Excited to share our #NeurIPS2024 work on QueST: Self-Supervised Skill Abstractions for Learning Continuous Control🦾🤖
QueST is a multitask latent-variable model that learns sharable low-level skills and outperforms Diffusion Policy, ACT and VQ-BeT by >13% in 5-shot transfer.🧵
Nine out of ten drugs fail in clinical trials. The reason isn't a shortage of data. It's that none of it connects.
We started Atlas Discovery to fix that with foundation models of patient drug response. We're backed by @ycombinator, @pearvc, and more.
open sourcing Marlin-2B 🐟
a tiny VLM to extract structured information from videos
Marlin is finetuned for two questions devs want to ask in their videos: what is happening, and when?
Best open model in its weight class, competitive with Gemini-2.5-flash at only 2B params 🧵
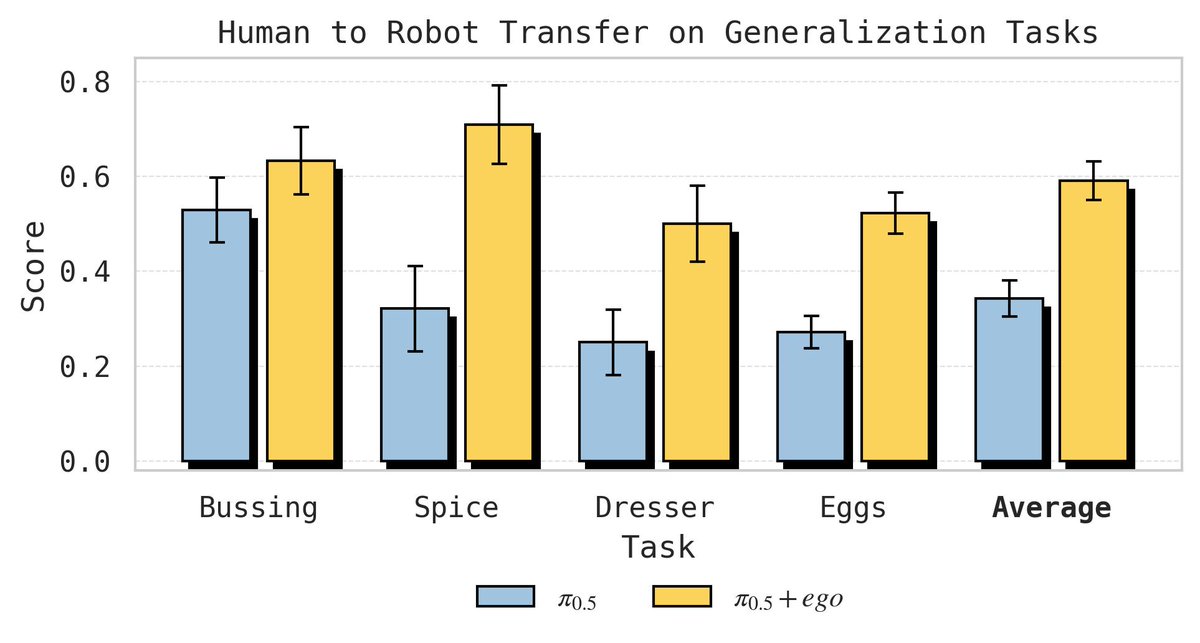
If we use our full pre-trained pi05 model, simply finetuning with human video data can double the performance on tasks that are depicted in the human videos!
Robots struggle to learn new skills from human videos.
Why? We found that naive co-training produces disjoint distributions.
Our EgoBridge (NeurIPS’25) extends Optimal Transport to align human-robot latents, improving success by 44% and generalization to human-only tasks!🧵
This is what I have been building for the last few months: a whole-body controller trained in Isaac Sim using RL. The ability to put the hands wherever they are needed and let the NN take steps and adjust stance as needed is a huge boost in capability for teleoperators + LfD.
Imitation learning has seen great success, but IL policies still struggle with OOD observations
We designed a 3D backbone, Adapt3R, that can combine with your favorite IL algorithm to enable zero-shot generalization to unseen embodiments and camera viewpoints!
Robotics data is expensive and slow to collect.
Robotics labs and companies spend months just to collect around 10k hours of demonstration data, all while that much video is uploaded to YouTube every 20 minutes. However, none of this video data contains action labels. How can we bridge the gap?
AMPLIFY solves this problem by learning Actionless Motion Priors that unlock better sample efficiency, generalization, and scaling for robot learning.
neurips deadline is in 14 days. do I have a paper? no. do I have an abstract? no. do i have compute? not even a little bit. do I have data? sorta. do I have "the self assurance that [I will] succeed where lesser men failed"? you bet your ass I do.
Tired of scrubbing through hours of footage to find the perfect clip? Shikai’s got your back! We’re building the world’s most *flexible* video search engine, all in open source @lossfunk !! 🚀✨
Check out how we did it on the recent @Project_11A video👇🧵
@NielsRogge This is the point of the training set, though -- to train your model on it. It would be even more impressive if the model had no prior exposure to ARC data, but the fact that the model was ARC-adapted via the training set absolutely does not invalidate its score.
Introducing EgoMimic - just wear a pair of Project Aria @meta_aria smart glasses 👓 to scale up your imitation learning datasets!
Check out what our robot can do.
A thread below👇