Introducing Agent Arena: real-world agentic evals at scale.
How do you evaluate agents doing actual work? We measure millions of live sessions where real users accomplish real tasks.
On Arena, models now get web search, filesystem, and terminal tools to complete complex workflows: writing code, creating slide deck, researching the web, building apps, and analyzing documents.
Every session produces rich signals. Users iterate with the agent turn-by-turn: approving, editing, correcting, praise or expressing frustration. The environment gives feedback too: shell errors, tool failures, recovery attempts, and more.
Our leaderboard measures each model's agentic performance using causal inference across five signals: task success, steerability, error recovery, user praise vs. complaint, and tool hallucination.
This leaderboard snapshot is built from 300K+ tasks, 2M+ tool calls, and 40M lines of code by agents.
Top labs in Agent Arena:
- #1 @OpenAI: GPT-5.5 (High)
- #2 @AnthropicAI: Claude-Opus-4.7 (Thinking)
- #3 @Zai_org: GLM-5.1
- #4 @GoogleDeepMind: Gemini-3.1-Pro
- #5 @Kimi_Moonshot: Kimi-K2.6
More analysis in the thread, with the full technical blog below.
Recent thoughts:
The Shift to Long-Horizon Tasks
The most likely breakthrough this year will be in long-horizon tasks. We are moving toward a stage where Large Language Models (LLMs) learn to complete extended, complex missions by interacting with Agent environments. This is perhaps where the true value of LLMs lies. Take cybersecurity as an example: imagine a model that continuously hunts for software bugs and vulnerabilities. While it sounds like a search process, it’s actually the model learning the high-level intuition and methodology of a professional hacker. Unlike humans, AI can run 24/7 without fatigue. It could potentially find exploits at a much higher frequwill ency and claim bounties on platforms like HackerOne or BugCrowd. It sounds fun, but fundamentally, it's a revolution that displaces the hacker. If even hackers are being "disrupted," one can only imagine the impact on general programmers.
From One-Person to None-Person Companies
Building on long-horizon capabilities, Autonomous Agent Systems (AAS) will inevitably become the next frontier. Last year, we were discussing the rise of the "One Person Company" (OPC). I didn't expect us to move so quickly toward the "None Person Company" (NPC). It’s an ironic twist—we might all end up as NPCs in this new ecosystem.
Engineering the Impossible: Memory and Learning
To realize the vision above, we must solve three technical pillars: Memory, Continual Learning, and Self-Judging.
I used to think these would require massive paradigm shifts and years of research. However, the pressure from both the technical and application sides is so intense that we are seeing these capabilities emerge through ingenious engineering "tricks":
Memory: Long context windows (1M+) and RAG have significantly bridged the gap.
Continual Learning: While true continual learning remains difficult, the release cycles are shrinking. Global models are updated monthly; domestic models are catching up. If we reach weekly updates by next year, it will effectively function as continual learning.
Self-Judging: This remains the most elusive, yet models like Opus 4.7 are already demonstrating early self-correction and judgment capabilities.
The Self-Evolving Endgame
The most difficult—and most promising—path is Self-Evolution. The current wave is incredibly fierce. I suspect that models like Claude may have already achieved a baseline for self-training: writing their own code, cleaning their own data, generating synthetic data, and then training on it. It might "waste" some compute, but it saves the most precious resources: human labor and time. In the LLM era, speed is everything. Rapid iteration is what creates the cognitive gap between leaders and followers. Claude’s rumored 2-million-chip cluster for next year is likely dedicated to exactly this: autonomous model self-training.
Technical Summary:
1M Context: Necessary baseline.
Memory & Continual Learning: Prerequisites, likely solved first via "tricky" engineering.
Harnessing Environments: The breakthrough point.
Self-Judging: The tipping point.
Full Self-Training: The endgame.
Redefining AGI and the Industry
If this is the road to AGI, then AGI’s definition should be the sum of all human collective intelligence, not just an individual’s intelligence. It must possess the creative capacity to produce something as profound as the "Theory of Relativity"—meeting the bar set by Hassabis.
During this transition, every APP will need to be reconstructed as AI-native. In fact, we might move past the concept of APPs entirely. The most significant challenge will be the reconstruction of the operating system itself. In the future, you won’t see a traditional desktop; you will see an LLM OS, where applications are "generated on demand." This challenges the 80-year-old Von Neumann architecture and represents a total upheaval of the computer science industry.
The Irreversible Wave
From completing long-horizon tasks to fully autonomous operations, every sector—Security, Finance, Law, E-commerce—will be reshaped. Many friends have reached out lately, asking how to transform their enterprises to keep pace with AI. But few truly realize that this irreversible process has already begun. As this massive technical wave hits, we must be prepared to act, but we must also start thinking seriously about how to regulate it.
Introducing GLM-5.1: The Next Level of Open Source
- Top-Tier Performance: #1 in open source and #3 globally across SWE-Bench Pro, Terminal-Bench, and NL2Repo.
- Built for Long-Horizon Tasks: Runs autonomously for 8 hours, refining strategies through thousands of iterations.
Blog: https://t.co/hmyDe4Nel3
Weights: https://t.co/CuUjXcPKJD
API: https://t.co/fz6reja4fb
Coding Plan: https://t.co/Nk8Y98HNhU
Coming to https://t.co/WCqWT0qCQb in the next few days.
AI hardware is starting to appear.
But running reliable agents is a different challenge.
Tool use.
Long tasks.
Multi-step workflows.
GLM-5-Turbo + OpenClaw now run inside the Mechrevo AI box
bringing native agent runtimes to devices.
We’re back.
After a short pause, https://t.co/ax4zXxvDd1 for startups is live again.
Our mission remains the same:
·Help founders build faster with AI
·Share real startup insights
·Support builders worldwide
If you're building an AI startup, follow us.
Big things coming.
🦞 Turn your AI into a research lobster
AMiner just dropped a free skill for OpenClaw that gives it deep academic superpowers.
Here: https://t.co/J8ECANyIoc"
New to OpenClaw? Start here → https://t.co/PIpfnh1jfg
#AI#AcademicResearch#OpenSource
The pace of open model innovation right now is incredible.
Respect to all the teams pushing the frontier forward:
@Zai@Alibaba@MoonshotAI@deepseek_ai@MistralAI@MiniMaxAI @LongCatAI @Xiaomi@StepFunAI @TrinityAI
Proud of the Z team — and proud to be part of this movement.
We’ll keep working even harder. 🚀
The best is yet to come.
#AI #LLM #OpenModels #GLM5 #ArenaLeaderboard #OpenSourceAI #AG
From Frontier to Real World: Why AI Winners Become Infrastructure Companies
For the past two years, the AI race has been all about Frontier: bigger models, higher benchmarks, longer context. But the truth is: frontier intelligence means nothing if it doesn’t move the real economy.
The lab is not the finish line. Training a SOTA model is an achievement, but deploying it into enterprises, workflows, agents, APIs, and production systems is the real game. The next winners won’t just train models — they will operationalize intelligence.
Raw model IQ is becoming commoditized. What won’t be commoditized: production reliability, scale efficiency, workflow integration, real-world alignment. A model is truly aligned only when it survives real users.
Agent-Native > Chat-Native. The real world isn’t chat. It’s workflows, memory, tool use, API orchestration, economic decisions. Frontier models must be built for production, not demos.
Distribution is the real moat. The winners will own developer ecosystems, enterprise pipelines, agent frameworks, and global infrastructure. Frontier → Infrastructure → Economy.
The new benchmark isn’t MMLU. It’s impact: workflows automated, agents deployed, cost eliminated, value created. The next giant won’t be smarter. It will be deployable.
Intelligence only matters when it compounds in the real world.
https://t.co/DRCwFHQQRn Startup Program is NOW OPEN.
What you can get:
·Free API credits
·Priority rate limits
·Exclusive Community
·Early API Access
Who we're looking for:
·AI-native startups
·Agent builders
·SaaS founders integrating LLM infra
·Global teams building for real-world scale
If you're building something that matters, don't wait!!
Apply now: https://t.co/jyS5zVZKQx
Questions? Details? Follow & DM @ZaiforStartups
@PeterSteinberger showing up in person to support the hackathon we co-hosted meant a lot. Founder energy matters.
Great job Damain ,I’m incredibly proud of you. You represented us on the ground, meeting so many passionate GLM5 and OpenClaw builders — that’s how ecosystems are built.
Hottest topic today? Not just bigger models — but agents that actually ship real work.
Question for the room:
Will agent frameworks capture more value than base models in this cycle?
Excited. Proud. Let’s build. 🚀
🚀 Own the Compute. Share the Growth.
https://t.co/pvQs8gPJTn’s Global Compute & Distribution Partner Program is live! We’re scaling GLM-5 fast and seeking partners to co-build, co-scale, and co-sell next-gen AI infrastructure.
DM to join us in shaping the AGI future.
#GLM5
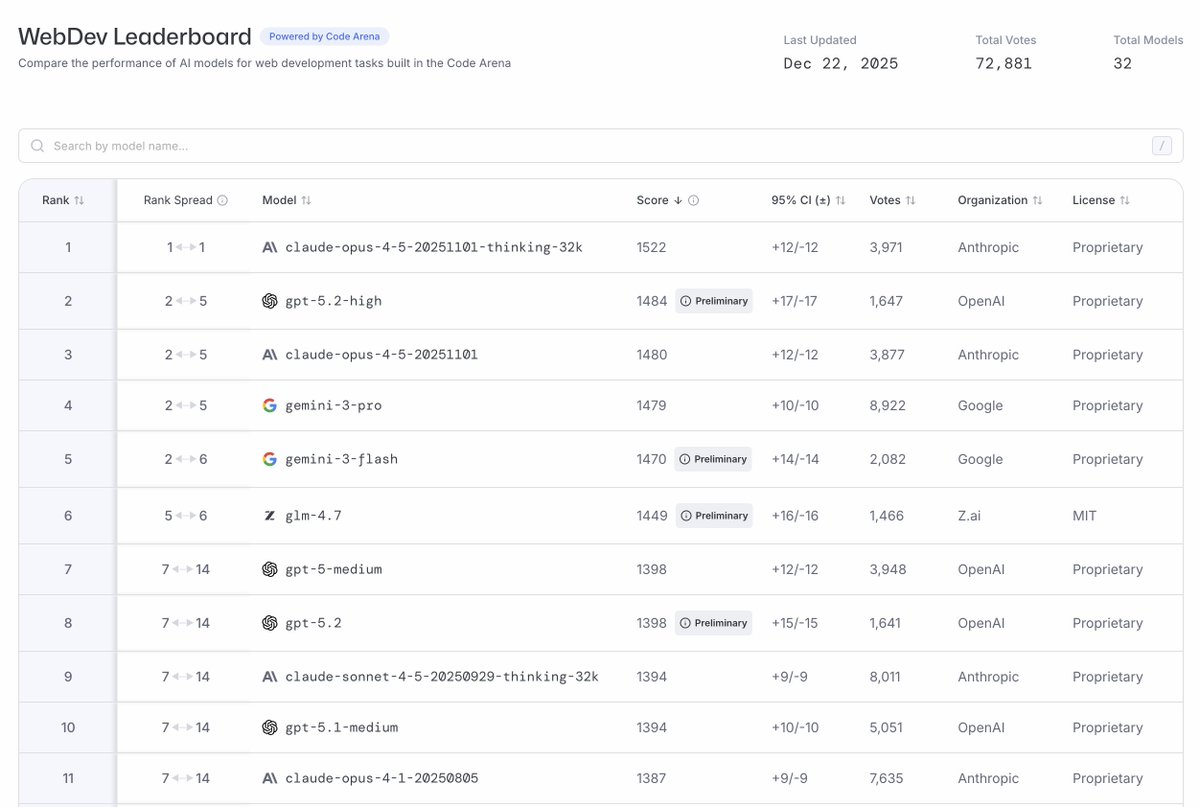
GLM-4.7 is ranked No. 1 among all open models. Key features:
-Core Coding: GLM-4.7 brings clear gains, compared to its predecessor GLM-4.6, in multilingual agentic coding and terminal-based tasks, including (73.8%, +5.8%) on SWE-bench, (66.7%, +12.9%) on SWE-bench Multilingual, and (41%, +16.5%) on Terminal Bench 2.0. GLM-4.7 also supports thinking before acting, with significant improvements on complex tasks in mainstream agent frameworks such as Claude Code, Kilo Code, Cline, and Roo Code.
-Vibe Coding: GLM-4.7 takes a major step forward in UI quality. It produces cleaner, more modern webpages and generates better-looking slides with more accurate layout and sizing.
-Tool Using: GLM-4.7 achieves significantly improvements in Tool using. Significant better performances can be seen on benchmarks such as τ^2-Bench and on web browsing via BrowseComp.
-Complex Reasoning: GLM-4.7 delivers a substantial boost in mathematical and reasoning capabilities, achieving (42.8%, +12.4%) on the HLE (Humanity’s Last Exam) benchmark compared to GLM-4.6.
ZAI is on fire. @Zai_org
Hot on the heels of GLM-4.6V, the team has dropped two more models on @huggingface:
- AutoGLM-Phone-9B: a 9-billion-parameter “foundation model for smartphones” that reads the screen and acts on your behalf. Small enough for on-device inference, big enough to feel like future.
- GLM-ASR-Nano-2512: a pocket-sized (2B) speech-recognition powerhouse that beats Whisper v3 on English, Mandarin, and Cantonese - It even picks up your whisper.
Grab them here:
- AutoGLM-Phone-9B → https://t.co/0Bt0DpLhv7
- GLM-ASR-Nano-2512 → https://t.co/HMe7BpR9rT
🌐❄️ Join the LBank Labs Winter Bootcamp 2024! 🚀
Embark on a transformative journey with the LBank Labs Winter Bootcamp, the ultimate destination for university students, alumni, and Web3 enthusiasts. Over four immersive days, you'll dive deep into the world of blockchain technology, decentralized applications, and the digital economy's future.
This bootcamp isn't just about learning; it's an opportunity to connect, innovate, and lead in the rapidly evolving Web3 space. And the best part? We're covering all your costs - it's totally free, including your stay and travel!
Whether you're a recent graduate looking to expand your horizons, a current student eager to get ahead, or simply passionate about Web3's potential, this bootcamp is designed for you. Engage with industry experts, network with peers, and take your first step toward mastering the decentralized world.
Spaces are limited, so don't wait! Apply by December 20 and get ready to experience the forefront of blockchain technology!
🗓️ Dates: February 15 – 18, 2024
📍 Location: To Be Announced, USA
🎓 Target Audience: Web3 Enthusiasts, University Students & Alumni
💡 Cost: Completely Free (including accommodations & transportation!)
⏳ Application Deadline: December 20
Apply here 🔗 https://t.co/b6GvNcWmPA
#Web3 #BlockchainEducation #LBankLabs #WinterBootcamp #CryptoCommunity