Husband | Entrepreneur & Investor | Bitcoin since 2016 | AGI & Contrarian Political Insights | 🇨🇦/acc | Civil Engineering | Currently tinkering in my home lab
GM!
It is not because things are difficult that we do not dare; it is because we do not dare that they are difficult.
Dare first, and the path becomes clear. Happy Friday, keep pushing!
@opengreenseas@Emilio2763 You have an insane misconception of overhead. If they have 7.8 mil remaining after lease and staff salaries, they are at a gross deficit.
We've just unveiled ERNIE 4.5 & X1! 🚀
As a deep-thinking reasoning model with multimodal capabilities, ERNIE X1 delivers performance on par with DeepSeek R1 at only half the price. Meanwhile, ERNIE 4.5 is our latest foundation model and new-generation native multimodal model.
Plus, our AI chatbot ERNIE Bot has now been made free to individual users ahead of schedule. Both models are now freely accessible to all ERNIE Bot users via its official website: https://t.co/hJjfLaKsEN.
Today, we release QwQ-32B, our new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning model, e.g., DeepSeek-R1.
Blog: https://t.co/jpNEx0Ck8p
HF: https://t.co/h91przQmoP
ModelScope: https://t.co/p0ztmZpWIZ
Demo: https://t.co/sxVVRFwunC
Qwen Chat: https://t.co/bg4tAU1p74
This time, we investigate recipes for scaling RL and have achieved some impressive results based on our Qwen2.5-32B. We find that RL training con continuously improve the performance especially in math and coding, and we observe that the continous scaling of RL can help a medium-size model achieve competitieve performance against gigantic MoE model. Feel free to chat with our new models and provide us feedback!
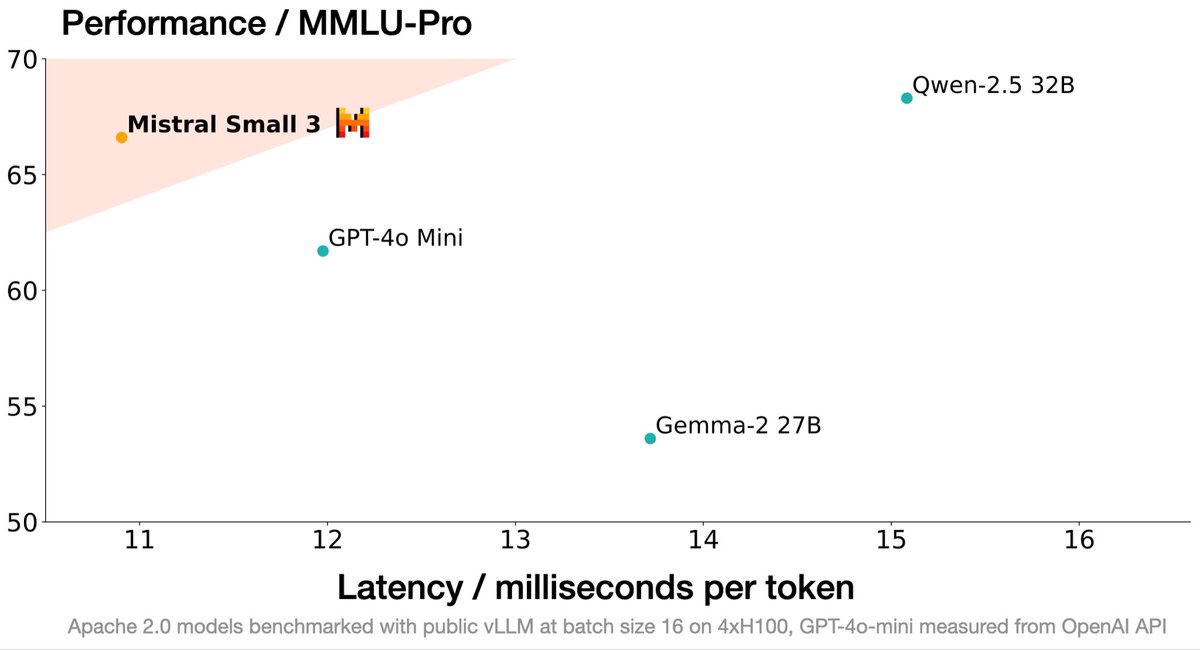
Mistral Small 3 is on par with Llama 3.3 70B Instruct, while being 3x faster on the same hardware (24B!). We’re experiencing something amazing, smaller models that have the same capabilities as larger models are coming.
Introducing Small 3, our most efficient and versatile model yet! Pre-trained and instructed version, Apache 2.0, 24B, 81% MMLU, 150 tok/s. No synthetic data so great base for anything reasoning - happy building!
https://t.co/8WfgzuuwRk