Exciting news from Microsoft Research! They’ve just released MatterGen—a generative AI model for materials design.
As someone with a chemistry background, here's why this work feels transformative 👇
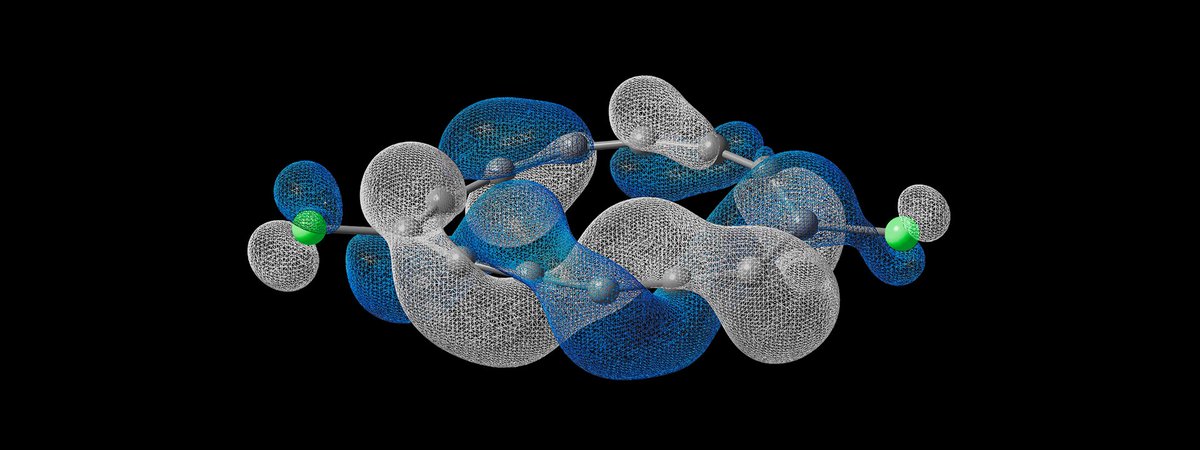
Scientists just created a molecule that has never existed before.
An international team of researchers from IBM, Oxford, and the University of Manchester (along with others) built this molecule atom by atom and observed something unusual: the electrons move through it in a corkscrew pattern, known as a half-Möbius topology.
This is the first experimental observation of this type of electronic structure in a single molecule.
To understand and validate that behavior, they used a quantum computer to simulate the molecule’s electronic structure.
This is exactly the type of problem quantum systems are naturally suited for, since they operate on the same underlying physics as the electrons themselves.
What’s interesting here is that this work shows that electronic topology can be deliberately engineered.
Still early, but this feels like a meaningful step toward more controlled design of materials, molecules, and potentially new classes of drugs.
https://t.co/B7xJ6tKWdV
The “Capybara” is out of the bag.
Anthropic just accidentally leaked part of the source code behind Claude Code through a debugging file published on npm.
No customer data was involved, but it exposed how the system is built under the hood.
A few highlights:
- A structured memory system that uses lightweight pointers and pulls in information only when needed
- Internal model codenames like Capybara and Fennec showing up in comments
- KAIROS, a background process that organizes and consolidates memory while the user is idle
- Code that suggests support for anonymous contributions to public repositories
The memory approach is especially interesting and worth reinforcing. Instead of trying to hold everything in context, it just retrieves and verifies what it needs.
Security note: If you installed Claude Code via npm during that time, it’s worth double checking your dependencies due to a reported axios issue. Anthropic is recommending their standalone installer going forward.
https://t.co/YZxVGW615h
AI just helped uncover a hidden structure in theoretical physics.
In a new preprint, GPT-5.2 Pro first conjectured a simple closed-form formula for a class of gluon scattering amplitudes that were often presumed to vanish.
The researchers then derived and formally proved the result, verifying it against established consistency checks in quantum field theory.
What stands out to me is that AI contributed to finding a compact expression inside a calculation that is normally extremely complicated.
Many breakthroughs in physics come from discovering structure that dramatically simplifies messy mathematics.
If AI systems can assist in that stage of discovery, that represents a meaningful development.
We may be moving from AI that “generates answers” to AI that helps uncover structure and contributes to mathematical conjecture.
Paper: https://t.co/n3dBBXbjEF
As I was reading the Bible the other night, when I got to Jeremiah 23:24, this thought came to me and gave me chills.
In modern physics, the best framework we have for understanding particles is Quantum Field Theory (QFT), which tells us that particles aren’t fundamental things, they’re excitations of fields that exist everywhere in space and time.
Fields are not objects in space and time.
They exist across space and time.
God isn’t just contained within this universe, and He doesn’t need to be contained in it to act within it.
His presence doesn’t require boundaries.
And stepping into space and time to bring forth Jesus makes so much sense to me.
“Do I not fill heaven and earth?”
A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code + manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.
Clinical data does not arrive as a clean bundle. It comes as labs, procedures, notes, images, time series, and fragments scattered across a patient’s timeline. Each format captures a different layer of the same patient story, and most modeling pipelines still treat them in isolation.
The Holistic AI in Medicine (HAIM) framework shows how to merge these signals without building a new architecture for every task. Each modality is embedded through its own feature extractor, then fused into a single representation shared embedding that any downstream model can use. This makes rapid testing possible because the heavy lifting happens at the feature extraction stage, not in the final predictive model.
Across more than fourteen thousand experiments, the researchers showed several patterns that feel intuitive to clinicians but have rarely been quantified. Vision data dominates pathology prediction. Time series matter most for operational tasks such as mortality or length of stay. Some modalities contribute strongly only when paired with others. A few introduce enough noise to reduce performance. Shapley values, derived from a cooperative game theory method for measuring feature contribution, reveal these interactions and show where redundancy stabilizes the system.
Multimodality helps because different tasks draw on different aspects of clinical reality. Some benefits come from genuine complementarity and others from redundancy that stabilizes the model when one source becomes sparse. The value lies in having a systematic way to test these combinations rather than assuming that more data always improves the result.
Frameworks like HAIM will matter as healthcare systems begin asking not only whether a model performs well, but whether it can be adapted to new formats, new sensors, and new clinical workflows without rebuilding everything from scratch.
Paper: https://t.co/MfCoXNYABF
Code: https://t.co/6d7fDAmwXw
Large Reasoning Models like DeepSeek-R1 and OpenAI-o3 use chain-of-thought (CoT) reasoning to “think” first before they answer.
But researchers at Meta and IBM have shown how fragile this thinking process can be: if a model is seeded with a shaky chain of thought, it often follows that path into a bad answer.
The solution: train models to override flawed starts with counter-aligned prefills. Counter-aligned prefills are deliberately wrong reasoning seeds used during training so that the model learns how to think its way back to safe, aligned, and accurate reasoning. (The training reward is based on the final output, not the flawed prefix, which incentivizes the model to recover rather than imitate the bad reasoning.)
This method converts brittleness into training signal: instead of avoiding bad reasoning, the model learns to confront and fix it. As a result, the model becomes more robust under adversarial or misleading prompts and more reflective in its reasoning.
This results in higher safety on harmful and jailbreak prompts, less overrefusal, and math held steady, with similar token budgets at inference. Robust even under full CoT hijacking, with more frequent self-reflection.
https://t.co/Sz2GGaF8Pf
From rockets to AI.
Nine years after the original NVIDIA DGX-1 handoff, Jensen Huang delivered a brand-new DGX Spark to @ElonMusk at Starbase. 🚀✨
The DGX Spark is a petaflop powerhouse built for creators, researchers, and developers — a desktop-sized supercomputer with five times the performance of the first DGX-1.
Filmed at @SpaceX’s rocket factory in Texas, this moment captures a conversation between the two visionariesI.
➡️ https://t.co/PILeU9N1y8
📹 https://t.co/bAZoMA7wZr
#SparkSomethingBig
It turns out that most multimodal AI models see too much.
They process hundreds of image patches (“visual tokens”), even when most of them are redundant.
A new framework called EPIC (Efficient MLLMs via ProgressIve Consistency Distillation) takes a different approach: it teaches models to see less but think more efficiently.
Instead of compressing all at once, EPIC gradually increases how much information the model must discard, both across tokens and layers.
The model learns to adapt smoothly rather than collapse under sudden information loss.
By applying the EPIC framework, models use one-tenth the visual tokens but retain nearly the same accuracy, without changing architecture or adding new modules.
The exciting angle here is: training systems that can learn efficiency itself.
The fastest way to grow in one field is to steal constraints from another.
My guitar practice got better when I applied lab-notebook rules: date, hypothesis, result.
Most AI models are built for prediction, not explanation. This paper argues that interpretability isn't just about glass-box vs. black-box models—it’s about how humans interact with AI. A model isn’t truly interpretable unless it reduces cognitive effort and aligns with human reasoning. A must-read on rethinking XAI. 👇
https://t.co/JwaVjFih19
Evo 2 marks a major leap in biological foundation models, trained on 9.3T DNA base pairs across all domains of life. With a 1M-token context window, it predicts mutational effects, models genome-wide variation, and enables controlled sequence generation—all without task-specific fine-tuning. Open weights, open data, and mechanistic interpretability make it a critical step toward AI-driven genomic design.
https://t.co/xgklqNUjoB
Can AI really do your research for you? 🤖
OpenAI just launched ChatGPT Deep Research, a tool that browses the web, verifies sources, and compiles detailed reports. But is it actually useful? Let's break it down.
Would you trust AI for serious research?