Postdoc at Wageningen University in the Netherlands.
Data geek, RNA enthusiast.
Interested in all things genomics, bioinformatics, and plant development.
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
https://t.co/YCvOwwjOzF
Part code, part sci-fi, and a pinch of psychosis :)
#DNA🧬🌱 | Did you know that a large part of our DNA does not contain genes? We call this non-coding DNA, which can have various other functions in organisms. But how do we discover these functions? A new AI tool comes to the rescue, read how here! https://t.co/NLXPhhqzjP
We couldn't be prouder of the enthusiastic participants who attended our new course on Single cell transcriptomics in plants. Looking forward to expanding knowledge and skills in the field! Many thanks to @EPSGradSchool, @RIBESresearch, @BMKGENE, and our brilliant speakers! 📸👥
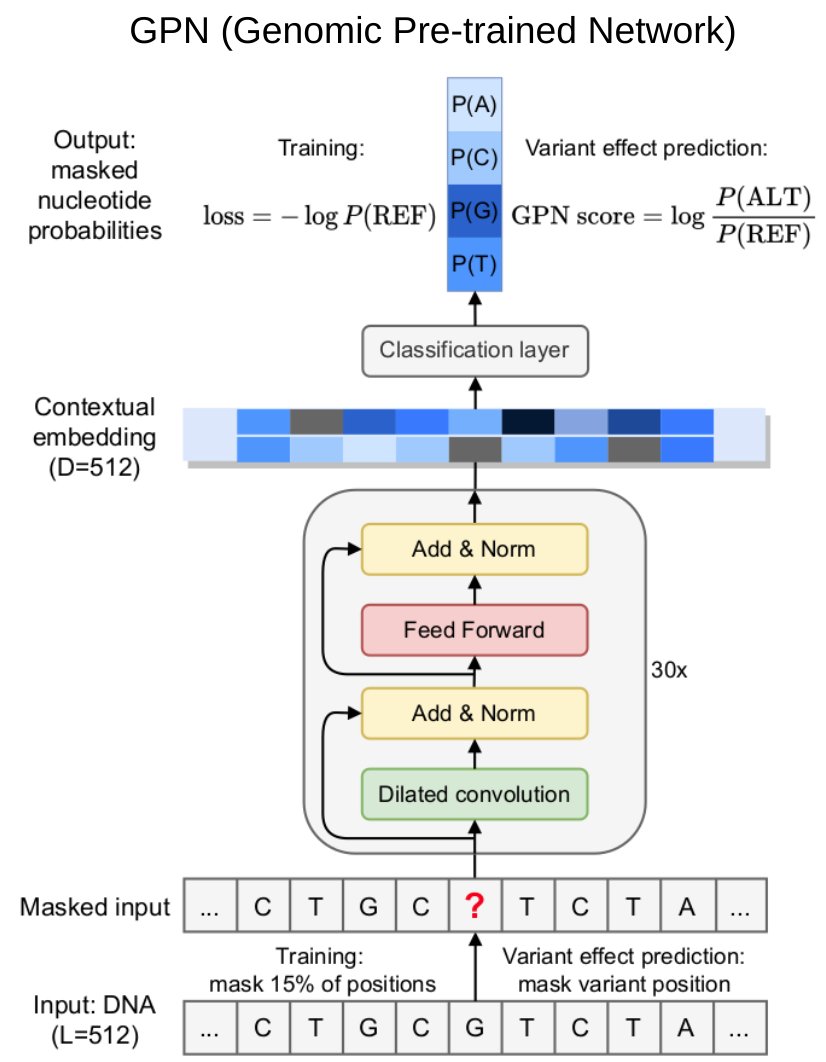
Excited to share our findings training GPN, a DNA language model for Arabidopsis thaliana, with @sanjitsbatra and @yun_s_song:
DNA language models are powerful predictors of non-coding variant effects, without the need for any labeled data.
https://t.co/dLWdMoF1Np
1/n
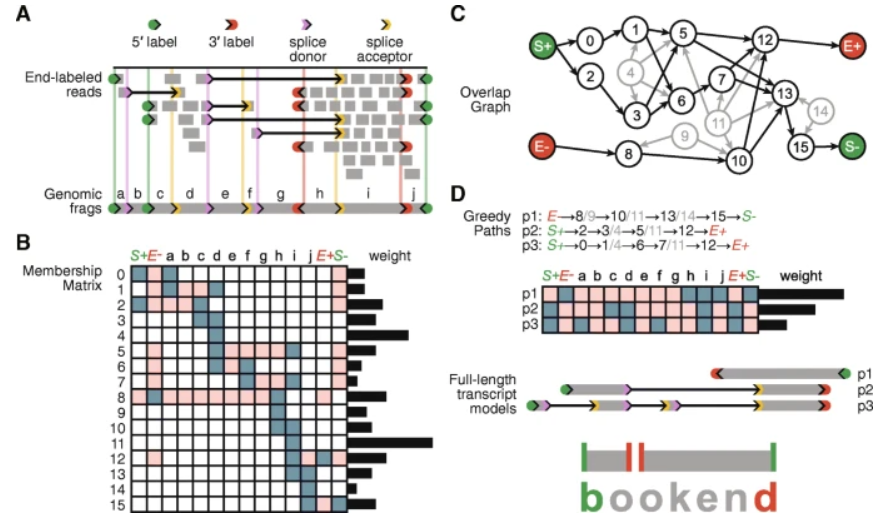
Bookend, from @MSchon0, @mnodine1 & co, improves transcript reconstruction by combining different RNA-seq techniques. Focusing on 5' and 3' transcript ends gives more accurate full-length transcript models https://t.co/RBKtL8sHKp
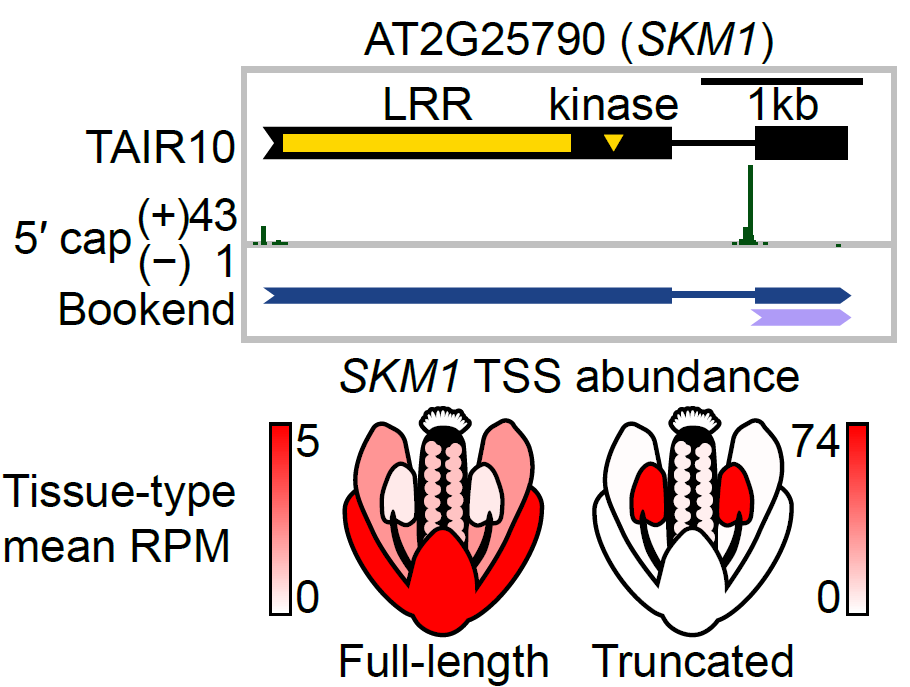
Anthers make some truly weird isoforms, like this LRR-RLK gene transcribed without its LRR or RLK domains... could this be a form of functional silencing without transcriptional silencing? We don't know yet, but it's not the only gene that does this! (6/6)
Transcript assembly remains a challenging puzzle, but it becomes a lot easier when you can start with the edge pieces. If you're interested, try out Bookend for yourself! https://t.co/xAAR5llQA8 (14/14)
I'm happy to finally share a tool I've been working on and the centerpiece of my PhD with @mnodine1. I'm especially excited for its potential to accurately annotate transcript isoforms from rare tissues and single-cell datasets. Bookend: A Thread 🧵 (1/14) https://t.co/Ny3Xp9rOwV
By layering together scRNA-seq, CAGE and 3P-seq into one hybrid assembly, Bookend builds a mESC annotation with 63% matches to RefSeq and/or Gencode isoforms. This is better concordance than the two reference annotations even have with each other! (13/14)