This night 102 years ago, Hubble discovered that there're stars outside our galaxy by observing a Cepheid variable star 1 million light years away
Until barely a century ago, no human ever knew whether there was more than one galaxy in the Universe. Think about that!
🇧🇷Contribuição brasileira no software LSDB!
O trabalho de Luigi Silva, iniciado no Hackathon do LINCC Frameworks, durante o Rubin Community Workshop, já foi incorporado ao código oficial, reforçando o papel do Brasil no futuro do LSST!
Leia: https://t.co/aLqceFKV6m
We shall measure stellar brightness logarithmically, and it will be called the "magnitude."
- Sir, will that logarithm be base 10, or based on Napier's constant?
Neither. It shall be of the base of the fifth root of one hundred.
I had a great time developing this with @FloorAstro, we're really hoping it can be useful for the community! Very fun seeing what a random conversation at @FlatironCCA can turn into 😁
IPAC has three vacancies within the @NExScI_IPAC Science Affairs team. NExScI at IPAC provides community support, science operations, analysis tools, & archive services that support the discovery and characterization of exoplanets. https://t.co/808poadGNF
So happy to present, with @Andy_Tzanidakis, demo of our LSDB and TAPE software at Rare Gems in Big Data conference. Even if you are not attending, have a look how to crossmatch and do analytics on large amount of astronomy data: https://t.co/cbPUnsfAtT #raregems2024
We are thrilled to announce the AstroAI Workshop, an event to learn about the role of Artificial Intelligence (AI) and Machine Learning (ML) in Astrophysics.
Join us: https://t.co/k7OSRx0sVh
@epiqueras1 Yes, sort by lightcurve length so that each core gets a small range of lengths, decreasing compilation times. Not sure what you mean by flattening the batch dimension. We also tried padding the lightcurves and saving compilations (GPU); both kinda worked but were quite fragile.
@epiqueras1 Jup, we tried that. It was difficult to sort datasets (much larger than single machine RAM, 10TB or so per single survey, 100TB+ expected) per lightcurve length, without doing a major reshuffling and saving the result - essentially doubling the storage needs
jax.jit will soon be able to tell you why a function is recompiling/retracing 🎉
This is a nice quality-of-life update when debugging JAX programs. Props to @SingularMattrix and @yashk2810 for the awesome log messages.
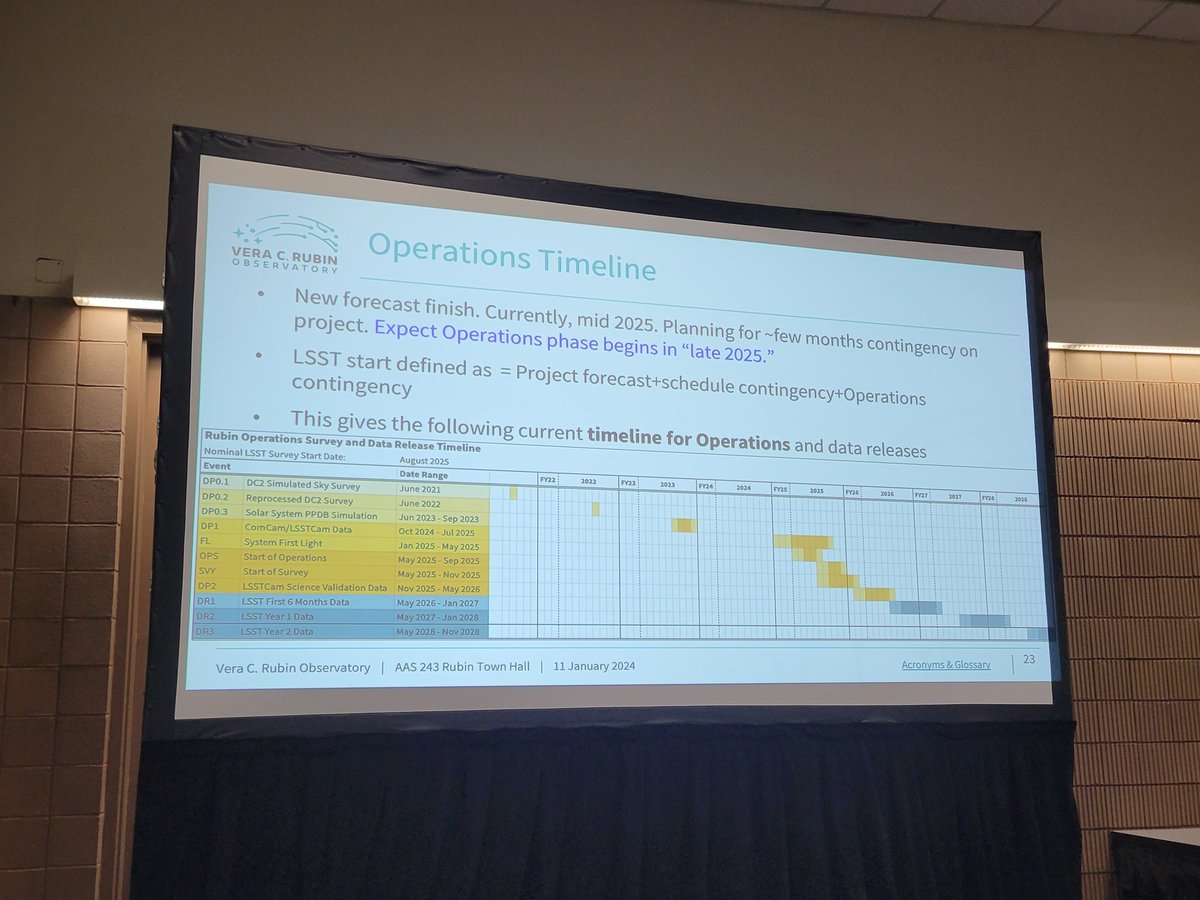
Andrew Connolly describing what we are doing as part of LINCC-Frameworks to enable early science of @VRubinObs, with my personal favorites being TAPE and LSDB, enabling large-scale cross-matching and time analysis. Happy to work with anyone except University of Michigan. #AAS243