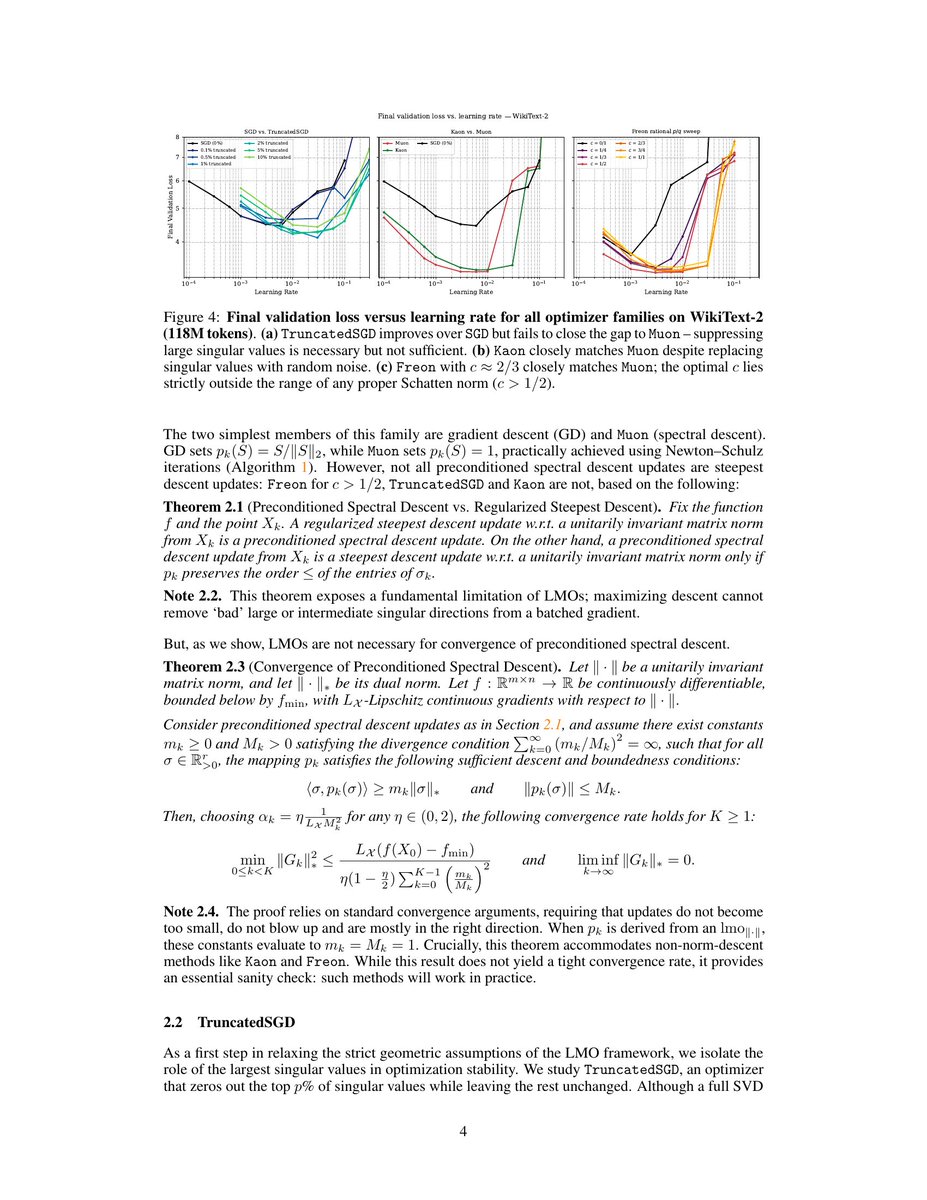
The Kaon thing is elegant, you dont need exact orthoginalization, you can replace SV with random values. It makes sense bc whats central to Muon is to upscale weak directions not getting to SV exactly 1. The point is to fast track low SVs to noticeable values >>
@octonion I dont think thats the right interpretation. The punishment is much too hard, especially if that's a single citation and especially as this might be collective punishment. (I check every citation i add and intend to keep on doing it, so I don't say it from a self serving pov)
You want a homogenous polynomial sequence that sends [0, 1] to [0, 1] and grows small values as fast as you can. Under the additional plausible assumption that we want p(1)=1, Muon is kinda special in that that such polynomial will be also the best approx to the polar factor
The Kaon thing is elegant, you dont need exact orthoginalization, you can replace SV with random values. It makes sense bc whats central to Muon is to upscale weak directions not getting to SV exactly 1. The point is to fast track low SVs to noticeable values >>
Even replacing singular values with random noise works in optimization. After considering Schatten norm updates that interpolate between SGD and Muon, we could push it further towards the quasi-norm regime. And interestingly it works.
The main point here is that the geometrical explanation maybe does not work.
Instead it is possible to think about the trade-off between alignment of gradients and potential of descent. If we sacrifice a bit of alignment but gain a large amount of descent with a proper learning rate it leads to acceleration.
@rosinality not random per se (chaotic map), but I think this corroborates earlier findings that "slope at 0" is mostly what matters (their ns-like iteration shares this property with standard muon updates)
@PoratEitan It is a projection to the subset of M with the additional (ugly) constraint that every slice is orthogonal. But my hunch is that this is gonna be good enough. I hope to test it tomorrow and add experiments. Also probably gonna elaborate and fix style
Introducing Aurora, a new optimizer for training frontier-scale models.
We train Aurora-1.1B, which achieves 100x data efficiency on open-source internet data. Despite having 25% fewer parameters, 2 orders of magnitude fewer training tokens, and using fully open-source internet-only data, Aurora matches Qwen3-1.7B on several benchmarks.
Aurora was developed after identifying a major failure mode that can occur under Muon, an increasingly popular optimizer that has shown strong gains over Adam(W). We find that Muon can cause a huge percentage of neurons to effectively die early in training, reducing effective network capacity so that many parameters no longer meaningfully contribute to network outputs.
By redistributing update energy more uniformly across neurons while preserving Muon’s stability properties, Aurora prevents neuron death and recovers substantial model capacity.
What makes this work especially exciting is that it points toward a broader direction for ML research: better optimizers may not come purely from elegant mathematical abstractions, but from understanding and addressing the concrete dynamics and pathologies that emerge inside real training systems.
@yoavgo I think that's a really good point, but it also points to an approximate workaround by creating an integrated document from all the steps (puritanically, you would probably want to recreate the code each time from the new document but ofc that would be theoretical)
@VictorTaelin I think there should be probably a good way to do this with search and smart apply (whether wisely applied standard skills or something ever so slightly more simple). If you have a workable knowledge tree that you feel is complex enough would love to take a crack at it