1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
An exciting milestone for AI in science: Our C2S-Scale 27B foundation model, built with @Yale and based on Gemma, generated a novel hypothesis about cancer cellular behavior, which scientists experimentally validated in living cells.
With more preclinical and clinical tests, this discovery may reveal a promising new pathway for developing therapies to fight cancer.
Thrilled to announce the world’s most capable differentially private LLM!
Huge congratulations to the entire team — and special kudos to Amer Sinha for his outstanding contributions.
Take a look!
https://t.co/0lb8bgl1Vp
VaultGemma is a release of an open model trained from scratch with differential privacy.
The blog post below and the full tech report linked from the tech report have some nice analyses to present a scaling law for differentially private language models:
Blog: https://t.co/lMEFxaNyvL
Paper: https://t.co/EtTa4toPK5
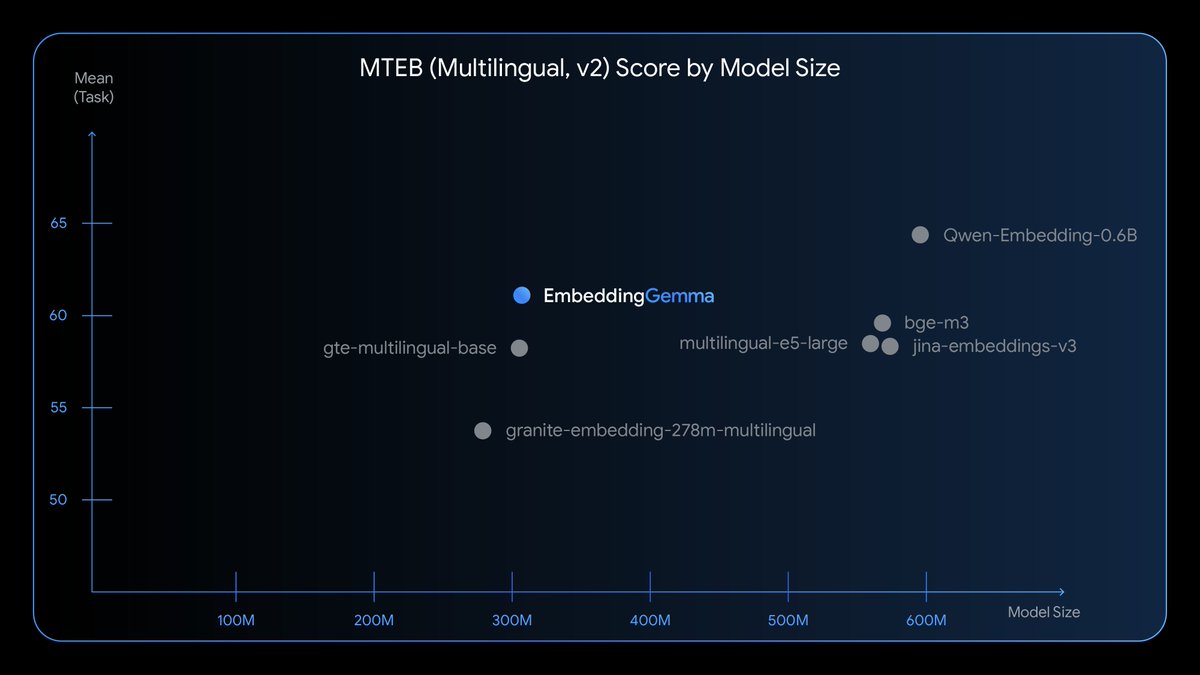
Introducing EmbeddingGemma, our newest open model that can run completely on-device. It's the top model under 500M parameters on the MTEB benchmark and comparable to models nearly 2x its size – enabling state-of-the-art embeddings for search, retrieval + more.
Introducing EmbeddingGemma🎉
🔥With only 308M params, this is the top open model under 500M
🌏Trained on 100+ languages
🪆Flexible embeddings (768 to 128 dims) with Matryoshka
🤗Works with your favorite open tools
🤏Runs with as little as 200MB
https://t.co/AXPqV4aXr1
🚀 After Gemma 3 1B, we’re going tiny: Gemma 270M — fast, on-device, low-power & privacy-first.
A new vision: smaller models with strong instruction-following & finetuning, ideal for low-latency edge apps & automation.
Congrats to everyone involved!
https://t.co/tu4kWimxQd
Introducing Gemma 3 270M 🔥
🤏A tiny model! Just 270 million parameters
🧠 Very strong instruction following
🤖 Fine-tune in just a few minutes, with a large vocabulary to serve as a high-quality foundation
https://t.co/E0BB5nlI1k
Looking for a small or medium sized VLM? PaliGemma 2 spans more than 150x of compute!
Not sure yet if you want to invest the time 🪄finetuning🪄 on your data? Give it a try with our ready-to-use "mix" checkpoints:
🤗 https://t.co/rdVkdRLmEo
🎤 https://t.co/lLsAVkANhI
PaliGemma 2 mix is an upgraded vision-language model that supports image captioning, OCR, image Q&A, object detection, and segmentation. With sizes from 3B-28B parameters, there's a model for everyone. Get started. → https://t.co/oqOy86gSjm
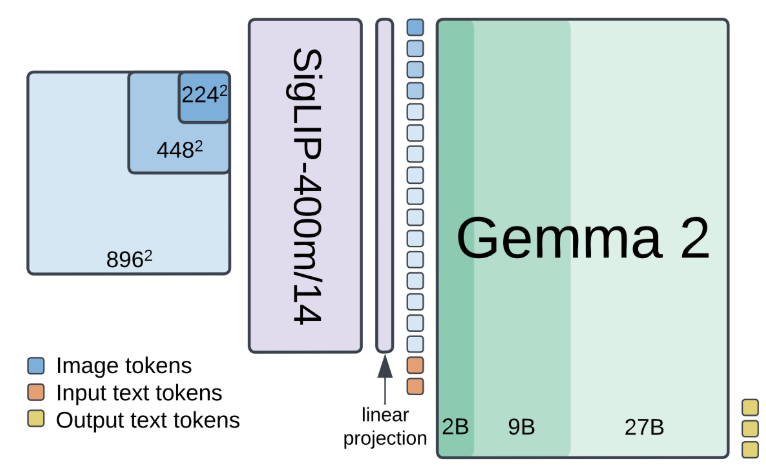
🚀🚀PaliGemma 2 is our updated and improved PaliGemma release using the Gemma 2 models and providing new pre-trained checkpoints for the full cross product of {224px,448px,896px} resolutions and {3B,10B,28B} model sizes.
1/7
Thrilled to announce the launch of PaliGemma 2, a state-of-the-art update to our PaliGemma vision-language models! These models are based on Gemma 2, and are available today in 2B, 9B, and 27B sizes.
https://t.co/25qKhJFJ0h
https://t.co/ygR2NJIzsT
📢 Exciting opportunity alert!
We (https://t.co/HTAe8sVRlR) just posted our annual research internship openings in computer vision & ML.
Check out the openings and the great achievements by our past interns here: https://t.co/Ka1XOml83s
Gemma 2 just got even better! 🚀 New Japanese-tuned 2B model AND a $150K Kaggle competition to build Gemma models for every language. Great to have @sundarpichai here to share the excitement!
Read more: https://t.co/nJGJ2hjDfE
#GemmaDeveloperDay