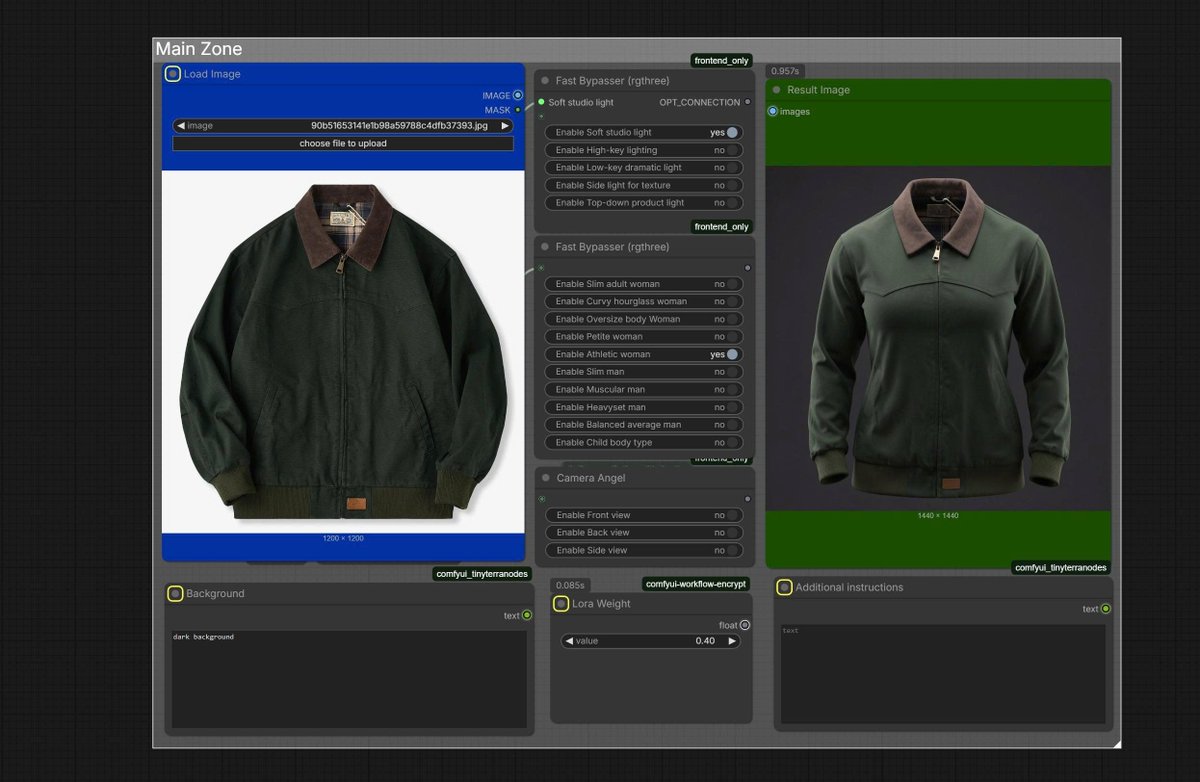
Stumbled upon an absolutely insane upscale tool by @philz1337x ! 🤯 I don't know his exact method, but it inspired me to build my own.
Right now, I am actively developing an advanced @ComfyUI workflow, creating several brand-new custom nodes, and training a specific LoRA for this upscaling task.
I just tested upscaling a 1MP image to a massive 310 Megapixels, and the early results are incredibly promising! 🔥
Once development is complete, I will immediately share the entire toolkit publicly here on X and drop a deep-dive video on my YouTube channel.
If you are interested in this project, please drop a follow to my X Account and subscribe to my YouTube: https://t.co/aDX2gdoplJ support is my biggest motivation to keep researching and building! 👇
#ComfyUI #StableDiffusion #AICommunity #GenerativeAI
@philz1337x@ComfyUI Yes, I don't think I can replicate your method exactly, but with a different approach, I'm trying to achieve a quality close to yours. I'll be publishing it soon on my X account and YouTube channel.
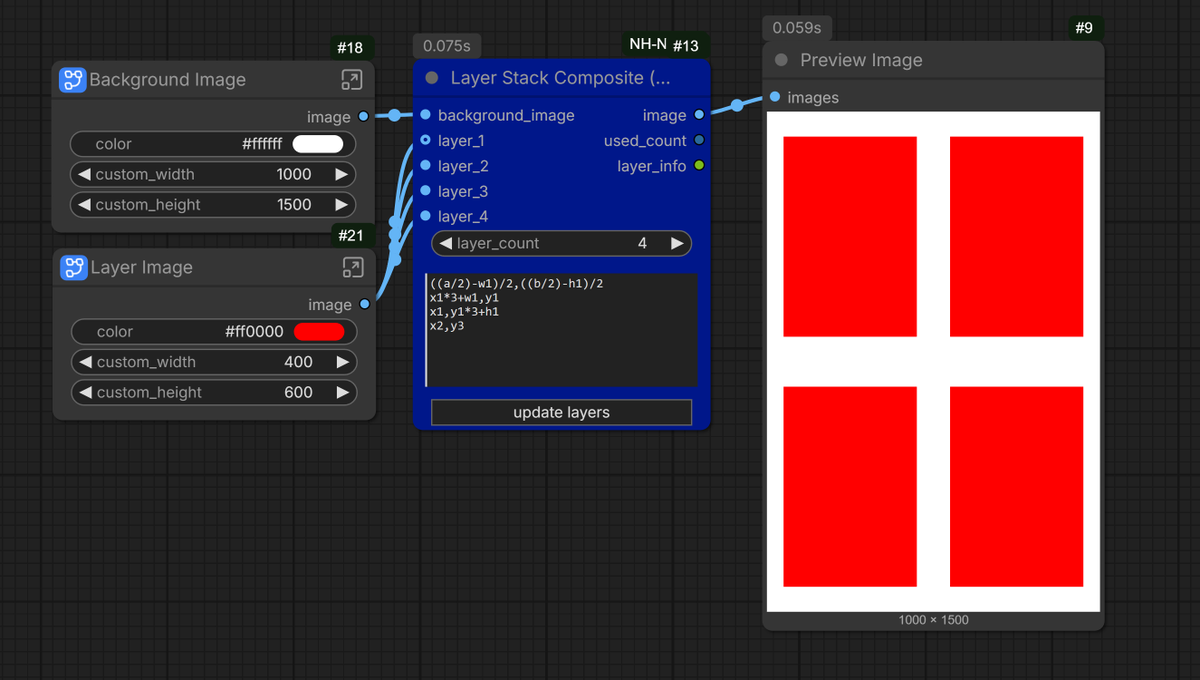
Part of the NH-Nodes suite: A node for compositing layers onto a background. It supports an unlimited number of layers and allows the use of mathematical expressions to automate any layout you desire.
Where:
Background width = a - Background height = b
Layer 1 width = w1 - Layer 1 height = w2
Each row represents the corresponding x;y
coordinates for each layer. Row 1 is assigned x1,y1 - Row 2 is x2,y2, and so on.
In the process of building custom workflows, you will occasionally encounter needs like this; instead of having to chain multiple "paste" nodes together, you will only need to use a single node.
I am developing a powerful custom nodes for automation in @ComfyUI , orchestration, and adaptation to various scenarios. This node set is being developed based on projects I have worked on where I encountered automation-related challenges. These custom nodes are currently under development and are being continuously refined. Please use and evaluate them so I can improve them to the best of my ability.
github link: https://t.co/p82Om98J2K
Este tipo acaba de revelar cómo construir webs cinematográficas de 10.000$ en un tutorial de 16 minutos.
La combinación es Gemini 3.1 + Seedance 2.0 y el resultado parece producción de agencia de lujo.
Gratis. 16 minutos.
I haven't used Node 2.0 yet, but with the current @ComfyUI and #custom_nodes, we can simplify and make the workflow extremely streamlined and highly automated.
I have created a set of nodes in @ComfyUI for automatically switching between two process flows without using bypasses, ensuring only a single process executes instead of both simultaneously. Previously, we had to use bypass or mute to prevent them, but this led to an excessive number of connections in the #workflow, or too many groups, and made #API implementation more difficult.
I have just completed a highly efficient character swap workflow with @ComfyUI ; through numerous tests, its stability and accuracy have reached near-maximum levels. Along with that, I have also trained a specialized LoRA for this task with #AITookit of @ostrisai .
The workflow for both Klein 4B and 9B are responding very well.
#ComfyUI #CharacterSwap #Lora #Tranning
we are waiting for a new image edit model!
FireRed-Image. A versatile high-fidelity editor;
- preserves text styles;
- restores old photos;
- multi-image tasks.
It seems to be based on Qwen-Image..
https://t.co/ALFhUIDGrI
Introducing Driftin!
I trained DDPM and a new method called "Drifting" on the same 38M-param UNet on CIFAR-10 (classical 8xH100 setup).
> DDPM: 50 denoising steps, 418ms per image
> Drifting: 1 step, 3.26ms per image
> 306 FPS on a single 3090. 57x faster. Same network.
> Drifting learns to map noise directly to images in one forward pass using drift fields computed from DINOv2 features. No iterative denoising. No distillation. Just one step.
> The quality gap is real at this scale -- but DINOv2 features closed a huge chunk of it, and we have only trained with global batch 1024. Drift signal quality scales directly with batch size. This is the opposite of diffusion.
> If the quality gap closes with scale, real-time AI video generation is not a dream -- it is an engineering problem. 77 FPS at 512x512 via latent space on a consumer GPU.
Compute sponsored by @VoltagePark
Code + devlog below.