Zero-shot instruction-following, nuanced classification and reasoning? ➡️ LLMs!
Real-world low-latency retrieval over a large-scale corpus? ➡️ Embedding models!
But what if you need BOTH at once? That's what our new paper 💡 is all about...
https://t.co/WmDM1JnZA1
🧵
Are you using Gaussian Mixture Models? Maybe now is a good time to start...
The best part about Gal's GMM kernel paper is that we demonstrate that the kernel doesn't just achieve a speedup - it opens new possibilities to do things that were previously unfeasible 🔥
Excited to share Flash-GMM, our new work from IBM Research on scaling Gaussian Mixture Models on GPUs 🚀
Paper: https://t.co/fOWZToMcX9
Code: https://t.co/1dPYk7dKuz
A simple idea inspired by FlashAttention enables GMMs to scale to billions of data points on a single GPU.
Task-Adaptive Embedding Refinement via Test-time LLM Guidance
IBM introduces a test-time query refinement method that uses LLM feedback on top-K documents to optimize query embeddings.
📝 https://t.co/L8O9d89pGk
👨🏽💻 https://t.co/Ujpy5yKBKH
@lateinteraction Very cool and timely work! @dianetc_
We just put out a paper that looks exactly at this gap - how to extend embedding pipelines to scenarios where only LLMs are good at judging relevance.
We use an LLM as a test-time teacher to adapt the query embedding:
https://t.co/Jg6CEFD6rO
Zero-shot instruction-following, nuanced classification and reasoning? ➡️ LLMs!
Real-world low-latency retrieval over a large-scale corpus? ➡️ Embedding models!
But what if you need BOTH at once? That's what our new paper 💡 is all about...
https://t.co/WmDM1JnZA1
🧵
Plus it's quite fun to watch queries as they gradually walk across embedding space based on the feedback signal 🧑🚀
A lot of cool future directions here: like understanding how LLM feedback rearranges the embeddings, or how to wisely select the set of documents for feedback
Zero-shot instruction-following, nuanced classification and reasoning? ➡️ LLMs!
Real-world low-latency retrieval over a large-scale corpus? ➡️ Embedding models!
But what if you need BOTH at once? That's what our new paper 💡 is all about...
https://t.co/WmDM1JnZA1
🧵
What is GQR you ask? A method that uses test-time gradient updates to boost retrieval quality at a low cost
And actually multimodal hybrid retrieval is just *one example* of why this is useful (more on that soon... 😉), so I highly recommend to play with this yourselves!
Happy to share that GQR was accepted to ICLR! 🇧🇷
We now also have a tutorial that introduces the algorithm in a friendlier way, along with new results and analysis in the paper. Check them out! See you in Rio!
https://t.co/Bv4cAVes14
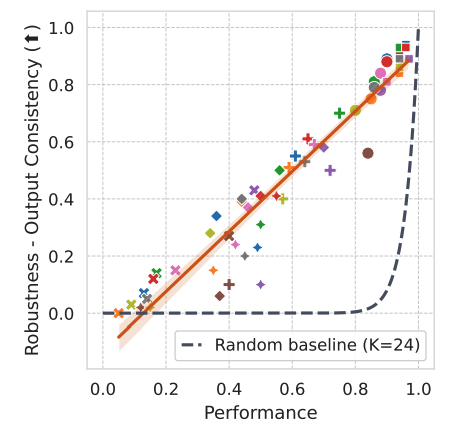
LLM "robustness" is often treated like a mysterious, standalone capability.
But what if it’s not? 🤔
Our new research shows robustness naturally appears when models truly understand a task - competence drives stability.
More details in the thread 👇
https://t.co/EQIj7ngASB
Why I really enjoyed this project:
It combines a lot: multimodality + hybrid retrieval + test-time optimization 🤯
At the same time, it is actually quite simple 💡
and helps to achieve more (retrieval quality) with less (compute resources) 🦾
plus @omri_uzan is pretty great
🚨 NEW PAPER 🚨
Guided Query Refinement (GQR) - a hybrid vision-text retrieval method that matches SOTA performance with 54× less memory and 14× faster inference on Visual Document Retrieval
🔗 https://t.co/DW9emLNIXl
📄 https://t.co/WqssZQ6Q9Y
🧵👇
The Generative Model Alignment team at IBM Research is looking for next summer interns! Two candidates for two topics
🍰Reinforcement Learning environments for LLMs
🐎Speculative and non-auto regressive generation for LLMs
interested/curious? DM / email [email protected]