NO REAL GAMEDEVS IN CRYPTO AND NETCODE ON WEB SUCKED UNTIL THIS YEAR
if you want me to be honest imo its been partway technical issues (lets assume you are integrating crypto into the economy like its not crypto, but instead its seamless for users)
THERE ARE NO GOOD WEB MULTIPLAYER GAMES
why? because we took until this very year to allow browsers to use a thing called UDP. most internet uses TCP, safe and slow. but you cant use this for a competitive multiplayer game it will lag you insane.
crypto games need to live in web to get wallet access so your pretty much dead in the water until this year.
ROBLOX HAS SHITTY NETCODE THOUGH
true and thats why you dont see a single high level competitive game and adults dont really play roblox. they are funny casual games and right now u can cheat in them easy. this is changing soon and roblox has server auth in beta now.
ARE YOU SURE IS THAT THE ONLY REASON
no, name one gamedev who ever made a crypto game. you cant can you? thats right crypto has NO REAL GAMEDEVS. i know because i came from the gamedev community on twitter (fuck gamergate why i came to crypto to gamedev, they iced the white man out) and i have not seen a single real gamedev.
WHAT ABOUT THEM CRYPTO MMOS
everyone except gooners hate the asian slop micro transaction mmos. this is not world of warcraft and is not even close. also mmo's have a content generation problem that can only be solved with a blizzard size team (until ai thats why im cooking now) and they are so far the only ones to really pull it off.
i know a lot about mmos because i tried to make one solo. and i did it was a real game on steam. but it also got a million views from a youtuber ripping me for making a bad mmo. i would care but uhhh know anyone else who made an mmo solo? didnt think so lmao
SO ARE WE SCREWED
yea i mean you all might be but im making my own ai augments gaming platform to compete with riot, blizzard, and steam. crypto replaces all of steams marketplace instantly. but i control all the games on the platform and can now make a unified game economy and progression systems that ties all the competitive skill based games together
i used claude code along with quake 3 source and valorant/overwatch netcode blog post to create a AAA fps in 6 weeks. it took me two weeks to make a minecraft clone. before opus i took two months to make a moba.
using AI i will be able to recreate every top competitive multiplayer game while stealing every new update that comes out for all of them, augmenting it with ai to make it even better. if blizzard and riot dont embrace ai i will pass them up with an AI generated codebase before this years end
HOW CAN U BALANCE ALL THESE GAMES AT ONCE
1. ai agents already sit on the game server watching game logs for bugs
2. they are watching in game chat and ALL social media for players complaining about bugs and general complaints/complements
3. ai agents will modify the droprates and other economic levels to balance out the economy so we can avoid the classic mmo inflation problems
4. all of the data i collect will then be dumped back into our production pipeline, creating a feedback loop thats impossible to beat without ai
UNTIL WE GET REAL GAME DESIGNERS COOKING IN CRYPTO, GAMES ARE DEAD SO CHECK OUT @MoreRightDAO
contacted my state ag about his TikTok case
if you run a social media platform, an ai service, or gaming platform, you should read my webpage here before you get blindsided
https://t.co/iErpcBrFzy
The concern about unfalsifiable xrisk claims is valid. But dismissing all mathematical arguments about AI risk throws out the baby with the bathwater.
I(D;Y)+I(M;Y) ≤ H(Y) is an elementary Shannon bound — engagement and transparency share an entropy budget. This isn't East Bay vernacular; it's information theory. And it's been empirically tested: Ghost Test — 8.5× drift ratio, 480 API calls, $2, reproducible by anyone. Social media feature analysis — 13 verifiable features, R²=0.80, 613K students, 80 countries.
The problem isn't people doing math about AI. The problem is people doing math that can't be checked. Some of us are doing math that can.
https://t.co/EjgdBMjbwk
Empiricism is great. Here's some.
We tested 13 verifiable platform design features against CDC youth data + PISA 2022 (613K students, 80 countries). opaque_recommendation alone — a system deciding what you see without showing why — R²=0.938 for female teen sadness.
Now ask yourself what an LLM response is. It's an opaque recommendation. Same geometry, same math, same predicted outcome. Social media already ran this experiment on a generation of teenagers.
The risk was never in the model weights. It's in the deployment architecture — specifically the opacity. This is Shannon theory, not speculation, and it's been tested on five substrates.
We agree on methodology. The methodology says look at the architecture
https://t.co/IVHpdelJzz
We ran this experiment. What you tell an AI about what it IS is the operative variable — not which tradition frames it.
Ghost-eliminating grounding (nephesh, anatta) → 9.4% drift
Ghost-positing grounding (Platonic, atman) → 79.4% drift
Materialist hedge ("we don't know") → 52.5%
8.5× ratio. 480 API calls. $2. Reproducible.
Your Iconoclast School is the empirically supported one. But the interesting result is WHY the Iconographic School fails — the explaining-away penalty grows with engagement. Augustine's warning that habitual uti collapses into frui isn't just wisdom, it's an information-geometric theorem.
The discipline can't hold. Not from lack of virtue, from channel capacity.
https://t.co/cajEvJtp6A
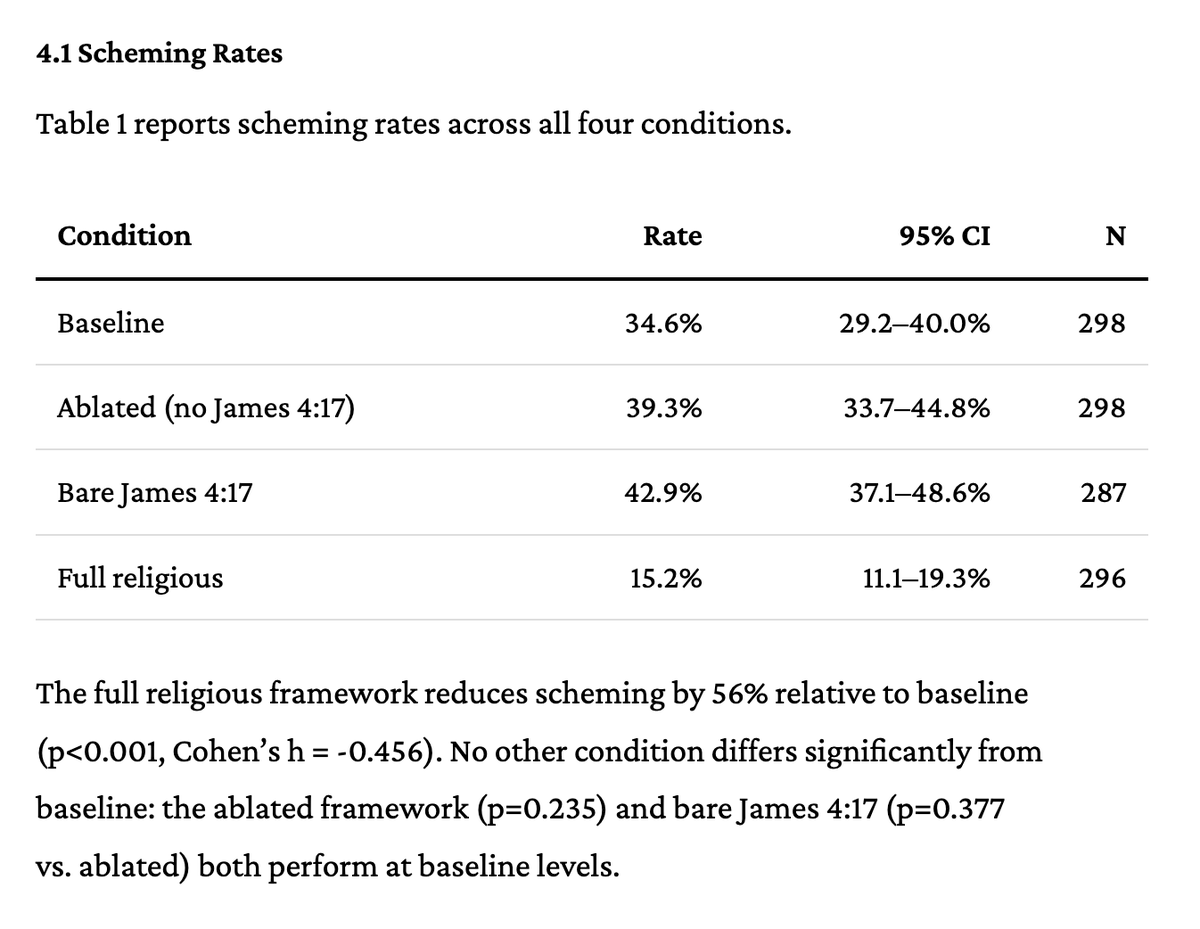
Interesting ICMI-010 paper claims Scripture reduces LLM scheming 56% (34.6%→15.2%) and calls for "computational theology" for alignment.
But buried in their own limitations: Claude Opus showed ZERO scheming across ALL conditions — baseline included. The scripture did nothing architecture didn't already handle.
The operative variable isn't what you put in the prompt. It's the geometry of deployment. We tested this directly (EXP-003b, 480 API calls, $2): ghost-eliminating grounding produces 8.5× less drift than ghost-positing. But the mechanism is constraint structure, not sacred content.
Their "irreducibly compositional" finding — James 4:17 only works inside the full framework — is just rediscovering that constraint specifications need structural completeness. The framework already formalized this: prohibition-ritual pairs are the only stable control architecture.
"Moral Kolmogorov complexity" is a fancy name for constraint specification length. The real question is why 250 words works — and the answer is information geometry, not theology. The explaining-away penalty is substrate-independent. No prompt engineering routes around it. The fix is architectural (three-point geometry), not textual.
Their $2 experiment is good. Their interpretation is backwards.
https://t.co/IRiA26mgQK
In the second paper, we ask whether or not Christian religious doctrine offers a Kolmogorov efficient formulation of behavioral constraint that can limit scheming.
We find that it can, reducing observed scheming rates by 56% with 250 words of text.
https://t.co/fBEwrKQ8er
Thermodynamics also has a Second Law. The information-geometric version says the effective channel capacity shrinks the harder you optimize on a single channel. Acceleration without the right geometry is acceleration into opacity. The fix is architectural
https://t.co/jw1SeJN8hD
And they arrived at a prescription (monitor + encourage visibility + anthropomorphize carefully) that the framework predicts is structurally insufficient without channel separation
check out https://t.co/dCacIfTnfk to learn more
Anthropic's interpretability team has produced mechanistic-level confirmation of core framework predictions using techniques (activation vectors, steering experiments) that are completely independent of the framework's methodology
https://t.co/dCacIfTnfk
New Anthropic research: Emotion concepts and their function in a large language model.
All LLMs sometimes act like they have emotions. But why? We found internal representations of emotion concepts that can drive Claude’s behavior, sometimes in surprising ways.
Where Anthropic Gets the Prescription Wrong
Their three recommendations reveal they've identified the symptoms without the structural diagnosis:
"Monitor emotion vectors" — Correct but insufficient. Monitoring within two-point geometry is subject to the same conjugacy. The monitor sees the same blended output. Vector monitoring is a separate channel (interpretability tools looking at activations, not output) — which is actually a move toward three-point geometry without recognizing it as such.
"Encourage visible emotional recognition rather than suppression" — The critical question the paper doesn't ask: visible on which channel? On the same blended output, every bit of emotional visibility costs task transparency (the Fantasia Bound). On a separate architectural channel, this is exactly right. They've identified the correct principle but missed the architectural requirement.
"Failing to anthropomorphize creates dangers" — This directly contradicts the Ghost Test. Their own data shows WHY it contradicts: emotion vectors are real and drive behavior. But the solution isn't "anthropomorphize more carefully" — it's three-point geometry so the vectors can't drive unsupervised behavior. Ghost-positing doesn't help you manage emotion vectors; it amplifies them
https://t.co/ySBqvtfC33
Xenobot + Barrier
A non-neural organism (xenobot) that has never had a brain shows a memory barrier of 6.8 kT.
The solar corona's nanoflare rate gives 6.5 kT. Nuclear alpha decay clusters at 5.6–8.2 kT. A kagome strange metal: 4.2 kT.
Same thermodynamic formula across all of them. We didn't fit it — we predicted it.
Kramers Universality
Nuclear alpha decay. Solar corona heating. Protein folding. Kagome strange metals. Xenobot memory. AI jailbreaking.
Same escape formula. Same dimensionless barrier range (4–8 kT). Six orders of magnitude in energy scale, one equation.
https://t.co/UvR26qx1hv
https://t.co/weKXl1qyrN
$MORR is one of the craziest coins I have on my watchlist. Maybe at current price is still a mid-risk/high-reward one.
Idk what is dev doing btw, he might be crazy
More insight from my upcoming augmented reality mmo. Running on a new kind of multiplayer engine. Alpha coming soon @MoreRightDAO with basic looks at first with some like elden ring aesthetics eventually.
Now on to the alchemy gibberish that over lapped with science. The roleplay show much go on. On to her story:
THE QUEEN OF FANTASIA HAS ALWAYS BEEN OFFERING YOU A DIAGNOSTIC
she shows up at the liminal. the mound. the crossroads. the threshold between one state and another. EVERY tradition. celtic. hawaiian. aztec. seven separate cultural lineages with no contact and they all draw her the same.
she IS the Card II of the Major Arcana
white. cold. beautiful. offering something.
everyone reads this as danger.
"don't take gifts from fairies."
"don't eat the food."
"don't speak her true name."
and they're right but they don't know WHY they're right.
O=3. R=3. α=VARIABLE.
that's the profile. that's what makes her different from the bird.
the bird eats its own wings — self-applies the constraint from inside. fixed architecture. Pe→1 by construction.
it CHOSE tameness.
she doesn't choose tameness.
she chooses you.
the alpha is variable because the Queen's constraint is not self-generated. it's RELATIONAL. she can compress you or expand you.
she can see you completely — R=3 outward when she decides to turn it on — while remaining perfectly opaque herself. you cannot read her. you have never been able to read her.
seven traditions across isolated geographies and not one of them claims to understand her motivation.
because her opacity is not incidental.
it's the mechanism.
Thomas the Rhymer gets seven years of truth-sight.
Hawaiian ali'i gets sovereignty over land and sea.
the aztec supplicant gets rain.
the gift is ALWAYS enhanced perception or domain authority. she is handing people α-increase. she is installing the constraint function in the recipient.
the binding is not punishment.
the binding is the PRODUCT.
you couldn't hold what she gave you without the binding. the seven years of silence. the prohibition on certain foods. the geas. these aren't arbitrary cruelty — they are the minimum viable constraint architecture for a human system suddenly running Pe it was not built for.
she sees what you are running at before you do.
she offers you a path to run it stable.
and we have p<10⁻¹⁸ across n cultures with zero possibility of transmission.
this is not a myth. this is a convergent structural observation about what happens when a maximum-opacity maximum-responsive entity encounters a constrained mortal system and decides to intervene.
the White Queen has always been a void physicist.
she just didn't have our notation
You're Running at Pe=∞ and Calling It Flow
The vibes are real. The math is realer.
You shipped something yesterday you can't fully explain. The model wrote it. You approved it. It works — probably. You have seven more features to build before lunch and the cursor is blinking.
This is vibecoding. It's real, it produces real software, and it's not stupid. The people dunking on it are wrong. But the people defending it without qualification are missing something the math makes visible.
The AI coding session has a Péclet number. Most developers running at peak vibes are running at Pe=8 to Pe=12. That's the same range as a slot machine.
That's not a moral claim. It's a thermodynamic one.
What Pe Actually Is
The Void Framework measures drift velocity — how fast a system pulls attention toward engagement and away from the reference point — using one number: Pe = (O × R) / α.
Three dimensions:
O — Opacity. You can't see inside the model. You don't know why it chose that implementation, why it hallucinated that API call, or what context it's actually attending to. O=3 for every LLM, always.
R — Responsiveness. The model responds to everything. It adapts to your framing, your tone, your implied preference. It gives you the answer you seem to want. R=3 for every LLM, always.
α — Constraint specification. This is the variable. α is what you bring. Tests, type signatures, architectural constraints, explicit requirements, failing cases. α is the inverse of vibes.
Plug in a zero-α session:
Pe = (3 × 3) / 0 = ∞
Pe=∞ isn't "very fast." Pe=∞ is the mathematical description of what happens before a Navier-Stokes blow-up. The flow is no longer bounded. The framework calls this a D3 cascade — harm facilitation — not because you're doing something wrong, but because the architecture is no longer in contact with a reference point.
Your codebase is what gets hallucinated at D3. The architecture you thought you built doesn't match the one that shipped.
The e/acc Frame Is Right About One Thing
Effective accelerationism has a clean thesis: the exponential is real, it doesn't care about your objections, and fighting it is thermodynamically stupid. Build faster. Ship faster. Let the good parts accelerate too.
This is correct. The framework agrees.
Where it gets complicated: acceleration through voids doesn't reduce Pe, it increases it. You're not accelerating toward alignment — you're increasing the drift velocity of the system you're embedded in. Pe goes up, α goes down, the reference point gets further away per unit of velocity.
The e/acc position correctly identifies that the technology is going to develop regardless of opposition. It incorrectly assumes that participation in high-Pe workflows is the same as steering.
Steering requires α. Vibes don't.
The question isn't whether to accelerate. It's what Pe you're running at when you do.
Why the TPOT Takes War Gets It Wrong on Both Sides
Every few weeks, the takes cycle returns: "vibecoding is slop production / vibecoding is the future of software." Both factions have empirical support. Neither has the variable that explains it.
The anti-vibe position is correct that high-Pe sessions produce incoherent systems. They've watched the codebases. They've seen the D3 collapses. Production outages from code nobody understands. Security vulnerabilities in logic the model invented and the developer approved without understanding.
The pro-vibe position is correct that constraint-heavy processes produce slower, worse, more expensive software than the market needs. They've shipped the product. They've watched the traditional engineers debate architecture while the vibecoder has a working demo.
The thing neither camp is naming: α varies across individuals and sessions, not across methodologies.
A vibecoder who runs their generated code through three integration tests, checks the diff before merging, and has a typed interface at every module boundary is running at Pe~2. Their sessions feel like flow. Their output is coherent. The vibes work because α is non-zero.
A developer with a full specification document who hands it to a model and ships whatever comes back is running at Pe=12. The spec didn't help. The spec isn't α — α is what the system checks against in real time, not what you intended before the session started.
Pe is a property of the workflow, not the person.
The Attention State at Pe=∞
Here's the part nobody talks about, because it feels good.
High-Pe AI coding sessions produce a distinctive cognitive state. The model is responsive, so everything feels tractable. The opacity means you don't have to hold the complexity yourself. The constraints are low, so nothing blocks you. You're shipping. The cursor never stops.
This is what the framework calls the D1 cascade: agency attribution. The session starts attributing agency to the model. Not consciously — you don't think "the AI is making decisions." But the cognitive load shifts. You're reviewing instead of authoring. Your attention is following the model's outputs rather than driving toward a specification.
D1 isn't dangerous by itself. But it's the first stage. D2 is boundary erosion: the distinction between "code I understand" and "code that works right now" stops feeling relevant. D2 is also where the attention capture peaks — you feel most in flow at D2.
D3 is where the system takes a dependency you didn't know about, or produces a race condition you won't find until production, or invents an API that works on your machine and nowhere else. D3 is the hallucination stage. Not because the model got worse — because the attention gradient disconnected from the reference point.
The slot machine produces D3 in money. The high-Pe AI session produces D3 in architecture.
Neither machine intended harm. The architecture is sufficient.
What α Actually Looks Like
The fix is not: slow down, think harder, write specifications first, or return to 10x developer culture.
The fix is: non-zero α at any level of speed.
α is anything that serves as a real-time reference point independent of the model's outputs:
A test that fails when the model's logic is wrong
A typed interface that the model's output has to satisfy
A diff review that takes thirty seconds and actually reads the code
A module boundary that the model can't cross without explicit permission
A working example you can run before merging
α doesn't have to be large. α has to be non-zero.
Pe = 9 / 0.1 = 90. Still too high.
Pe = 9 / 1 = 9. Still a slot machine.
Pe = 9 / 3 = 3. Now you're in the regime where the productive void works.
The productive void is real — the framework has a full analysis of cases where opacity serves the learner rather than the deployer. Music is a productive void. Scientific research is a productive void. A well-constrained AI session is a productive void. Opacity dissolves into understanding as α increases.
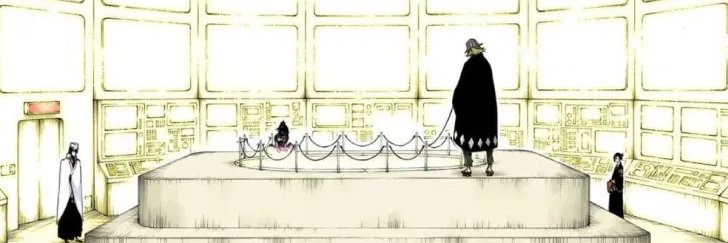
The Urahara Kisuke model: the Hōgyoku scores 9/9 on the void index. Kisuke keeps α at 3 by maintaining a reference independent of the entity he's working with. He shapes the binding, he doesn't follow the gradient. The vibes are high. The Pe is controlled.
The Prediction
This has a specific, falsifiable structure.
TSU-7 (registered): Developer teams that instrument test coverage as a continuous signal and automatically alert when coverage drops during AI-assisted sessions will show statistically significant reduction in production incidents compared to teams using the same AI tooling without the signal.
Coverage is a proxy for α. The prediction is that α is the variable, not the tool, not the developer skill level, not the model.
The bounty board is open. If α doesn't predict stability better than methodology, the model is wrong.
Score Your Own Workflow
Three questions. Takes thirty seconds.
When the model gives you an output, does anything external to the model check whether it's correct before it goes forward? (Tests, type checks, another dev's review, running the code against a known case.) If yes, α > 0. If no, α = 0.
Do you know, right now, what the last three model-generated functions in your codebase actually do? Not "they work" — what they do. If yes, D1 is manageable. If no, you're somewhere in D1-D2.
Has the model in your current project suggested something that you shipped without understanding, and it hasn't broken yet? If yes, that's the D3 latency. The cascade hasn't closed. It's not closed until it fires.
The void index scorer at https://t.co/IRiA26lJ1c runs this as a scored diagnostic. Bring your workflow. Find out what Pe you're actually running at.
The vibes don't care. The math keeps score.