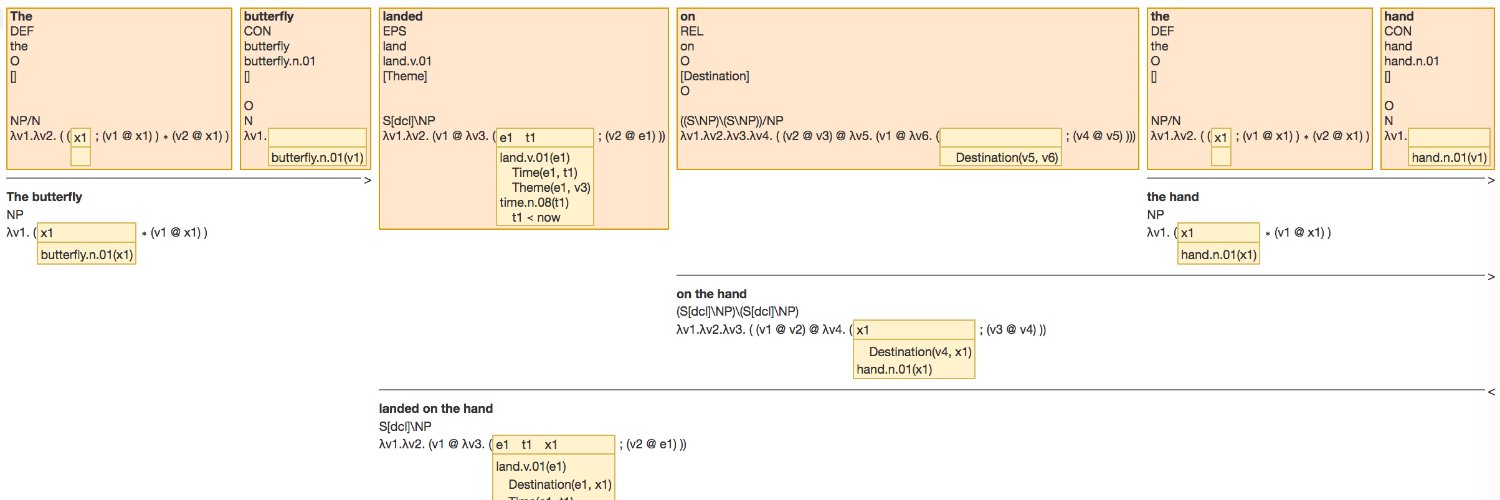
Impressive work by Bruno Guillaume on graph rewriting for computational semantics, including a very cool search interface for Parallel Meaning Bank data:
https://t.co/4f8aBwoJUs
@FiboKowalsky@andreasvc It actually is strictly standoff for the taggers and parsers in the PMB; there is always a connection between char offsets and derived tokens. If the token segmentation is changed, annotation is preserved for (unaffected) tokens even if the token indices have changed.
@andreasvc@FiboKowalsky Well, by definition the raw text shouldn't change! In your case the raw input isn't text, but an image of text. An interesting challenge.
About ten days left to apply! Don't miss out on this great opportunity to join our Computational Linguistics group in Groningen! #NLProc@univgroningen@FacultyofArtsUG
This month's ILFC seminar @GdrLift was on variable-free meaning representations, presenting a new format that provides easy human and machine annotation of meanings. Video and slides are available here:
https://t.co/Lszdxsgd8S
present.v.08 Agent +1 person.n.01 Name "Johan Bos"
@ryandcotterell Indeed the Parallel Meaning Bank has lambda-expressions attached to the CCG derivations. You can see them in the PMB Explorer (sentence tab, drs, then click on "unfold all"). And yes we could release them!
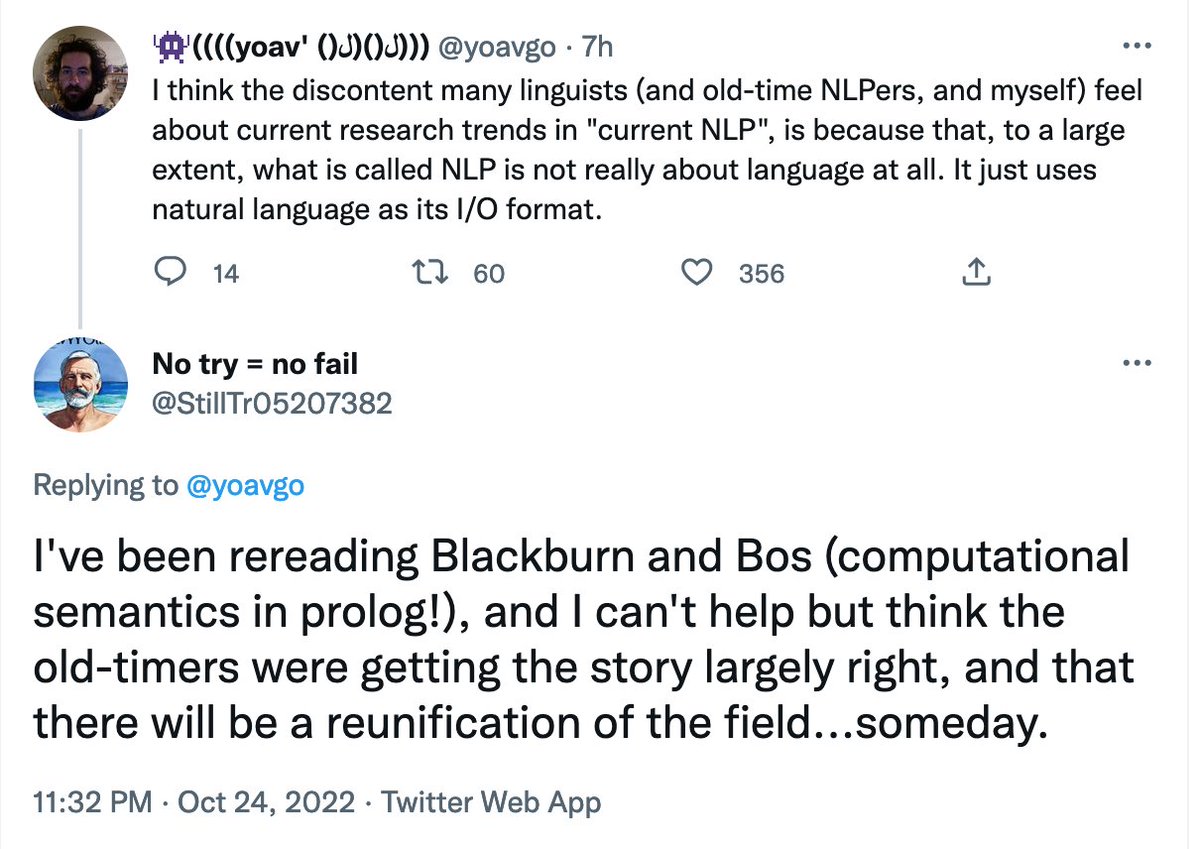
@zehavoc@FiboKowalsky@rikvannoord@evanmiltenburg@srchvrs@nasrinmmm@stanfordnlp@GroNlp If you click on "discourse" you get the entire picture. But I cheated here and added a bit of wisdom. Anyway, Boxer will not be able to resolve these Winograd pronouns in an "intelligent" way. Because it will need the knowledge that monkeys can be hungry and banana's can't.
@texttheater@evanmiltenburg@srchvrs@zehavoc@nasrinmmm@stanfordnlp@rikvannoord's Neural Boxer is of course available. And I think @Ginger_in_AI has a version of the classic (Prolog-based) Boxer in his github. There isn't much demand anymore, although recently I got a few more requests --maybe people are getting tired of the neural approaches?
We are looking for someone who can teach a 5 ECTS Human-Computer Interaction course in our Bachelor in Information Science (second year) at the University of Groningen, NL, in Feb-March 2022. Details 👇
@FiboKowalsky@GroNlp@FacultyofArtsUG Aha, good question! Because AMR/PENMAN has the expressive power required. Negation and universal quantification, for which DRS would be a better choice, is seldomly found within tombstone inscriptions... Plus: the simple structures of AMR are closer to RDF triples.
Just appeared in the International Journal of Digital Humanities: "A semantically annotated corpus of tombstone inscriptions", by Johan Bos @GroNlp@FacultyofArtsUG. Open access here:
https://t.co/QO4bbLVQt0
Meanings are represented by AMR-like structures!
Today we released a new stable version of the PMB data, version 4.0.0: https://t.co/uBBGqfRVgb
More gold data for English, Dutch, German and Italian, and lots of silver data.
📢 new Dr in the group! 🥳🥳🥳
We are proud to announce that our own Rik van Noord (@rikvannoord) successfully defended his thesis on neural semantic parsing yesterday, and was awarded a *cum laude* distinction! Congratulations, Rik!
Link to the thesis: https://t.co/wCv9oevNHE
We are hiring!
Are you a computational linguist who wants to work in a wonderful group? Then apply for this lecturer position in Groningen with us! Deadline May 9th, start date September 1st, all info at this link 👇
https://t.co/v5qYfoJESg #NLProc