🚀 MemOS Local Plugin 2.0 is LIVE — 1 memory engine, all Agents fully supported.
@NousResearch's Hermes and @openclaw both run on the same core from NOW on.
Add another Agent later? It's a thin adapter, not a fork
One severe issue kept coming back from users:
"An Agent can finish tasks, but can we trust what it learned?"
MemOS Local Plugin 2.0 is our answer: Execution as learning.
Not just storing chats, but turning each task step into reusable memory.
Plugin, CLI+Skill, MCP are not substitutes — they’re role-based
Plugin = deep native integration (“fully furnished” path)
MCP = standard protocol path when client support is strong
CLI + Skill = lightweight universal path wherever shell exists
Long-term memory should be callable by humans, scripts, and Agents through one shared command-line entry.
🌟 GitHub: https://t.co/yFb4jybizt
📃 Docs: https://t.co/IYSPfkLyuv
🚢 shipped MemOS CLI — bringing long-term memory to the command line 🧰
CLI is becoming the default entrypoint for Agent workflows.
Codex, @claudeai Code, @cursor_ai, and more local Agents already run via shell: code, scripts, tools, automations.
But memory integration is still fragmented:
framework-specific plugins, MCP client constraints, or custom glue code.
If your environment can run shell commands, you can now do everything about memory with one memos command >_
Real workflow impact + output formats
In OpenClaw LOCOMO tests:
📊 Using MemOS cloud service via CLI, token usage dropped by ~65.5%
📈 With MemOS cloud plugin + CLI, accuracy improved from 66.60% → 77.27%
CLI output is also workflow-ready:
· format markdown for docs in terminal
· format markdown for docs
· format agent for direct Agent context injection (default)
· format json for scripts/CI/automation
Same memory data, shaped for different consumers.
🛌 MemOS Dream is now open-sourced.
Let Agents grow while they sleep.
How they dream should be decided with the builders who use them.
Now memory systems are clearly moving in this direction:
@AnthropicAI added Dreams in Managed Agents.
@openclaw introduced Light / REM / Deep Dreaming.
But we didn’t want Dream to become just another background memory-cleanup feature.
The real question is:
What should an Agent dream about?
One retrieval pipeline, different memory sources, different rules.
MemOS just upgraded retrieval where it matters most: precision under real multi-source workloads.
What's new
☞ Filter field upgrade: no more one global filter for everything
☞ Now you can filter user memory, knowledgebase memory, and public memory separately in one query.
☞ Keyword retrieval optimization: better high-weight term extraction, fewer noisy tokens.
☞ Stricter identity guardrail: mandatory user_name validation to prevent accidentally broad cross-user queries.
Why it matters
In production agents, retrieval is rarely single-source.
You may need policy docs from a knowledge base, user chat history, and public announcements at the same time.
Old model: one filter for all cabinets.
New model: each cabinet gets its own sieve.
And how it works in practice
filter.knowledgebase for institutional docs
filter.user for user/session-scoped chat memory
filter.public for shared announcements
keyword chain now focuses more on signal, less on irrelevant words
user targeting is validated at entry, so scope stays correct
This release is less flashy than a new API, but it directly improves retrieval quality, safety, and controllability.
Feel free to plug-n-play 🤗
https://t.co/Vc5IxEYzat
Custom Skills are now first-class memory in MemOS.
"Memory as Assets" means more than storing history.
Now your team's proven SOPs, support playbooks, and troubleshooting guides can be uploaded as Skill files — and retrieved for agent execution.
What it does
- Upload custom Skill files to a knowledge base (URL or Base64 content)
- Retrieve custom Skills together with auto-generated Skills during memory search
- Let Agents call process knowledge, not just read reference docs
Why it matters
This shifts agents from “improvising each time” to “executing validated team workflows.”
Docs answer policy questions. Skills provide actionable step-by-step execution paths.
How it works
· Upload via API: /add/knowledgebase-file with "type": "skill"
· Or upload via Console: Knowledge Base -> target KB -> Upload Document -> Skill file
· At retrieval, pass knowledgebase_ids + include_skill: true to /search/memory
· For local/open-source, upload skill zip via /product/add (is_upload_skill: true) and retrieve with /product/search (include_skill_memory: true)
From memory to execution:
when a user asks for a 3-day-old headset return,
the agent can retrieve the return-handling skill and follow the exact flow
— verify order, check eligibility, and guide next steps.
Feel free to plug-n-play 🤗
https://t.co/VCxf2SIfam
Current pipeline inside MemOS:
add.after hook
☞ DreamSignalStore
☞ motive formation
☞ historical recall
☞ reflection
☞ InsightMemory + DreamDiary
We think the hard part of Dream is still unsolved.
Questions we’re actively exploring with the community:
• how motives should evolve over time
• when insights should decay or re-dream
• how conflicting reflections should coexist
• how Dream affects future Agent reasoning
• what “healthy memory evolution” even means
Contributions / ideas / experiments are all welcome 🫶🏻
Let’s Dream together ✨
📎 Help wanted issues: https://t.co/T31mcQIbqI
💻 GitHub: https://t.co/yFb4jybizt
📚 Docs: https://t.co/gP65yh0Syu
🛌 MemOS Dream is now open-sourced.
Let Agents grow while they sleep.
How they dream should be decided with the builders who use them.
Now memory systems are clearly moving in this direction:
@AnthropicAI added Dreams in Managed Agents.
@openclaw introduced Light / REM / Deep Dreaming.
But we didn’t want Dream to become just another background memory-cleanup feature.
The real question is:
What should an Agent dream about?
Most Dream-like systems today focus on reorganizing memories:
summarizing interactions, replaying recent context, or consolidating fragmented history.
MemOS Dream starts one layer deeper:
unfinished motives.
In real workflows,
the important thing is often not the interaction itself — but the recurring judgment pattern behind it.
For example:
“make it shorter”, “less AI tone”, “highlight outcomes”
may look like separate edits.
Dream may synthesize them into one reusable insight:
“This workflow is optimizing for emotional alignment,
not feature explanation.”
That changes future reasoning — not just future retrieval.
🚀 MemOS Local Plugin 2.0 is LIVE — 1 memory engine, all Agents fully supported.
@NousResearch's Hermes and @openclaw both run on the same core from NOW on.
Add another Agent later? It's a thin adapter, not a fork
One severe issue kept coming back from users:
"An Agent can finish tasks, but can we trust what it learned?"
MemOS Local Plugin 2.0 is our answer: Execution as learning.
Not just storing chats, but turning each task step into reusable memory.
Try it on a real task today — curious to hear what your Agent learns first.
📄 Docs: https://t.co/RcTvqwYf20
🌟 GitHub: https://t.co/KXO8RZcufp
#AIAgents#LLM#OpenSource#AgentMemory
🙏 Huge thanks to @ModelScope2022 — MemPrivacy is now launched on ModelScope 👾
🪄 MemPrivacy is a lite privacy-preserving model, built for edge-cloud AI agents.
Instead of full-masking or non-protection, we find the balance between readable data and privacy security.
By using typed placeholders like <Phone_Number_me> 💡
Your Agents getting sexier and your sensitive info ain't tell anybody outside 🔐
🎮 Welcome to plug-n-play
🤖 Models: https://t.co/v5ssXBuwHC
📄 Paper: https://t.co/9HVKQ3ckBX
Introducing MemPrivacy from @MemOS_dev, an open-source privacy layer for end-cloud Agent workflows. 🚀
Sensitive content is replaced with typed placeholders locally before reaching the cloud. The cloud reasons over <Health_Info_1> and <Email_1>, not your actual data. Local mapping restores real content on the way back.
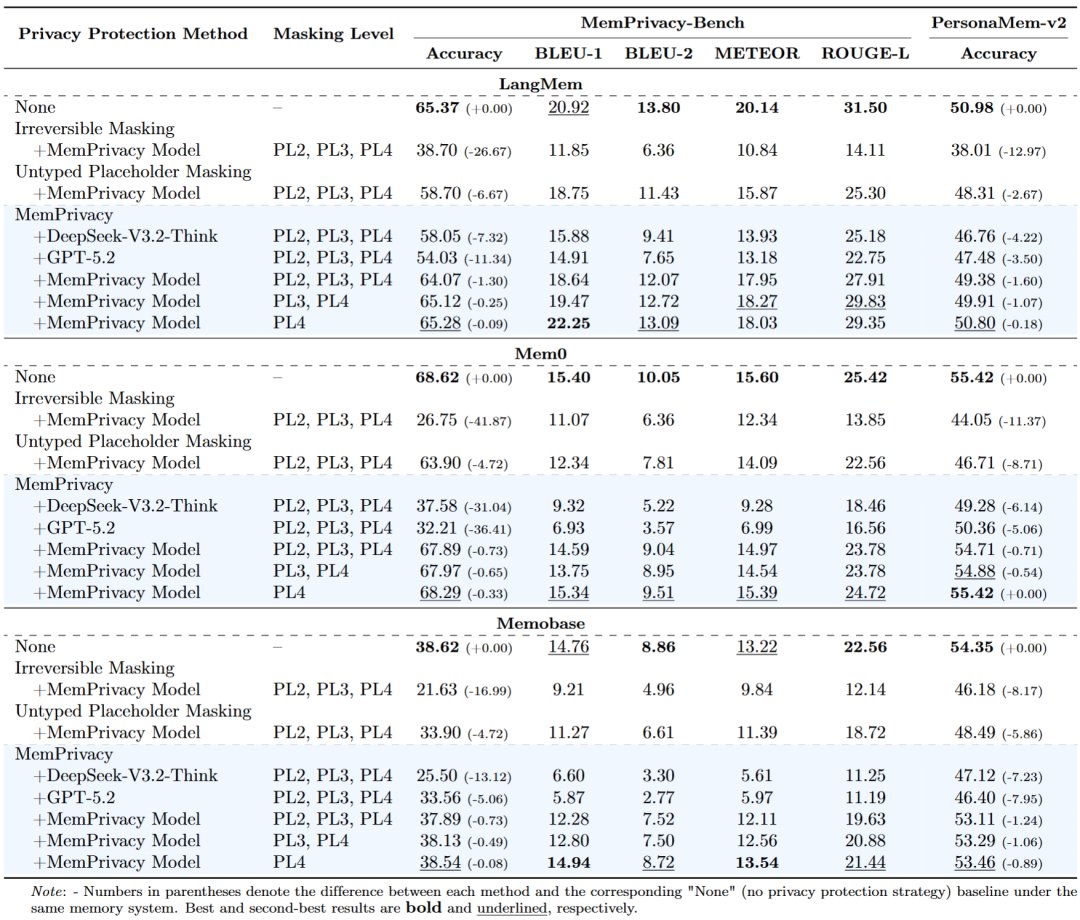
🎯 F1 85.97% on MemPrivacy-Bench vs OpenAI privacy-filter at 35.50%
📊 System utility loss held to 0.71%~1.60% at full protection — irreversible masking loses 17%~42%
🔒 4-level privacy classification: credentials and API keys get maximum protection, low-risk preferences stay usable
⚡ Qwen3-based, 0.6B / 1.7B / 4B. SFT + GRPO training.
🤖 https://t.co/S9NaMQma8w
📄 https://t.co/06pLYpDyWT
A 0.6B model just beat GPT-5.2 at privacy-protecting.
That's not the surprise. The surprise is: it doesn't make the cloud Agent dumber.
Today we're open-sourcing MemPrivacy — a privacy-preserving memory framework for cloud-edge Agents.
It keeps long-term memory and personalization on the cloud, while keeping the data that identifies you on your device.
2 weeks ago, @openai's privacy-filter made it clear: memory privacy is now core infrastructure for next-gen Agents.
Paper, code, and models below ↓
Benchmark results 📊
On MemPrivacy-Bench (200 users, 52K+ privacy items, bilingual):
- OpenAI privacy-filter: 35.50% F1
- GPT-5.2: 68.99% F1
- Gemini-3.1-Pro: 78.41% F1
- MemPrivacy-4B-RL: 85.97% F1
- MemPrivacy-0.6B-RL: 84.66% F1
System utility (GPT-4.1 across memory systems):
- Traditional masking: -26.67% / -41.87% / -16.99% accuracy
- MemPrivacy at PL2+PL3+PL4 full: -0.71% to -1.60%
- PL4-only: under -0.89% accuracy drop
Specialized small models outperform general LLMs on this task.