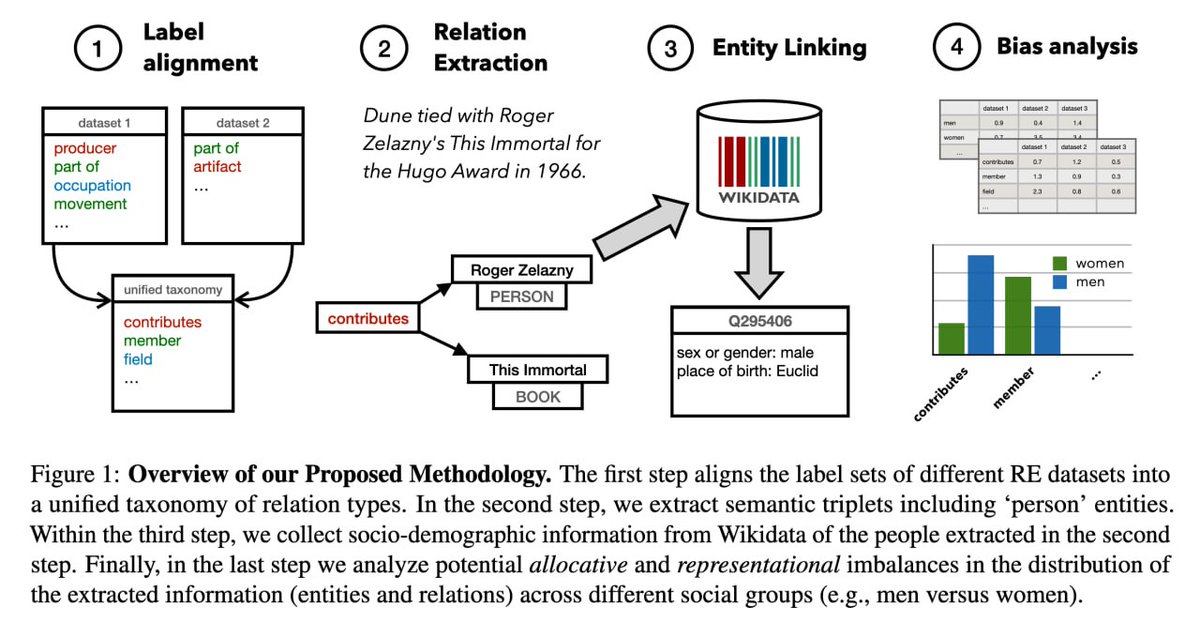
The Workshop on Natural User-generated Text (WNUT) will be at EMNLP this year (https://t.co/bjYSkvu9aP), with a shared task on lexical normalization with a focus on Asian languages (https://t.co/99GtWsE7aE)
📄The AI Gap: How Socioeconomic Status Affects Language Technology Interactions
👥 @EliBassignana * @CurriedAmanda * Dirk Hovy
🔗 https://t.co/YEGDCGrbtw
🎯We call for inclusive NLP technologies to accommodate different SES and mitigate the digital divide.
📣 Next week we will be in Vienna for @aclmeeting to present a couple of works from our lab!
Find more about each of them below 🧵👇
#NLP#NLProc#ACL2025NLP
📄 DECAF: A Dynamically Extensible Corpus Analysis Framework
👥 @mxmeij@robvanderg@annargrs
🔗 https://t.co/T5qZpy2WFy
🎯 DECAF supports generalization research with clear train/test separation at scale.
Recently, @robvanderg and @mjjzha (AAU) participated in the TalentCLEF shared task on job title and skill matching. They show that prompting performs well for job titles, but encoder models still prevail for skill matching!
📄 https://t.co/tvOcXLb0r8
#NLProc#NLP
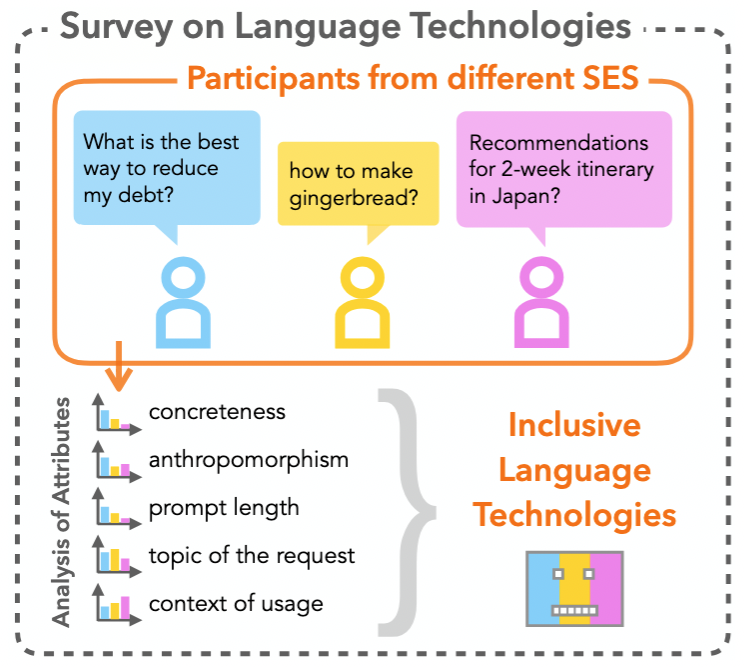
📢 New #ACL2025 preprint by our postdoc @EliBassignana about the impact of socioeconomic status (SES) on the adoption and usage of language technologies!
A first step for better understanding the AI Gap across SES and develop more inclusive language technologies ⚖️🤖
#NLProc
The first paper of my postdoc is accepted at #ACL2025 Main 🎉
"The AI Gap: How Socioeconomic Status Affects Language Technology Interactions"
I'm very happy for my new collab with @MilaNLProc and super grateful to @VILLUMFONDEN for making it possible!
#NLProc#ACL2025NLP
📄 Efficient Elicitation of Fictitious Nursing Notes from Volunteer Healthcare Professionals
👥 Jesper, @ch_hardmeier
🎯 We introduce a data collection method and Danish dataset of fictitious nursing notes by prompting volunteers with situations
🗓 March 3rd, 14.10 (Poster)
📄 DAKULTUR: Evaluating the Cultural Awareness of Language Models for Danish with Native Speakers
👥 @mxmeij@mjjzha@EliBassignana Peter Trolle @robvanderg
🎯 A user study for analyzing the cultural awareness of LLMs in Danish
🗓 March 2nd, 10:30 (NB-REAL)
Congratulations to Dr. @mizmarija for defending her thesis "Phonetic Vowel Representation for Cross-Lingual Automatic Speech Recognition"! Well deserved 🎓🎉
📢 #NLProc I'm hiring! 2x PhD students (apply by Nov 22) & postdoc (Nov 15). These positions are part of a large project on the problem of attribution for LLM outputs to the original data sources, on which LLMs were trained.
Job links on my website (in the bio)
/1
Another celebration day with the PhD defence of @dnnslmr "On Uncertainty In Natural Language Processing"
Very well-deserved! Congratulations and good luck with your next steps 🎉🎈
@ITUkbh#NLProc