EverOS just had its fastest 30-day run ever.
+2,700 GitHub stars, 7,000+ total, and EverOS 1.0.0 is now out.
The growth followed a wave of practical agent memory use cases.
Not just stars. Workflow demand.
https://t.co/wyiBLYBjG7
A child remembers a lullaby.
A parent remembers a red ribbon. Time blurs the rest.
Reunite uses AI to find families across the gaps memory leaves behind.
Built by Xiao Ba (Japan), Public Value Award winner at Memory Genesis Competition 2026.
EverOS passed 6,000 stars on GitHub today.
This milestone means a lot to our team. We’ve put serious work into building an open home for long-term and self-evolving memory in agents: real use cases, runnable methods, benchmarks, and tools developers can build on.
If you believe agents need memory to become truly useful, we’d love your support.
The Memory Genesis Competition 2026 has officially concluded.
Yesterday, we unveiled the complete Hall of Fame, honoring every team whose work helped define the future of long-term memory for AI.
From the Top Five and Excellence awardees to our Public Value, Finalist, and Onsite winners, each recipient represents a milestone in the journey beyond the context window.
To the 420+ builders who joined us from around the world, thank you for shaping what memory means for intelligence.
Few projects carry such weight of purpose.
Reunite, honored at the Memory Genesis Competition 2026, was built around one of the most painful realities a family can face: the loss of a child. It turns memory itself into a path back home.
Parents register the details they hold most closely. Physical features, birthmarks, mannerisms, the places and moments that defined their child's earliest years. Children who have been separated from their families record the scattered fragments they still carry. A room they once lived in, a voice they still hear, a song, a street, a face half remembered.
Powered by EverOS, Reunite applies semantic matching across both sides of the record. Where keyword search would fail, meaning-based search can hold. Memories that have shifted, blurred, or surfaced only in pieces can still find their counterpart. A partial recollection becomes a lead. A lead becomes a reunion.
Technology is rarely asked to do something this tender. Reunite is a reminder that when it is built with care, it can be.
Our deepest respect to the team behind this work, and our congratulations on the recognition so rightly earned.
To celebrate the release of MSA Inference, we pretext a web to play with the MSA key words, share with you here. Enjoy your weekend : ) @evermind
https://t.co/FZVQdeHdvB
#Memory#MSA#pretext
A few weeks ago we published our Memory Sparse Attention paper, a new way to give AI models long-term memory that actually works.
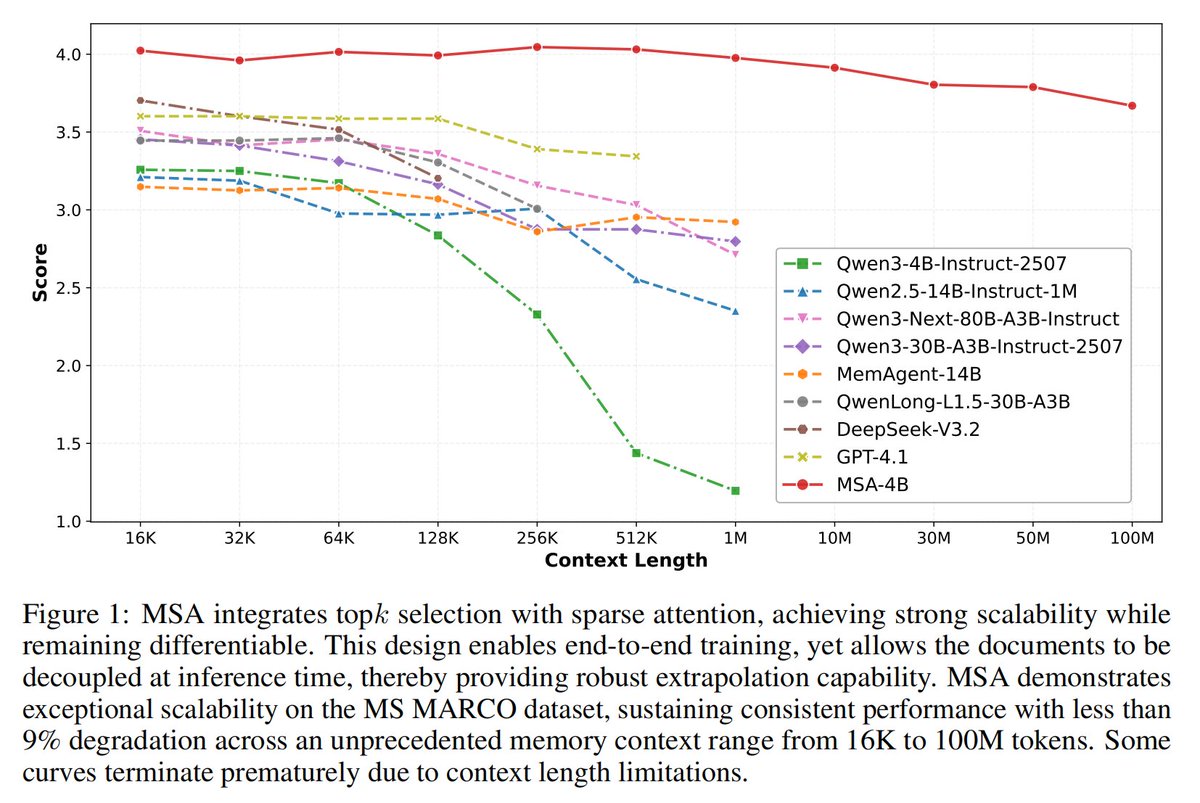
Today's LLMs/Agents forget. They can only hold so much context before things start falling apart. We built a system that lets a model remember up to 100 million tokens, the length of about a thousand books, and still find the right answer with less than 9% performance loss. On several benchmarks, our 4-billion parameter model even beats RAG systems built on models 58× its size.
The idea? Instead of searching a separate database and hoping the right info comes back (that's how RAG works), we built the memory directly into how the model thinks. It learns what to remember and what to ignore, end to end, no separate retrieval pipeline needed.
The response to the paper blew us away. Researchers and engineers everywhere asking the same thing: "When can we see the code?"
So we got to work, cleaned up the inference code, documented it, and made it ready for the community to dig in.
You asked for it. We open-sourced it.
https://t.co/h5pIQhgh2j
It's been 3 months we plan and execute the Memory Genesis Competition. And finally the team will meet the community face-to-face. Pity for my absence, but thanks to the team, everything is just perfect. We have more that 420 participants and high-quality submissions, so we must expand the prize pool and number of awards as you can see on our webpage: https://t.co/V7ikRCM4V7. The final event on April 4, this Saturday at the Computer History Museum, is also recommended by Luma as San Fransisco hot event. We planned for 150-200 audiences but over 700 have registered so far, so please come earlier. We start onsite registration from 12:00 noon. Judges and audiences will decide special prizes during the event. So you're also part of our community since now. Welcome to join us!
Scaling Attention to 100M context!?
Memory Sparse Attention introduces an idea where instead of rereading an entire 100M-token entry, it learns to jump straight into the relevant memories and reason from them end-to-end.
More specifically, it first encodes documents into compressed memory slots, then for each question it uses a learned router to score which chunks are actually relevant, pulls only the top few, and runs normal attention over that tiny assembled context.
So the model’s compute grows with “how much it needs to look at” not “how much memory exists”.
This retrieval step is trained jointly with answer generation, so memory lookup is part of the model itself, and can decouple memory capacity from reasoning cost.
DYJ Studio has already built a strong reputation in AI video production with more than 300 followers across all platforms, with the team winning multiple international awards. We’re delighted to have their support in creating this special explainer on the MSA paper. AI is making an impact everywhere. Thanks to @DYJ_Science
Another team from @shanda_group, called @DYJ_Science, made this science video on Memory Sparse Attention for us.
Gotta say, it nails the hard concepts in an easy way, very well done, thank you very much!
https://t.co/cvumAVpHjt
Final chapter of Memory Genesis 2026 is here.
April 4 · Computer History Museum · Mountain View
Finalist teams demo live. 30+ judges score in real time. $80K+ in prizes.
Keynote on agents, reasoning & memory.
3 expert panels. Awards ceremony.
The future of AI memory gets built on stage.
https://t.co/LgZnb1ETud
Last year, we explored the horizon.
This year, we reach it.
🗼 AGI Horizon Tokyo 2026 is here.
Bigger scope. Deeper insights. Unmatched connection.
Why attend?
🔹 Elite Speakers: The minds behind Anthropic Japan, Product Hunt, alongside visionary founders and global investors.
🔹 Unique Networking: VVIP Tea Ceremony in a Zen garden. 🍵
🔹 Cutting-Edge Tracks: Creative Practices, Tech Evolution, Global Perspectives
📅 April 8 – Reserve your spot now 👇
https://t.co/hVWSl8pgkC
Don't just watch history – be part of it
#agi2026 #waytoagi #ai #tokyo #AGIhorizon #東京AI
If you wanna get the most accurate explanation technically, you must follow Yafeng~ He consistently strives for precision in all aspects, reliable not only in research but also in everyday management.
MSA (Memory Sparse Attention) represents our significant exploration in the field of long-term memory. It stands as the first end-to-end long-term memory framework for large models to genuinely achieve a 100M context length. Interestingly, as the memory length scales from 16K to 100M, the model's performance score decreases by a mere 9%, demonstrating highly robust scalability.
Main contribution:
1,We propose MSA, an end-to-end trainable, scalable sparse attention architecture with a
document-wise RoPE that extends intrinsic LLM memory while preserving representational
alignment. It achieves near-linear inference cost and exhibits < 9% degradation even when
scaling from 16K to 100M tokens.
2,We introduce KV cache compression to reduce memory footprint and latency while maintaining retrieval fidelity at scale. Paired with Memory Parallel, it enables high-throughput
processing for 100M tokens under practical deployment constraints, such as a single 2×A800
GPU node.
3,We present Memory Interleave, an adaptive mechanism that facilitates complex multi-hop
reasoning. By iteratively synchronizing and integrating KV cache across scattered context
segments, MSA preserves cross-document dependencies and enables robust long-range
evidence integration.
4,Comprehensive evaluations on long-context QA and Needle-In-A-Haystack benchmarks
demonstrate that MSA significantly outperforms frontier LLMs, state-of-the-art RAG systems and leading memory agents.
Welcome to feedback:
https://t.co/OGUAAmz68h
https://t.co/3cMGjht0yk
We are looking for passionate talents to join our team! If you are interested in our work and vision, please don't hesitate to send us an email at [email protected].