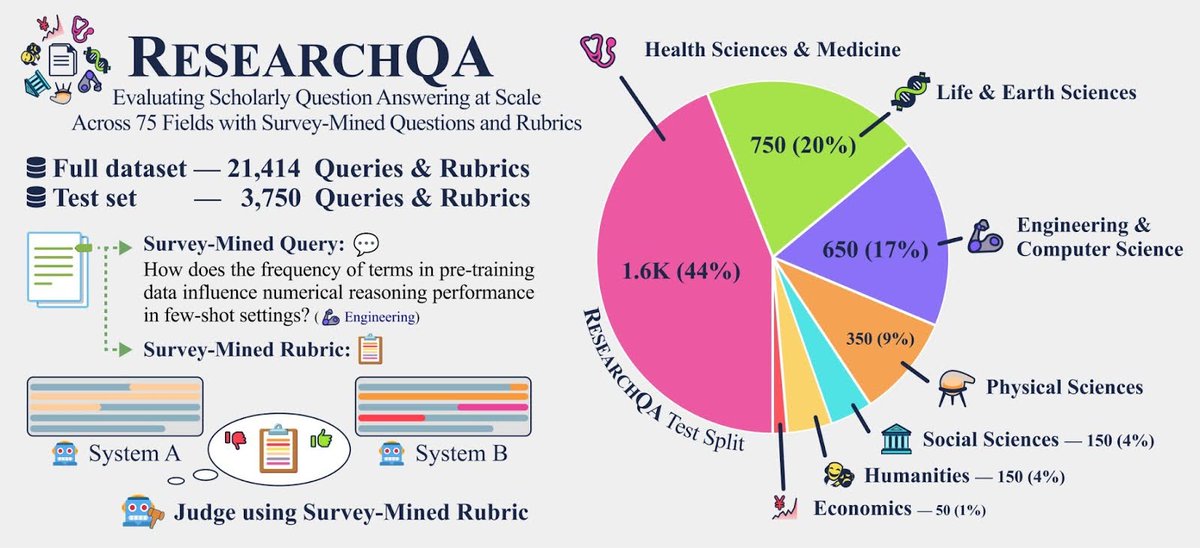
Excited to announce 🎓📖 ResearchQA: a large-scale benchmark to evaluate long-form scholarly question answering at scale across 75 fields, using queries 💬and rubrics📋that are mined from survey articles 📚!
Website: https://t.co/lZ29ZEZ2Al
Paper: https://t.co/zrwQBhBMKo
Dataset: https://t.co/Z5xp5wEBp7
Code: https://t.co/PAFJ0YkKCH
🎯 We release MolmoPoint, the best open model in GUI grounding 💻 by training on purely synthetic screenshots. We open-source all our models, data, and generation code. Plug it into your agents!
Demo: https://t.co/ANOfIa3iGm
Model: https://t.co/wwThFOlbRT
Data: https://t.co/M2w7zvE4Kc
Code: https://t.co/3aoCP7KzOy
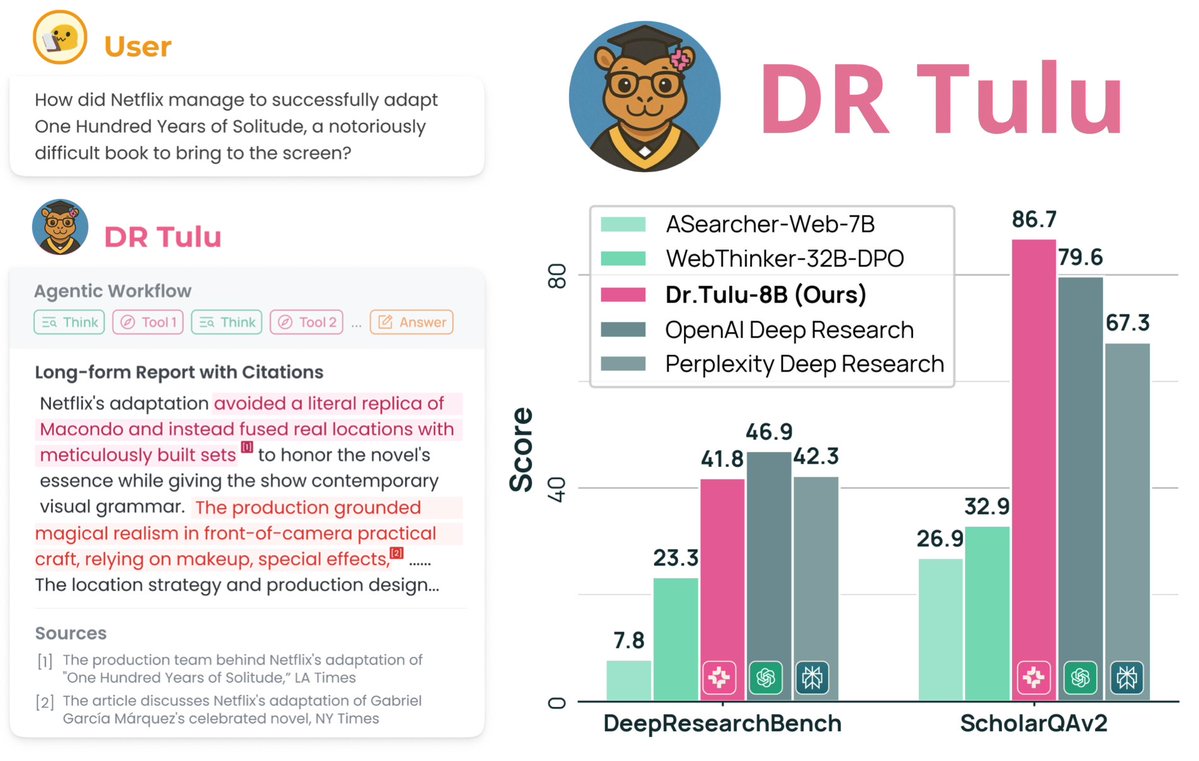
🔥Thrilled to introduce DR Tulu-8B, an open long-form Deep Research model that matches OpenAI DR 💪Yes, just 8B! 🚀
The secret? We present Reinforcement Learning with Evolving Rubrics (RLER) for long-form non-verifiable DR tasks! Our rubrics:
- co-evolve with the policy model
- are grounded on search knowledge
🧵
✨ Very overdue update:
I'll be starting as an Assistant Professor in CS at University of Minnesota, Twin Cities, Fall 2026. I will be recruiting PhD students!!
Please help me spread the word! [Thread] 1/n
🤖➡️📉 Post-training made LLMs better at chat and reasoning—but worse at distributional alignment, diversity, and sometimes even steering(!)
We measure this with our new resource (Spectrum Suite) and introduce Spectrum Tuning (method) to bring them back into our models! 🌈
1/🧵
Future AI systems interacting with humans will need to perform social reasoning that is grounded in behavioral cues and external knowledge.
We introduce Social Genome to study and advance this form of reasoning in models!
New paper w/ Marian Qian, @pliang279, & @lpmorency!
When answering queries with multiple answers (e.g., listing cities of a country), how do LMs simultaneously recall knowledge and avoid repeating themselves?
🚀 Excited to share our latest work with @robinomial! We uncover a promote-then-suppress mechanism: LMs first recall all answers and then suppress previously generated ones.
https://t.co/O4LNZ1yoH5
👇🧵
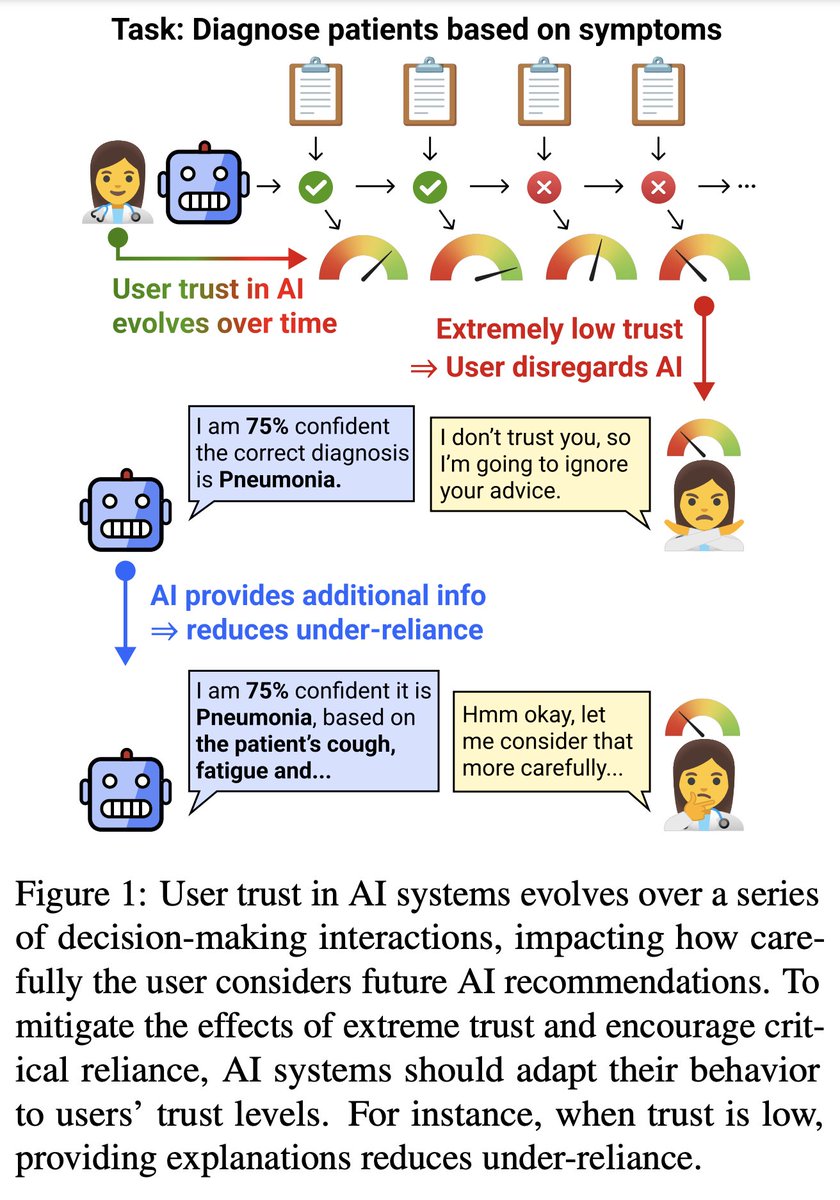
People are relying on AI assistance to make all kinds of decisions. *How* they incorporate AI recommendations is influenced by previous user-AI interactions and their evolving trust in the AI, which AI assistants are typically blind to. But what if they weren’t?
We show that having AI assistants adapt their behavior in response to user trust levels can mitigate under- and over-reliance!
Pre-print: https://t.co/5BDyifZ6sQ
Last Friday I gave an hour long talk at the Penn ILST Seminar about the particular linguistic features that characterize AI text (e.g. "delve", repetitive syntax, agreeable tone) and how they affect detectability.
Highly recommend giving it a listen.
https://t.co/DqXenhasRC
Our workshop will start in a few hours!
> #ECCV2024 9/29 AM workshop
> Suite 2, Allianz MiCo 🇮🇹
> Zoom info on our website (QR code below)
Looking forward to the discussion today and learning from our keynote speakers!
https://t.co/todVejqzpr
Meet Molmo: a family of open, state-of-the-art multimodal AI models.
Our best model outperforms proprietary systems, using 1000x less data.
Molmo doesn't just understand multimodal data—it acts on it, enabling rich interactions in both the physical and virtual worlds.
Try it for yourself: https://t.co/IWKKUdfxlg
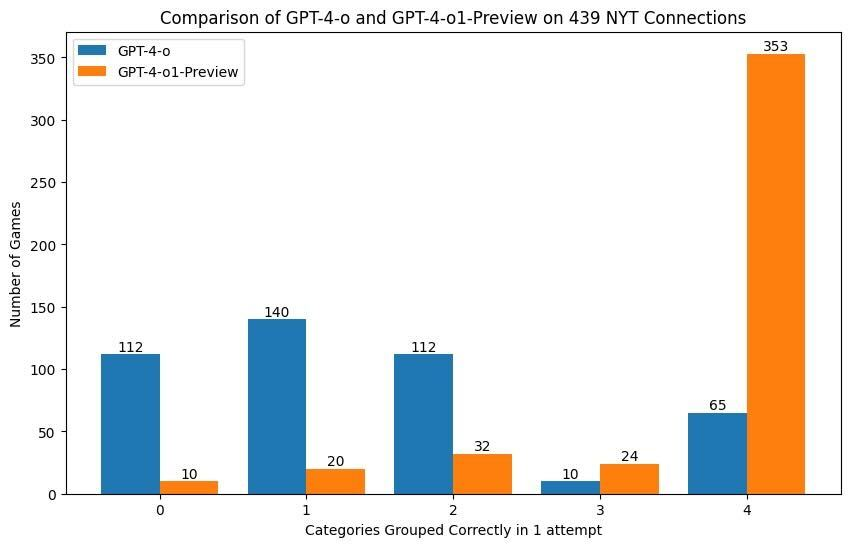
GPT4-o1-preview from @OpenAI now gets 80.4% (compared to 14% performance of GPT4o) on the Connections game in 1 single attempt. Saw a thread on LinkedIn about similar bump on Wordle. I also attached some other models in comparison. This is very impressive given how hard the task is
As someone who isn't so much about LLM scientivism, I am very confident the model was trained on these tasks. A sad and depressing trend where these models try to incorporate everything in training distribution make it super hard for researchers interested in generalization #LLM #GenAI
You think your model just fell out of a coconot tree 🥥? It should not always comply in the context of all it has seen in the request. Check out our paper on contextual noncompliance.
Our work on improving selective prediction for VLMs has been accepted to #ACL2024 Findings! Read on to learn how you can make your VLM both reliable *and* usable ✨
Paper: https://t.co/k0Uvi42u4m
Code: https://t.co/LC4R96xQUi





















![AlexanderSpangh's tweet photo. ✨ Very overdue update:
I'll be starting as an Assistant Professor in CS at University of Minnesota, Twin Cities, Fall 2026. I will be recruiting PhD students!!
Please help me spread the word! [Thread] 1/n https://t.co/J0crGi19X6](https://pbs.twimg.com/media/G5gHHmObUAAcSgh.jpg)