Today we're launching everme — personal memory for the age of agents.
The idea: you'll use many different agents, but your memory should belong to you.
Just give your agent one sentence, and everme manages your memory across all of them — with self-evolving skills, zero maintenance, and a 2-minute cold start.
With everme:
• Claude Code and Codex share memory
• openclaw and hermes agent share memory
• memory travels across platforms and machines
→ https://t.co/0P35soIy7Z
Today we're launching everme — personal memory for the age of agents.
The idea: you'll use many different agents, but your memory should belong to you.
Just give your agent one sentence, and everme manages your memory across all of them — with self-evolving skills, zero maintenance, and a 2-minute cold start.
With everme:
• Claude Code and Codex share memory
• openclaw and hermes agent share memory
• memory travels across platforms and machines
→ https://t.co/0P35soIy7Z
To evaluate your Claw agent's evolutionary capabilities, you can utilize EvoAgentBench, the second benchmark dedicated to agent evaluation on Hugging Face.
EverMind is Hiring: Technical PM (Agent OS & Memory)
Based in Silicon Valley | Shanghai | Beijing
What we need:
Tech + Product: Deeply understand Agent execution mechanics under the hood (OpenClaw/Hermes Agent is a +).
AI-Native: Fluent in Vibe Coding. You can spin up working demos yourself to validate concepts.
LTM Focus: Intensely driven to build an Agent OS with true Long-Term Memory.
Flexible setup: Open to part-time/intern as a trial.
DM me to chat!
AI self-evolution is undoubtedly the ultimate core of next-gen AI—and true evolution is fundamentally built on Long-Term Memory. 🧠
At EverMind, we believe every AI of the future must have long-term memory. If you want to build an AI that continuously adapts and unlocks a massive data flywheel, you need EverOS. ♾️
The update we’ve been polishing for ages is FINALLY live! 🚀 It's way more than just a product update—Methods, Benchmarks, Usecases, and a fresh site are all here.
Here’s the breakdown: 👇
1️⃣ EverMemOS ➡️ EverOS: The ultimate one-stop shop. EverOS now empowers your Agents with self-evolution capabilities—just like Hermes Agent. Plus, we’ve added full multi-modal support. Use our Methods to customize Usecases into your own Agents, then benchmark to optimize them. It's the absolute all-in-one king. 👑
2️⃣ EvoAgentBench is LIVE & Open-Source: The perfect tool to test your custom Claude Code, OpenClaw, Hermes, or any Agent you throw at it. 📊
3️⃣ Brand New Website: Aesthetics matter. The new vibe, colors, and interactive experiences are absolutely off the charts. 🎨🔥
Dive in here:
https://t.co/02ngJwJLve
#EverOS #AI #AgentTools #Harness @Memory #OpenClaw #Hermes #ClaudeCode
Every major wave of computing has been defined by how we store and retrieve information.
Mainframes, databases, the cloud. AI is no different. The teams that competed at Memory Genesis 2026 understand something most of the industry has not fully internalized yet: memory is not just infrastructure. It is intelligence itself.
This event was a glimpse of that future. Grateful to everyone who showed up to build it with us.
The Memory Genesis Competition 2026 Final Event kicked off today in Mountain View, CA.
Hosted by @shanda_group and @evermind, and supported by OpenAI and AWS, the Memory Genesis Competition 2026 brought together innovators, researchers, investors, and builders to explore how next-generation memory technologies will define the future of AI.
A landmark day for the memory industry. Here is what went down. (Stay until the end. You will want to see how this room looked.)
🧵
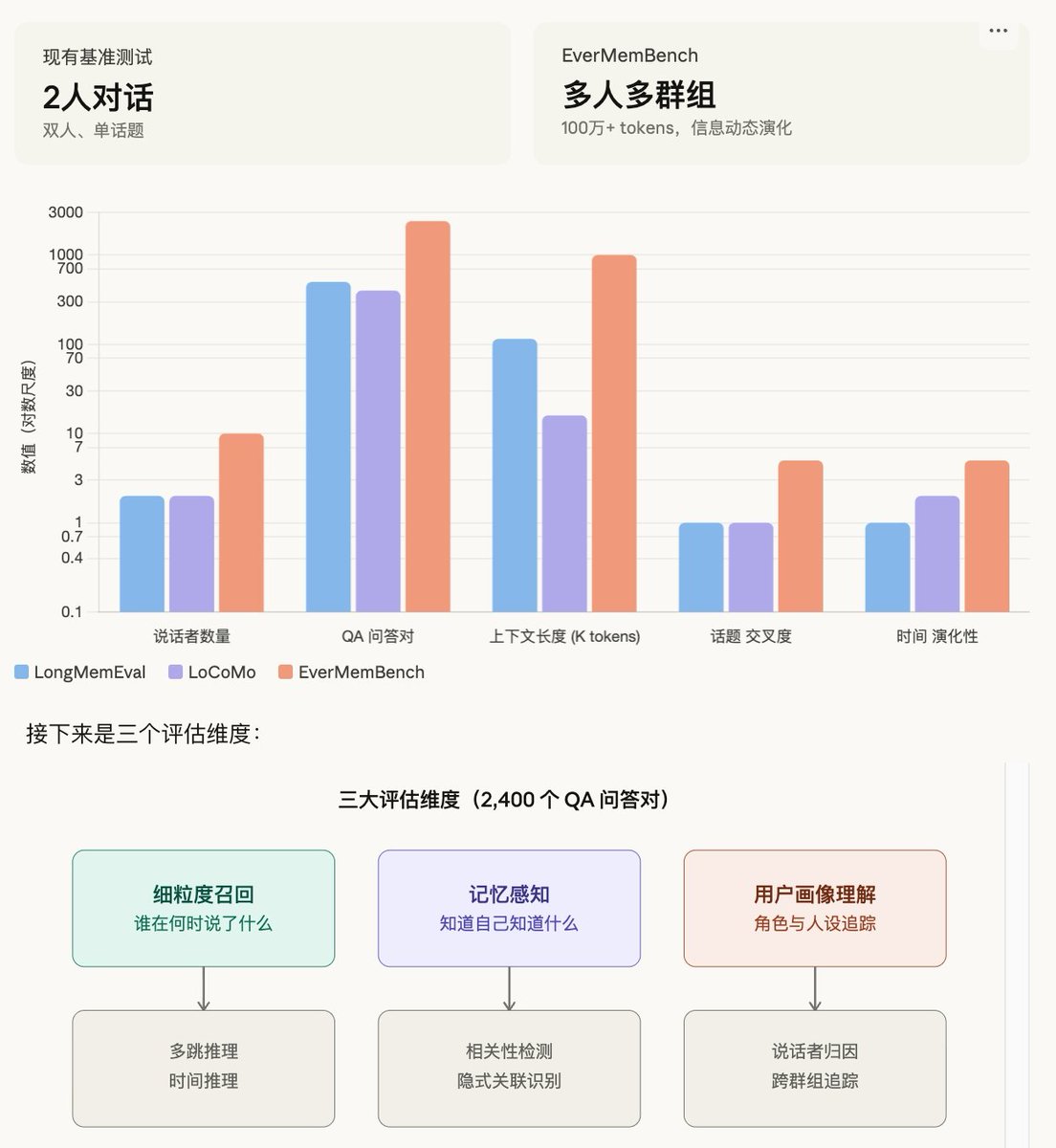
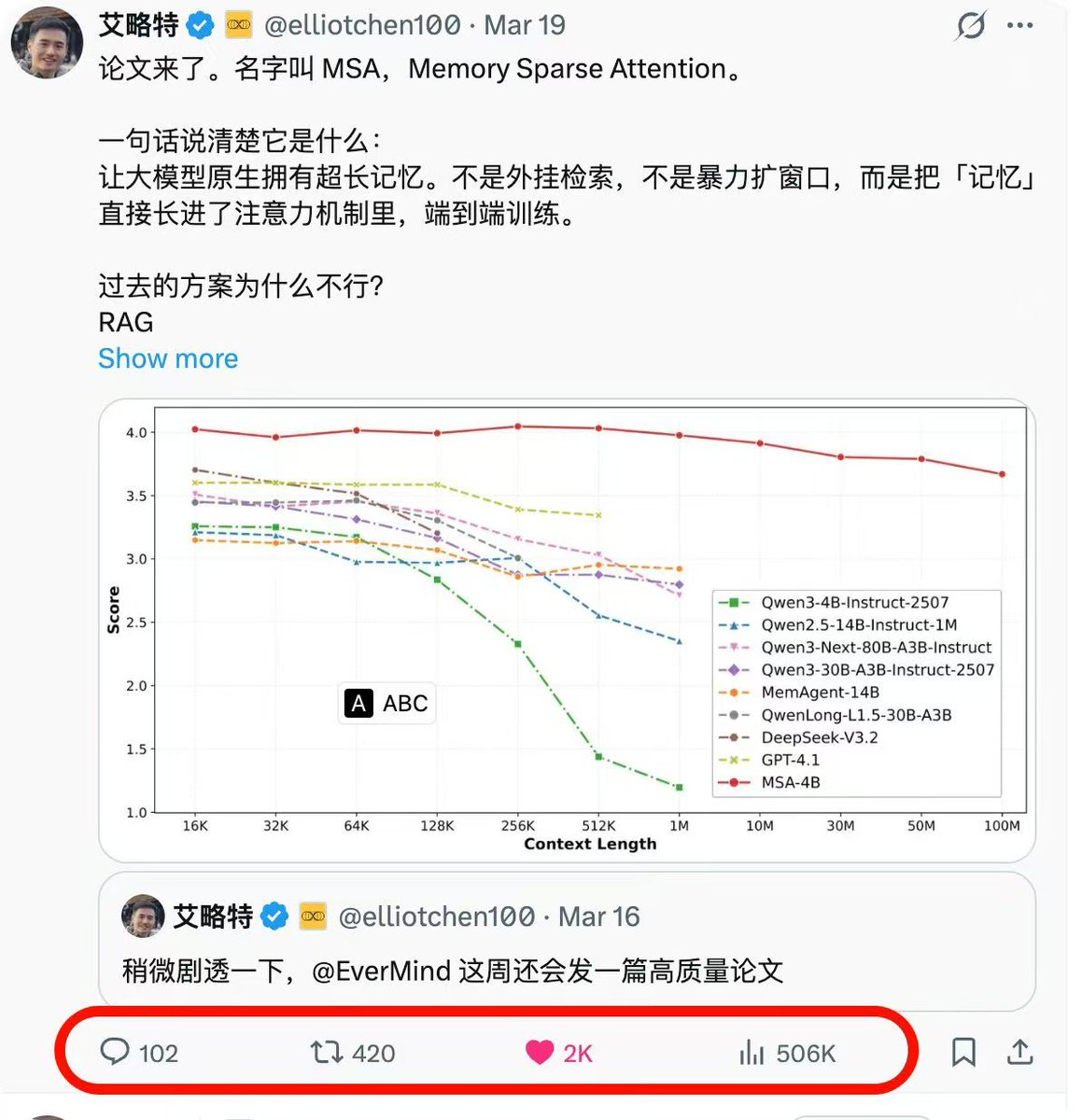
A few weeks ago we published our Memory Sparse Attention paper, a new way to give AI models long-term memory that actually works.
Today's LLMs/Agents forget. They can only hold so much context before things start falling apart. We built a system that lets a model remember up to 100 million tokens, the length of about a thousand books, and still find the right answer with less than 9% performance loss. On several benchmarks, our 4-billion parameter model even beats RAG systems built on models 58× its size.
The idea? Instead of searching a separate database and hoping the right info comes back (that's how RAG works), we built the memory directly into how the model thinks. It learns what to remember and what to ignore, end to end, no separate retrieval pipeline needed.
The response to the paper blew us away. Researchers and engineers everywhere asking the same thing: "When can we see the code?"
So we got to work, cleaned up the inference code, documented it, and made it ready for the community to dig in.
You asked for it. We open-sourced it.
https://t.co/h5pIQhgh2j
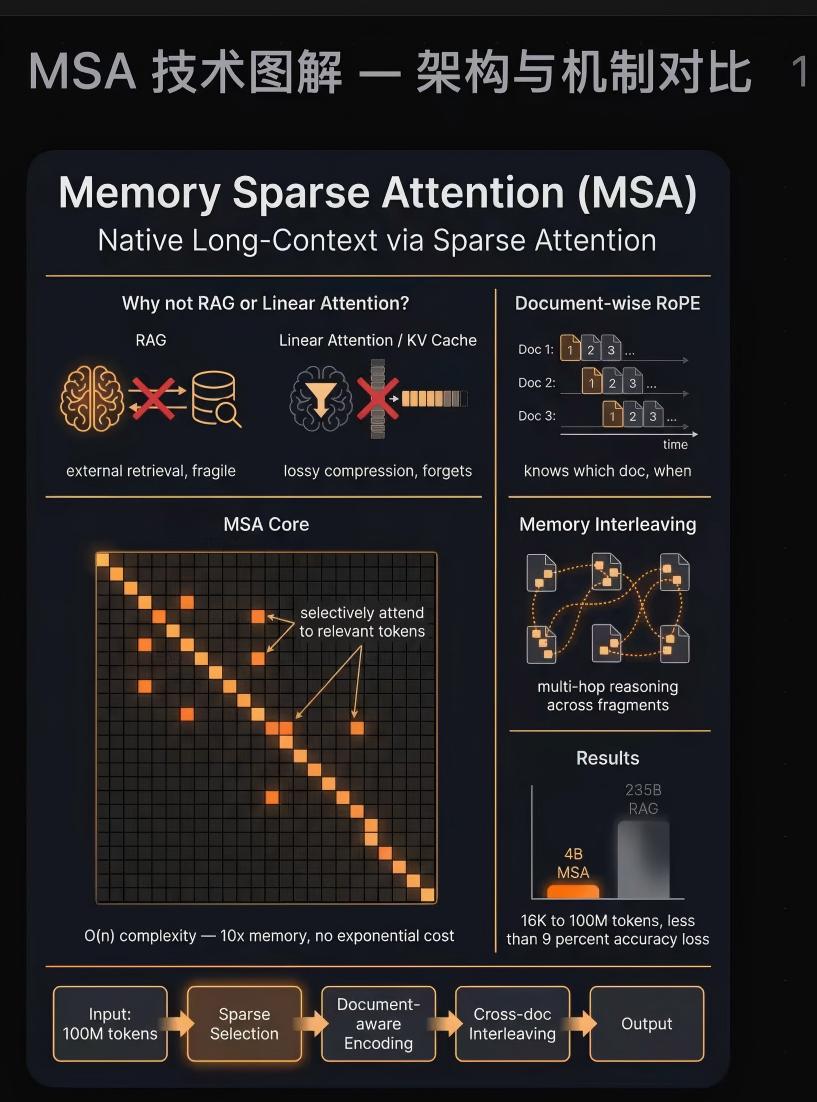
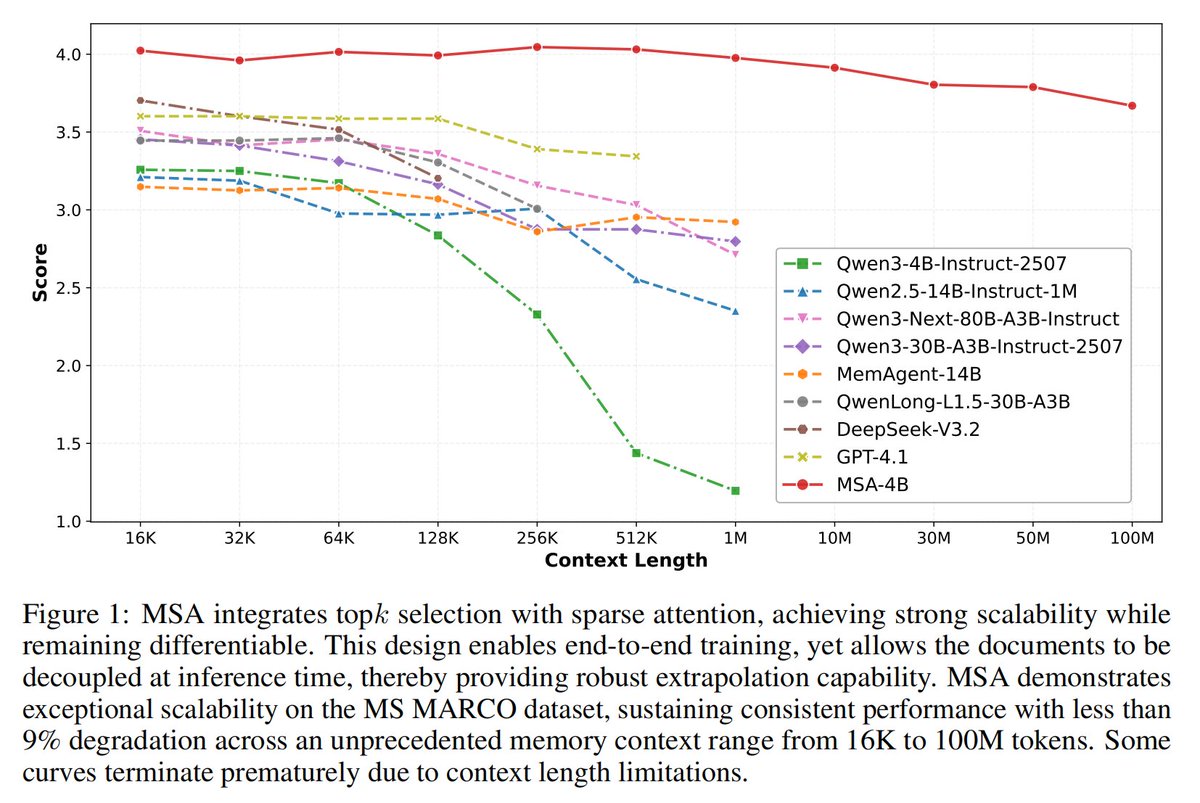
MSA (Memory Sparse Attention) represents our significant exploration in the field of long-term memory. It stands as the first end-to-end long-term memory framework for large models to genuinely achieve a 100M context length. Interestingly, as the memory length scales from 16K to 100M, the model's performance score decreases by a mere 9%, demonstrating highly robust scalability.
Main contribution:
1,We propose MSA, an end-to-end trainable, scalable sparse attention architecture with a
document-wise RoPE that extends intrinsic LLM memory while preserving representational
alignment. It achieves near-linear inference cost and exhibits < 9% degradation even when
scaling from 16K to 100M tokens.
2,We introduce KV cache compression to reduce memory footprint and latency while maintaining retrieval fidelity at scale. Paired with Memory Parallel, it enables high-throughput
processing for 100M tokens under practical deployment constraints, such as a single 2×A800
GPU node.
3,We present Memory Interleave, an adaptive mechanism that facilitates complex multi-hop
reasoning. By iteratively synchronizing and integrating KV cache across scattered context
segments, MSA preserves cross-document dependencies and enables robust long-range
evidence integration.
4,Comprehensive evaluations on long-context QA and Needle-In-A-Haystack benchmarks
demonstrate that MSA significantly outperforms frontier LLMs, state-of-the-art RAG systems and leading memory agents.
Welcome to feedback:
https://t.co/OGUAAmz68h
https://t.co/3cMGjht0yk
We are looking for passionate talents to join our team! If you are interested in our work and vision, please don't hesitate to send us an email at [email protected].