@VivekVRao1 Looks like they just passed the base models through their exams and sims but didn't wrap them in code harnesses? If this is the case and they rerun with Codex/Claude Code now, AI should be much better at updating their beliefs quantitatively. Much innovation at harness layer too
Authors can't be trusted to run their own robustness checks.
In 17 AER papers, only 12/211 robustness checks "fail" with p > 0.05 (white).
In robustness checks chosen by 3rd parties, almost *half* of them fail (blue).
1/
You just won a 2-week, all-expenses-paid vacation to the capital stack. But there’s a catch: you have to stay within one region the whole time. What are you picking?
@taobanker I mean Matrix Reloaded is obviously not like Godfather sequel level but I think it’s still underrated… give it a rewatch sometime it actually ages pretty well
Good morning my loves, happy Saturday. Sorry I've been quiet, obviously been busy, but thought it'd be nice to give you all the details on the multi-strategy absolute return program that experienced the 28% drawdown this year. (1/n)
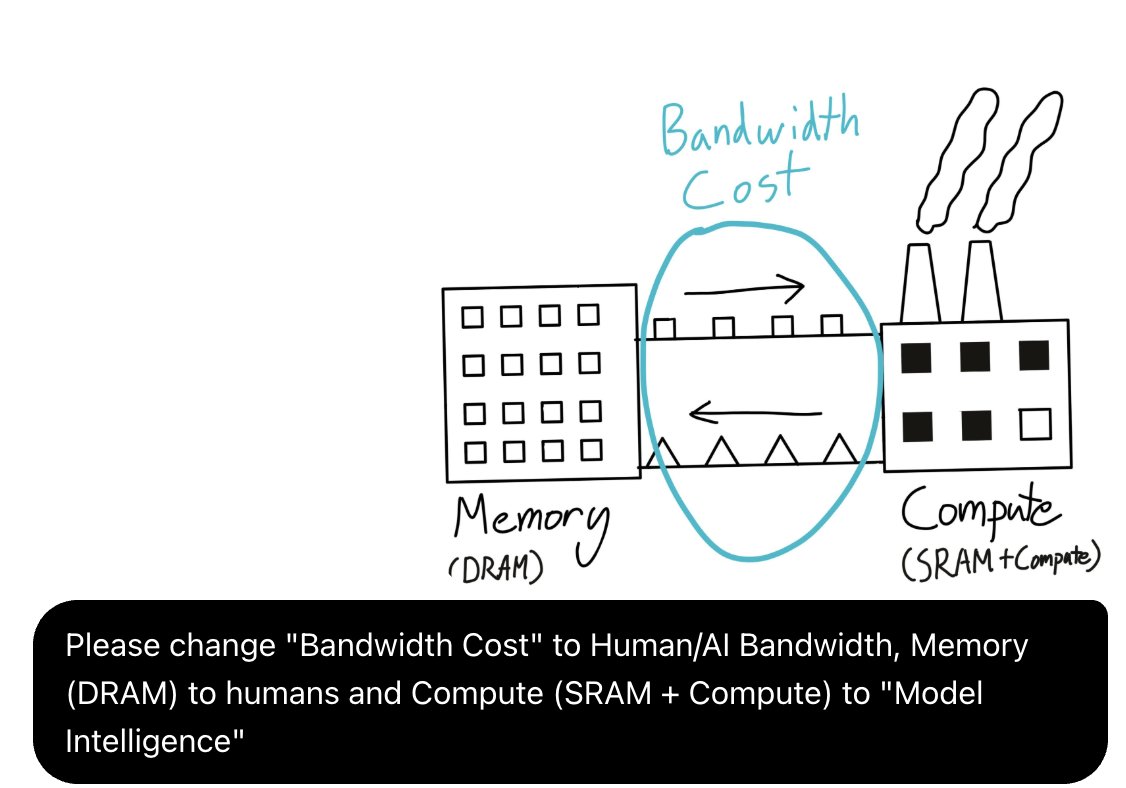
We've ran into a new set of tasks that are challenging to train on because they involve internal tools and processes or customer preference data that can't be found on the internet. RL with low success rate doesn't get you very far (after all, you can't really expect learn if you keep failing and don't know what you don't know), so we've had to look for other algorithms.
The self-distillation literature has a nice solution involving a teacher and a student model. Think of the teacher as a "peer" of the student (it has the same model weights), but with access to a reference/solution manual that it uses to critique the student's work. We've found that this can lift the model out of a valley of failures on out-of-distribution tasks, and lead it to forget less compared to other methods that change the weights. Additionally, we introduce an extension (RMSD) that improves the data and compute efficiency of this method.
Check out our blog (link in thread).
Some new results I found surprising that I’m tweeting for Chris (who isnt on here). With enough compute, the best data filter for LMs (on DCLM) might be no filter. Why? Large models can tolerate a surprising amount of nominally 'low quality' data, and can sometimes even benefit.
@FangYi11101@PaulHuangReport@POTUS@usairforce Having eaten many poorly cooked meals on the plane (both economy and business class), I don’t see how one could complain about this… airplane food doesn’t have to be fine dining
@FangYi11101 Thought the first reply was supposed to be ragebait but wow it’s sad to see ppl still perpetuating Wall Street stereotypes without questioning it
we introduce SPV-n, a primitive n-layer architecture composed of n repeated SPV modules, each layer transforms the incoming SPV representation and passes it to the next stage, forming a compact hierarchical stack from input SPV to output SPV