🚀 Our method, Poutine, was the best-performing entry in the 2025 Waymo Vision-based End-to-End Driving Challenge at #CVPR2025!
Our 3 B-parameter VLM Poutine scored 7.99 RFS on the official test set—comfortably ahead of every other entry (see figure).
We’ve just released the #Alpamayo Chain-of-Causation (CoC) Autolabeling Pipeline — a feature that has been highly requested by the community!
The pipeline automatically derives:
🔹 Meta-actions: high-level categorical descriptions of ego motion
🔹 Chain-of-causation labels: causal links between scene factors and the ego vehicle’s intended behavior
Autolabeling pipeline: https://t.co/2mrnj47WzK
Learn more about the Alpamayo open platform: https://t.co/P0nuqkwBab
We’re excited to see what the community builds with it, and we hope this tool will help accelerate research in the rapidly growing area of #reasoning models for #Physical #AI.
@NVIDIADRIVE@NVIDIAAI
Excited to introduce #TruckDrive 🚛 at #CVPR2026: a new long-range driving dataset built specifically for long-range truck autonomy, where safe braking and anticipatory planning demand perception hundreds of meters ahead, far beyond existing robotaxi datasets.
📦 TruckDrive includes:
🔹 475K samples, with 165K densely annotated frames
🔹 Benchmarks for end-to-end driving, tracking, planning, depth estimation, and up to 1,000m for 2D detection and 400m for 3D detection 📏🎯
🛰️ A purpose-built long-range sensor suite:
🔸 7 long-range FMCW LiDARs (range + radial velocity)
🔸 3 high-res short-range LiDARs
🔸 11× 8MP surround cameras for short and long-range📷
🔸 10× 4D FMCW radars 📡
⚠️ Key finding: current state-of-the-art models break down at long range
📉 with 31% to 99% drops on 3D perception tasks beyond 150m. TruckDrive exposes a long-range generalization gap that current architectures and training signals are not closing yet - a benchmark for the next generation of long-range highway autonomy research 🚚
🔗 Project and Data: https://t.co/fNzDCbGQRQ
Fun work together with @torc_robotics led by Filippo Ghilotti, Edoardo Palladin, Samuel Brucker, Adam Sigal, and Mario Bijelic.
Are we done with object detection? What about tiny objects beyond 200 meters? 🔎
Telescope 🔭 addresses long-range perception by explicitly tackling extreme scale imbalance ⚖️ in images. It hinges on a learnable hyperbolic foveation transform from a low-resolution image, magnifying distant regions 🔍 while compressing nearby ones - effectively normalizing object scales with minimal computational overhead. Objects are detected in the transformed (Riemannian) space using a novel bounding box parameterization and are then mapped back to the original image.
Project: https://t.co/mBuQGd7KnB
New preprint led by @saeedrmd! “Artificial Intelligence for Modeling and Simulation of Mixed Automated and Human Traffic."
Drawing on 200+ papers, it offers a snapshot of where the field stands and outlines promising directions ahead.
ScenarioControl 🚗🛣️ - Scenario Generation from a single Dashcam Image 📸 or Text Prompt 💬!! Excited to introduce a new vision-language control mechanism for learned driving scenario generation. Given a single dashcam image or a scene prompt or an image, we generate a full scene layout 🧩, temporally consistent rollouts, including map 🗺️, agents 🚗, and ego video🛣️
ScenarioControl enables direct, fine-grained control over layout and traffic while preserving realism. It operates in a vectorized latent space with a new cross-global control mechanism to fuse vision-language inputs with scene structure while preserving realism. Interfaces seamlessly with generative video models!
Project: https://t.co/3gEvcdk1lE
Super fun project by Lili Gao, @Yanbo_Xu_ , William Koch, Samuele Ruffino, @Luke22R , Behdad Chalaki, Dmitriy Rivkin, Julian Ost, @rogg1111, Mario Bijelic.
Reasoning VLAs can think. They just can't think fast. Until now.
Introducing FlashDrive⚡
🚀 716 ms → 159 ms on RTX PRO 6000 (up to 5.7×)
✅ Zero accuracy loss
FlashDrive = streaming inference + DFlash speculative reasoning + ParoQuant W4A8
Real-time reasoning for autonomous driving is here!
https://t.co/zWIBhyJ5QN
Chop the gradients ✂️! We found that truncating decoder gradients in latent video diffusion to a fixed window allows us to finetune on videos with pixel-wise perceptual losses without running out of memory. Pixel losses have been essential for image generation and reconstruction, but until now, they haven't scaled to long-duration, high-resolution video diffusion due to recursive activation accumulation in causal decoders, leading to OOM during training 💥📉.
Project: https://t.co/IMMbKM0s3j
Video diffusion models can do a lot more 🚀 when you can backprop the decoder! Post-process neural rendered scenes, super-resolve videos, harmonize lighting in controlled synthetic driving scenes, and inpaint videos — all in a single step ⚡ with a quick finetune from a standard diffusion model.
WorldFlow3D: Unbounded 3D World Generation 🌍 by Flow Through Hierarchical Distributions, without VAEs !
We reformulate 3D generation as flowing through sequentially finer 3D distributions, cutting training time by more than half ⏱️ compared to existing approaches! Vectorized map layouts provide full scene controllability 🗺️, and a novel flow-field alignment process enables causally coherent, spatially unbounded generation 🌍. This generative method generalizes across both real and synthetic data distributions!
Project: https://t.co/D6v2dPVYxN
Project led by @amogh7joshi and Julian Ost — will be super fun to build on this! 🔥
We’re releasing OmniReset, a framework for training robot policies using large-scale RL and diverse resets for contact-rich, dexterous manipulation.
OmniReset pushes the frontier of robustness and dexterity, without any reward engineering or demonstrations.
Try the policies yourself in our interactive simulator! https://t.co/3hW3nYx2vD
(1/N 🧵)
🎮 Can we learn interactive world models from letting robots “play”?
➡️ Introducing ✨PlayWorld: a framework for training high-fidelity video world models from large-scale autonomous play experience that enables:
→ Accurate dynamics prediction
→ Reliable policy evaluation
→ RL fine-tuning entirely inside the world model
🌐https://t.co/Kpd2DoveXc
🚨 New Paper 🚨
TL;DR we derive scaling laws of lr, momentum, and batch size for modern first-order optimizers through the lens of recent convergence bounds for LMO, a framework that includes normalized SGD, signSGD (approximating Adam), and Muon
https://t.co/hcdDMOvKYH
JEPA are finally easy to train end-to-end without any tricks!
Excited to introduce LeWorldModel: a stable, end-to-end JEPA that learns world models directly from pixels, no heuristics.
15M params, 1 GPU, and full planning <1 second.
📑: https://t.co/cpTzgvbTS0
Introducing @QuiverAI, a new AI lab and product company focused on frontier vector design.
We’ve raised an $8.3M seed round led by @a16z, with support from amazing angels and investors.
Our first model, Arrow-1.0, generates SVGs from images and text. It’s available now in public beta at https://t.co/zjAnKlI8pp
What if a world model could render not an imagined place, but the actual city?
We introduce Seoul World Model, the first world simulation model grounded in a real-world metropolis.
TL;DR: We made a world model RAG over millions of street-views.
proj: https://t.co/Bx4KUAqrRs
I'm not sure about the details but I'm convinced that how to publish and create impact is due to change very significantly in the near future. The value of writing and reading 8 page PDFs is rapidly dropping. What is the right way to publish the nugget of a research contribution?
Montreal deep tech scene is getting hot!! Many recent hires of Cohere, Mistral, Periodic Labs, Poolside are all based in Montreal. And now, AMI will have an office here 🔥
It's a no-brainer, though. @Mila_Quebec has the highest concentration of deep learning expertise with interdisciplinary connections.
Thanks to recent US regulation changes on immigration, no more brain drain! Let's build more in Canada!
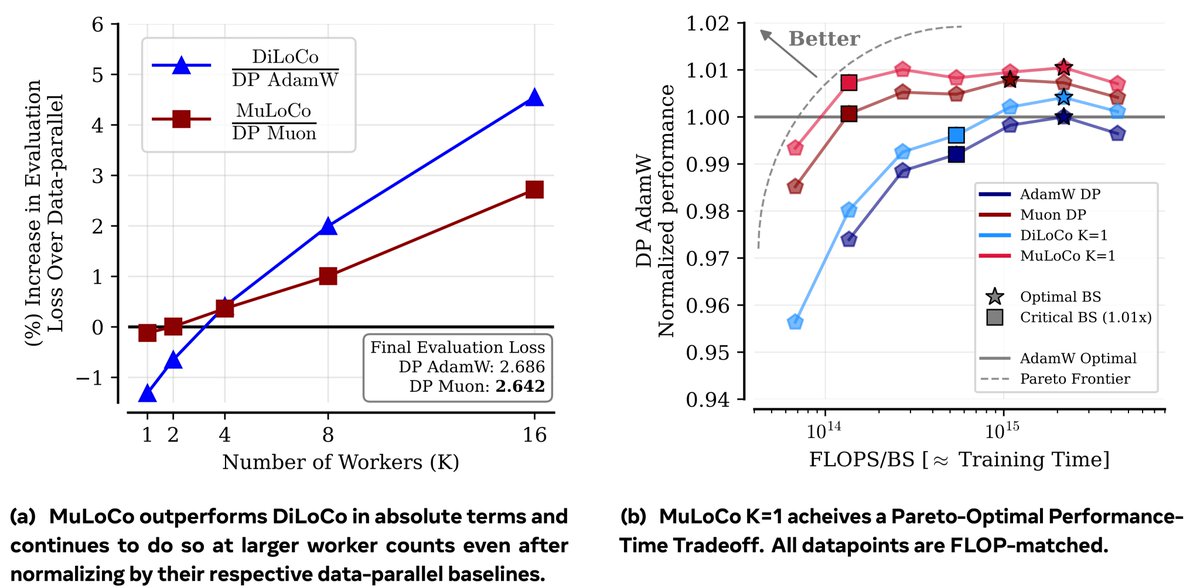
Are frontier LLMs trained across datacenters? One thing is certain: if the pre-training optimizer’s critical batch size is too small, they are NOT! Excited to announce MuLoCo, a pre-training optimizer that can efficiently pre-train across datacenters while having large enough batch sizes to warrant doing so. 🧵1/N
Benchmarks are a key driver of progress. But how should we evaluate human-like driving? Does the Waymo Open Sim Agent Challenge (WOSAC) really capture what matters?
Looking forward to any feedback!