Parallelware Analyzer 1.2 is out!
- New entry-level performance optimization report designed for the performance optimization roadmap.
- Improved out-of-the-box user experience.
Learn more about these new features 🔗https://t.co/R3tSWGSna0
#codeperformance#HPC
Sometimes the compilers opt out of loop unswitching for different reasons. If this is the case with your hot code, you can take the matters into your own hands and manually unswitch your hot loop. 👇
#codeperformance#HPC#compilers#vectorization
https://t.co/b9Ru1Gg7Xf
You don’t want to enable "fast-math" if #precision is important to you, but there are some compiler #flags that do not influence precision that will benefit the #performance that you can enable.
Read about them 👇
https://t.co/4UwwayOabg
Are you using all available #hardware resources in the most efficient way?⚙️
#CPU#GPU#vectorization#memory
Discover development techniques for using hardware efficiently and explore how our #ParallelwareAnalyzer tool can help you improve performance.
https://t.co/zNn3PmVndx
10 December:
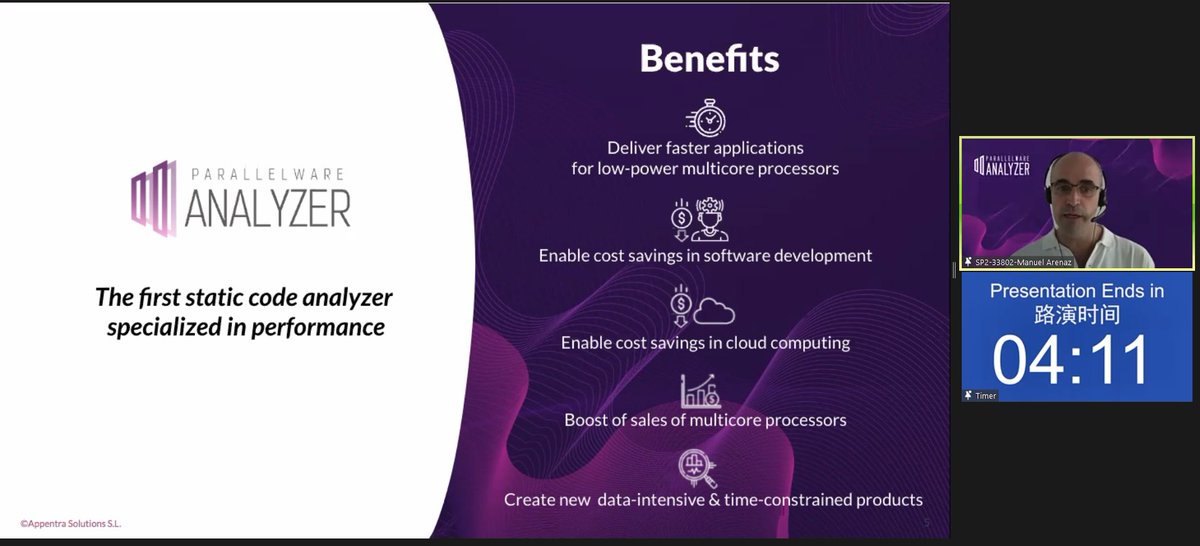
📊 1.30pm (GMT+8): Introduction to Parallelware Analyzer: The First Static Code Analyzer specializing in Performance 👉🏾 https://t.co/m0l6RyWPiy
@Appentra
As part of the #PaCER Conference @PawseyCentre – P’con: Setting the pace for exascale, Appentra will present on "Introduction to Parallelware Analyzer: The First Static Code Analyzer specializing in Performance".
Registration is open ✍️
https://t.co/FR4BAL21Gz
🎉 Proud that #Parallelware has been selected as an industrial #finalist to participate in the next round of the 5th China (Shenzhen) Innovation and Entrepreneurship International Competition!
#NewGenerationIT
https://t.co/s2VqIaltpi
Appentra presented #ParallelwareAnalyzer this morning at the finals of the 5th China (Shenzhen) Innovation & Entrepreneurship International Competition Spain Division.
Now it's time to see the other great selected projects.
Good luck to you all.🤞
La empresa @Appentra, impulsada por investigadores del @citicresearch, anuncia el lanzamiento oficial de #ParallelwareAnalyzer 1.0
👇
https://t.co/PjSyuwJMlb
👏The @HorizonEU MAESTRO project of which we are partners, has just launched the #MaestroCore software, C library that does multi-threaded cross-application data transfer over high-speed interconnect.
📁Clone the Appentra’s performance-demos repository and start experimenting to see how #ParallelwareAnalyzer helps you increase the performance of your code.🔗https://t.co/ipcqGuWMuH
#HPC#codeperformance
📢 We are happy to announce that @Appentra and @Fujitsu_ES signed a collaboration agreement to carry out projects that bring to the #supercomputing market a joint value proposition in the optimization of applications in #parallel computing systems.
https://t.co/qkTM0quoLM
The #EPEECproject is developing new recommendations and opportunities regarding #vectorization and use of #SIMD instructions in collaboration with @Appentra
➡ https://t.co/h6lkU0ogWh
Appentra is pleased to announce the appointment of Harry Dehaly as Head of Global Sales and Marketing. We are excited to start this new phase with Harry. Welcome to the team!
#HPC#codeperformance
https://t.co/WRORrPYarh
Join our live tutorial on '#OpenMP Common Core: Learning Parallelization of Real Applications from the Ground-Up' at #ISC21 on 🗓️ Friday 25th.
👉 You're still in time to register: https://t.co/q8r1qhCLle
@ISChpc #shapingtomorrow#HPC@OpenMP_ARB