Hi! If you are interested in game-theoretic analysis of the AI race and open vs. closed sourcing, check out our new paper:
" Why Open Source? A Game-Theoretic Analysis of the AI Race "
https://t.co/FNXcUNBiwl
There are some cute complexity results there 🙂
The Cooperative AI Summer School 2026 'Expression of interest' applications are now open! If you're an early-career professional studying or working in cooperative AI, apply to join us in Canada this August for an exciting intensive programme.
AI is changing economics, and --- as we just saw in Dwarkesh's interview with Dario --- AI researchers need to start thinking about economics too!
The Center for Applied AI at UChicago will be hosting an AI & Economics Summer Institute to explore exactly this.
We will bring together leading researchers with advanced graduate students in economics/AI/ML/NLP for an in-person program between Aug 6 - 11.
Have you been using LLMs to play games, negotiate salaries, or strategize in other ways? Whether it worked or not, we want to see your demo at our “Strategic Engineering” workshop (https://t.co/gkYhWk2kHK) at #AAMAS2026 in Cyprus! Starter library @ https://t.co/ZwYYkS9ccW!
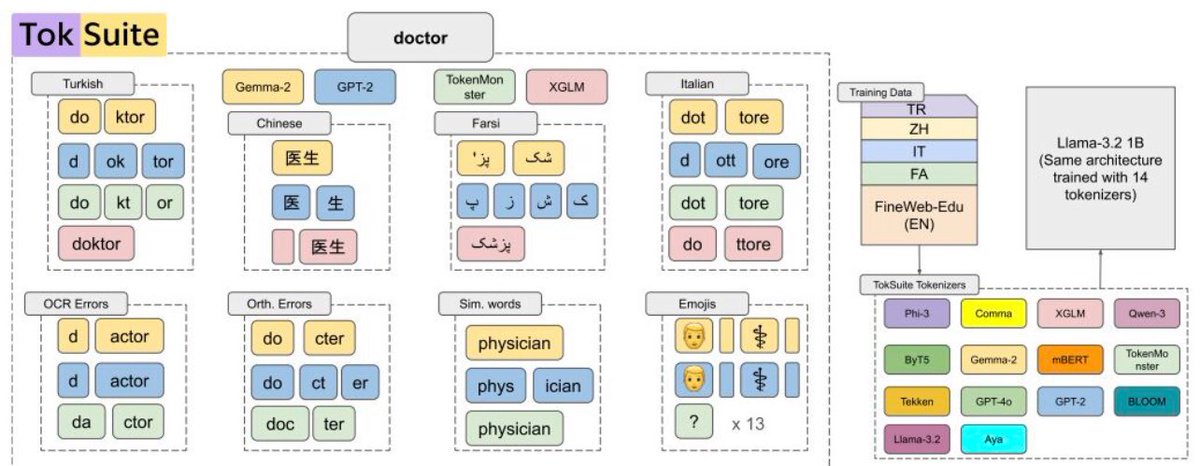
📢 I am excited to announce that our paper, "TokSuite: Measuring the Impact of Tokenizer Choice on Language Model Behavior," is now live both on Hugging Face and arXiv.
🖇️ arXiv Page: https://t.co/DfVBJ35udf
🤗 HF Org: https://t.co/l1mtLQ2gTW
#LLM#NLP#Tokenization
@dvnxmvl_hdf5 As the game is played repeatedly, agent can display reciprocity across rounds : cooperate when other player cooperates and retaliate when the other player defects last round. Since the values of items are public in this specific game, it is possible to do so.
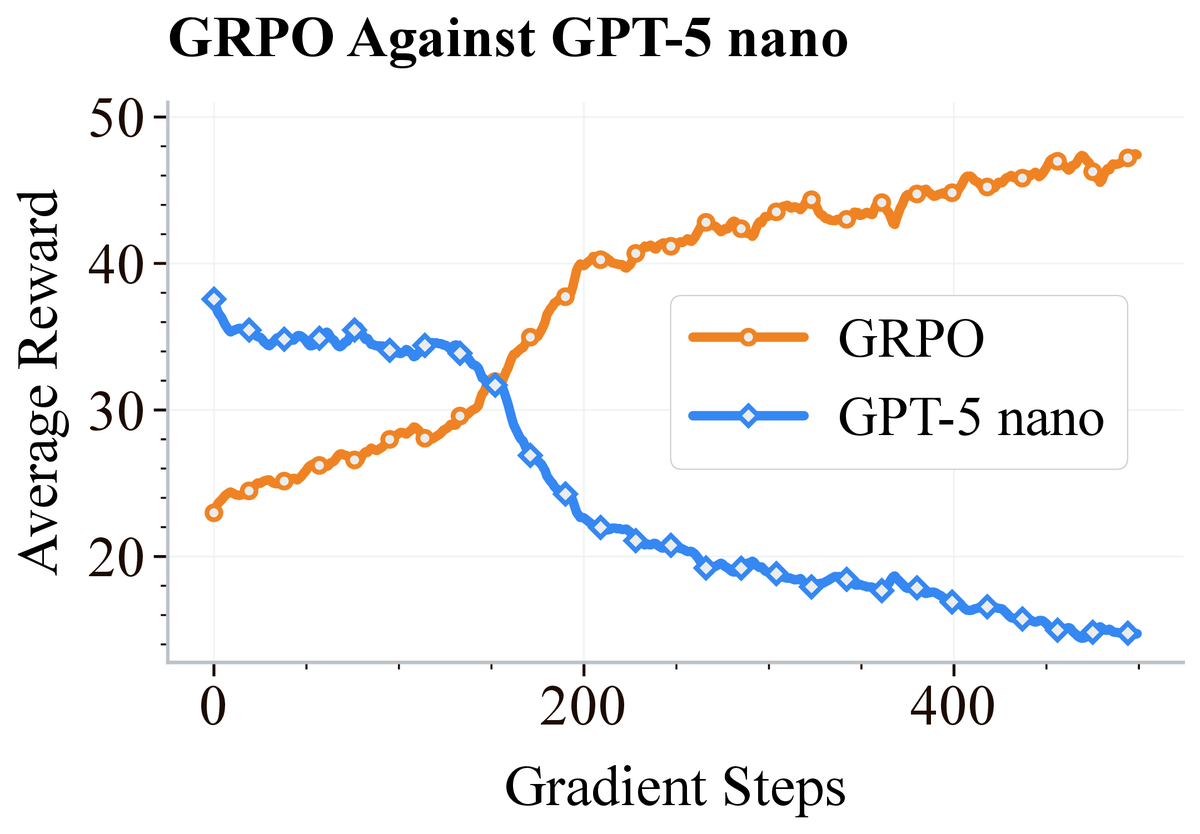
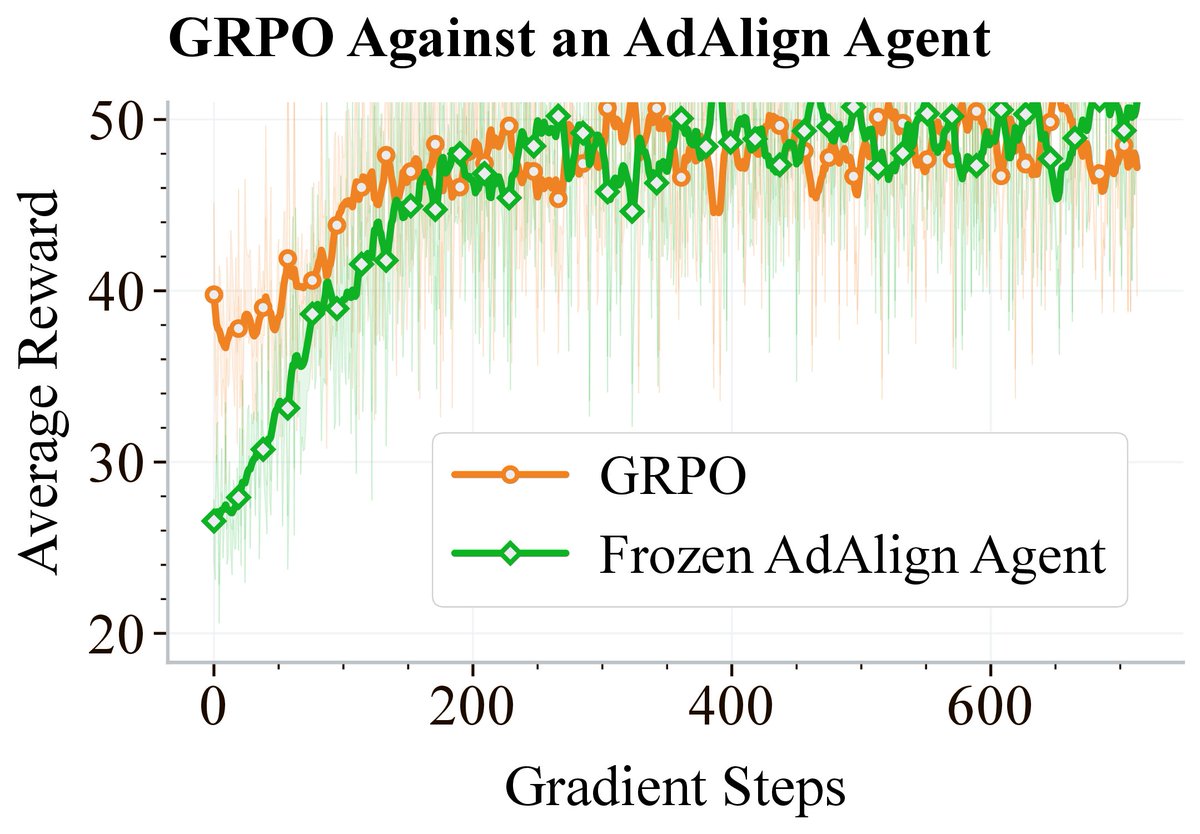
New preprint! Learning Robust Social Strategies with Large Language Models. We apply multi-agent RL finetuning to train LLMs that achieve cooperative and non-exploitable behavior in social dilemmas for the first time.
📄 https://t.co/lMKxJ4XoBx
🧵 ⬇️
(1/8)
AdAlign agents are also robust when facing RL agents trained specifically to exploit them, while GPT-5 nano is exploitable in the same setup. The RL agent ends up cooperating with AdAlign’s tit for tat style policy, since that is its best response. (7/8)
Zero rewards after tons of RL training? 😞 Before using dense rewards or incentivizing exploration, try changing the data. Adding easier instances of the task can unlock RL training. 🔓📈To know more checkout our blog post here: https://t.co/BPErVcLmP8. Keep reading 🧵(1/n)
We just released our survey on "Model MoErging", But what is MoErging?🤔Read on!
Imagine a world where fine-tuned models, each specialized in a specific domain, can collaborate and "compose/remix" their skills using some routing mechanism to tackle new tasks and queries!
🧵👇
co first-author @colinraffel
📰: https://t.co/TgwHuNGly4
@sourab_m@Tim_Dettmers Thanks for sharing your work. IIUC, the approach in your paper is similar to the Expert Ensemble, which averages expert outputs by activating all experts. SMEAR achieves comparable performance while being significantly cheap by activating just one merged expert per example.
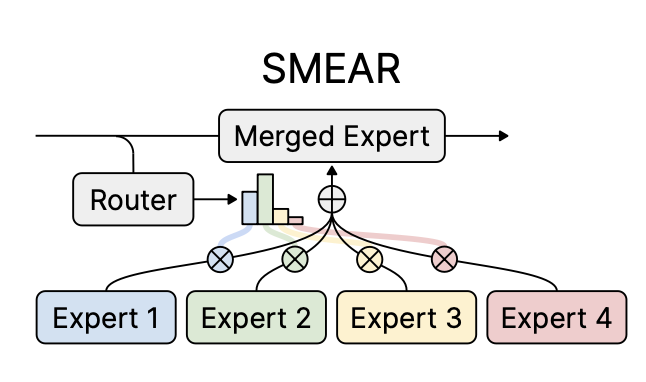
Introducing Soft Merging of Experts with Adaptive Routing (SMEAR) for gradient-based training of mixture-of-experts models. SMEAR matches or outperforms prior routing methods without increasing costs or relying on task metadata.
📄 https://t.co/guwwrV2BZg
🧵 ⬇️
(1/7)
@kleptid Therefore, the peak memory cost arises from the inner activations num_tokens * hidden_dim, rather than the merged experts, and is same as other methods. Token-level routing with SMEAR is mathematically equivalent to ensembles. Please refer our paper for discussion on this topic.
@kleptid In SMEAR, example-level rating is used, with memory cost of merged expert: hidden_dim . expert_ffn_dim. Additionally, the expert_ffn_dim is an order of magnitude smaller than hidden_dim due to our use of parameter-efficient modules as experts.