Zero-shot instruction-following, nuanced classification and reasoning? ➡️ LLMs!
Real-world low-latency retrieval over a large-scale corpus? ➡️ Embedding models!
But what if you need BOTH at once? That's what our new paper 💡 is all about...
https://t.co/WmDM1JnZA1
🧵
🚨 Benchmarks tell us which model is better — but not why it fails.
For developers, this means tedious, manual error analysis. We're bridging that gap.
Meet CLEAR: an open-source tool for actionable error analysis of LLMs.
🧵👇
Unitxt has grown from a data preparation library to a cutting-edge evaluation platform in just one year.
The best part? Its just getting started. 🚀
Read the Unitxt 2024 Year in Review to learn more: https://t.co/bqlPBtG3xp.
#unitxt#llmevaluation
HELM just got a great upgrade!
We've integrated with Unitxt for:
Easy dataset addition
2x the datasets
Sharable & reproducible pipelines
Check out the blogpost: https://t.co/UJXwfPKzGN
And the unitxt repo
https://t.co/GeqMCoQhjv
@ElronBandel@YifanMai
Very excited to present 👏 ClapNQ our new benchmark dataset for RAG systems! Check out our GitHub: https://t.co/3vxMx09MRG and Paper: https://t.co/twLoU5u6YK and let me know what you think! #CLAPNQ#RAG#dataset#NaturalQuestions@aviaviavi__
Save yourselves the hours (or days) inferring all 64K examples, when using HELM
In https://t.co/O03C4z44yT we show that 160 examples 🤯🤯🤯 is enough to get a very good picture, #ComputeIsForTraining.
We share code on @github
We share datasets on @huggingface
But where do we share our data processing?
We each prompt, instruct, clean, and filter
but on our own🥺
Unitxt🦄
A community-based preprocessing tool
Let's make it great together
https://t.co/Pt3BIwcisu
@IBMResearch
Choosing between 2 generative models, by just a few human(\LM) comparisons.
Can this be done? Would the choice be reliable?
In our new work, led by @ShirAshuryTahan, we show the answer is yes✨
https://t.co/3H3JOpT9wG
The trick to it (contrastive representations) in the 🧵
Happy to share our paper:
Genie🧞: Achieving Human Parity
in Content-Grounded Datasets Generation
was accepted to #ICLR24
From your content
Genie creates content-grounded data
of magical quality ✨
Rivaling human-based datasets!
https://t.co/OJdVfrd9gr
IBM presents Unitxt
Flexible, Shareable and Reusable Data Preparation and Evaluation for Generative AI
paper page: https://t.co/DryLflbWME
In the dynamic landscape of generative NLP, traditional text processing pipelines limit research flexibility and reproducibility, as they are tailored to specific dataset, task, and model combinations. The escalating complexity, involving system prompts, model-specific formats, instructions, and more, calls for a shift to a structured, modular, and customizable solution. Addressing this need, we present Unitxt, an innovative library for customizable textual data preparation and evaluation tailored to generative language models. Unitxt natively integrates with common libraries like HuggingFace and LM-eval-harness and deconstructs processing flows into modular components, enabling easy customization and sharing between practitioners. These components encompass model-specific formats, task prompts, and many other comprehensive dataset processing definitions. The Unitxt-Catalog centralizes these components, fostering collaboration and exploration in modern textual data workflows. Beyond being a tool, Unitxt is a community-driven platform, empowering users to build, share, and advance their pipelines collaboratively.
🦾Cohere beats Davinci on HELM
😵💫But only if you also test Cohere medium
How reliable are our benchmarks really?
A fascinating :thread:on HELM,
Reliable benchmarks
& saving X100 compute
Are you up to it?
🧵
https://t.co/OQClOhnrWu
Label Sleuth, the no-code open source tool for labeling AND automatically building text classifiers now supports > 150 languages!!! 🌎🌍🌏
Come to see the demo: @IBMResearch booth at #ACL2023
(or https://t.co/JF1mMMh67m)
Curious to see how can we summarize opinions beyond plain text summaries?
Check out our #ACL2023 paper: From Key Points to Key Point Hierarchy: Structured and Expressive Opinion Summarization
with Lilach Eden, @yoavkantor@RoyBarHaim from @IBMResearch@IBM@biunlp
>>
Can you make an existing pretrained LM behave like a BIGGER pretrained LM?
Judging by our new paper on Auto-Contrastive Decoding, in some ways you can! 🤯
https://t.co/PvzSZO9qyE
@IBMResearch#acl2023#NLProc
Label Sleuth is now multi-lingual:
English, Arabic, Hebrew, Italian, Romanian.
With thousands of downloads, many joyfully label texts and build classifiers with this no-code, open-source system 🤖
https://t.co/gkOfXJabgB
@stefanoscotta @radubengulescu
#NLProc#NLP#ML
מה בעצם קרה הערב?
לפני ארבעה ימים בלבד, ניתן פסק דין בעתירה שהגישה התנועה לאיכות השלטון בנוגע להסדר ניגוד העניינים של רה"מ נתניהו.
בתשובה לעתירה, הודיעה היועמ"ש שהסדר ניגוד העניינים שערך היועמ"ש הקודם מנדלבליט – בעינו עומד. אבל, היא הוסיפה אמירה בנוגע ל-"רפורמה המשפטית". >>
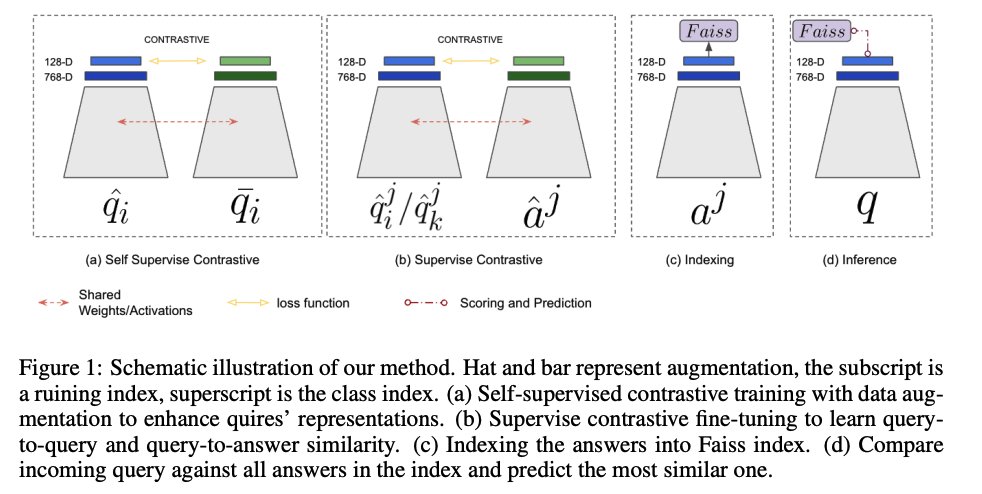
Looking for a new SOTA few-shot classifier?
We present QAID!
QAID uses batch contrastive learning with BERTScore &
classifies by retrieving the intent name.
SOTA on few-shot Intent Detection! 🎉
https://t.co/bMxNHwO0gc
Accepted to @iclr_conf 2023 🥳
#NLProc#NLP#ML
What happens when you combine Zero-shot Text Classification and Self-training?
You get:
Our new EMNLP paper https://t.co/QTJdGuRzb8,
Open sourced code https://t.co/1xJObdQEfO
Some great results ✨✨✨, and a thread 🧵
We want to pretrain🤞
Instead we finetune🚮😔
Could we collaborate?🤗
ColD Fusion:
🔄Recycle finetuning to multitask
➡️evolve pretrained models forever
On 35 datasets
+2% improvement over RoBERTa
+7% in few shot settings
🧵
#NLProc#MachinLearning#NLP#ML#modelRecyclying