🤖O Ίων Ανδρουτσόπουλος, Καθηγητής Τεχνητής Νοημοσύνης (ΤΝ) στο Τμήμα Πληροφορικής του ΟΠΑ μιλά για την Τεχνητή Νοημοσύνη σε μια συζήτηση με τον Γιώργο Ψάλτη στο ΣΚΑΪ.
🎧Ακούστε την συζήτηση: https://t.co/zKWMIDNgqQ
#aueb#ai#artificialintelligence#talk
Presenting two papers at #EACL2024. Come say hello!
"Polarized Opinion Detection Improves the Detection of Toxic Language" https://t.co/chcSwnKsPs
"Should I try multiple optimizers [...] ? Should I tune their hyperparameters?" https://t.co/T1U7e8UYDh
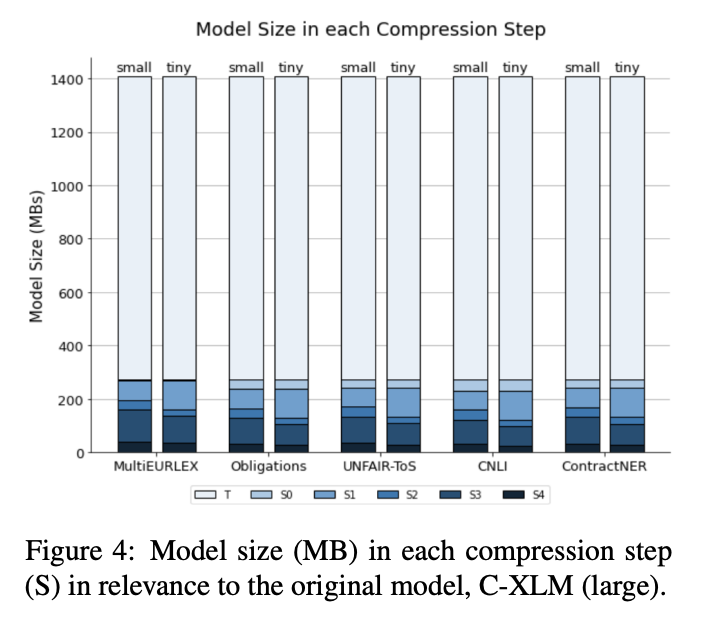
Our #legaltech paper "Legal-Tech Open Diaries: Lesson learned on how to develop and deploy light-weight models in the era of humongous Language Models" w/ Stelios Maroudas, Sotiris Legkas, and @NeuRulller has been accepted @NllpWorkshop. Preprint: https://t.co/dvqWP7Rnux🧵👇 1/6
Just recently, we uploaded all our datasets in
@huggingface to facilitate research in legal #NLProc.
From now on, you just hit:
from datasets import load_dataset
dataset = load_dataset(<URL>)
and datasets lib will do its magic 🧙♀️🥳
Read the list: 👇
Our paper "Paragraph-level Rationale Extraction through Regularization: A case study on European Court of Human Rights Cases" with @ManosFergas, @DTsarapatsanis, @nikaletras, @ionandrou and @NeuRulller will appear at #NAACL2021. Pre-print: https://t.co/XepOrrzQ34. 👇Summary: 1/7
New pre-print "Neural Contract Element Extraction Revisited: Letters from Sesame Street" with @ManosFergas, @NeuRulller, and @ionandrou is now available at https://t.co/PsnR0Lrswt. A summary / thread 👇 1/4
Our paper "Regulatory Compliance through Doc2Doc Information Retrieval: A case study in EU/UK legislation where text similarity has limitations" with @ManosFergas, @NeuRulller et al., will appear at #EACL2021. 📑 pre-print: https://t.co/FhxkM124Xr. #legaltech Brief summary: 1/8
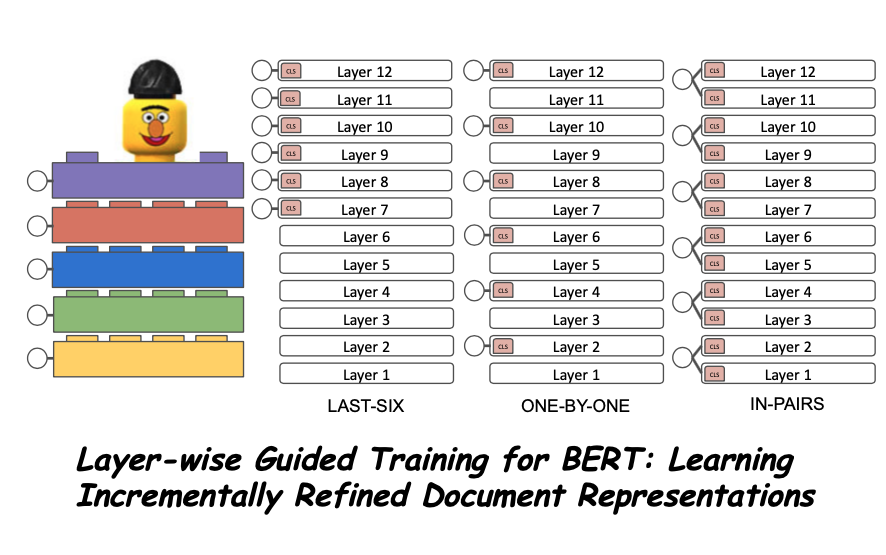
Our paper "Layer-wise Guided Training for BERT: Learning Incrementally Refined Document Representations" with Nikos Manginas and @NeuRulller, has been accepted by the Workshop on Structured Prediction for NLP (#SPNLP). Arxiv pre-print: https://t.co/hrbp1mewfA. Brief summary: 1/6
Our paper "LEGAL-BERT: The Muppets straight out of Law School" with @ManosFergas, @NeuRulller, @nikaletras and @ionandrou, has been accepted in Findings of #EMNLP2020. Arxiv pre-print available at: https://t.co/hCRAsNCw4V. Brief summary: 1/5
Our paper "An Empirical Study on Large-Scale Multi-Label Text Classification Including Few and Zero-Shot Labels" with @ManosFergas, @NeuRulller, @nikaletras and @ionandrou , has been accepted in #EMNLP2020. Arxiv pre-print available: https://t.co/tum60IP6XY. Brief summary: 1/6
Our paper "GreekBERT: The Greeks visiting Sesame street" has been accepted by #SETN2020. A pre-print is available at arxiv (https://t.co/4hrOI9afgD) and a video presentation at YouTube (https://t.co/lxtr1NJoek). 1/4
Κύριε Υπουργέ, πρόβλεψη για μετακίνηση σε δημόσιες υπηρεσίες δεν προβλέπεται; Όσοι πρέπει να μεταβούμε στον ΕΦΚΑ για παραλαβή ασφαλιστικής ενημερότητας, η οποία δεν εκδίδεται ηλεκτρονικά, τι θα κάνουμε;
@MinDigitalGr@Pierrakakis
You can now use #GreekBERT 🇬🇷 via @huggingface 🤗transformers as a pre-trained language model (i.e., language generation, quality assessment for text, etc.). Check the demo: https://t.co/fn9ulF2O28.
Initial benchmarking will be released shortly!
With @AUEBNLPGroup, we released a Greek edition of BERT that you can literally use with 2 lines of code via @huggingface transformers for both @PyTorch / @TensorFlow. Thanks TensorFlow Research Cloud (TFRC) for supporting our research. 🤗🇬🇷See details at https://t.co/VHE0chqsLv
SUM-QE: a BERT-based Summary Quality Estimation Model, to be presented at #emnlp2019, by @xenouleas@NeuRulller@MApidianaki@ionandrou
Paper: https://t.co/gHcSMmSx7z
Poster: https://t.co/WDGdJi3D8j
Code: https://t.co/WtOj96Wdxt








![AUEBNLPGroup's tweet photo. Presenting two papers at #EACL2024. Come say hello!
"Polarized Opinion Detection Improves the Detection of Toxic Language" https://t.co/chcSwnKsPs
"Should I try multiple optimizers [...] ? Should I tune their hyperparameters?" https://t.co/T1U7e8UYDh https://t.co/A89d7ZeSee](https://pbs.twimg.com/media/GI8GEEQX0AAdO4P.jpg)