Introducing #AIStudio via #AdobeStock — edit stock assets before licensing https://t.co/1JmhRsRP9M
AI Studio features #AudioMatch -- create custom soundtracks for video before licensing.
Proud of the #team 🥂👇 + Adobe Stock's new economic models to blend #GenAI w/licensing.
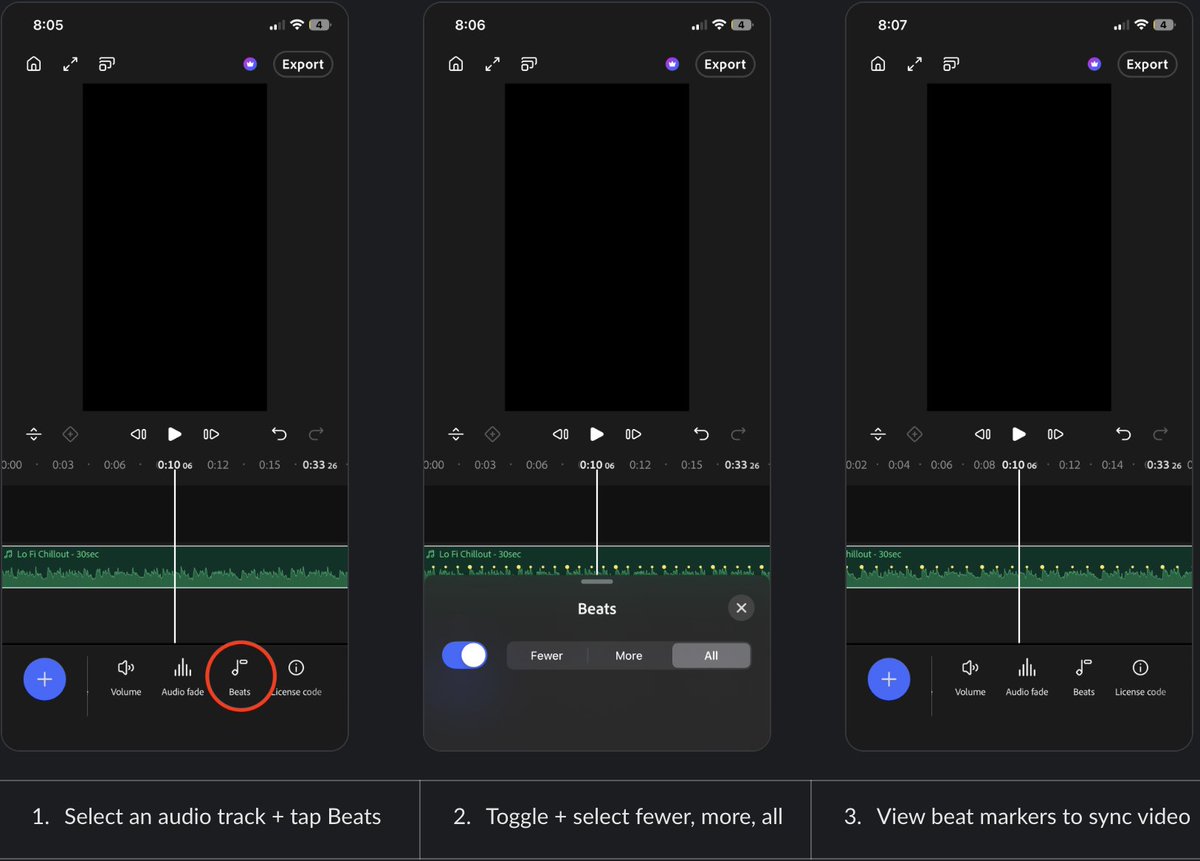
Excited for "Beats" is released in @Adobe#PremiereMobile on iOS!
We detect musically meaningful markers within your music to sync, snap, and cut to your video. Three visualization options corresponding to less → more markers.
w/@JojoGiltsoff, Eric Brandt, @j_p_caceres ++!
🎶 V2M-Zero: SOTA time-sync'd video-to-music! 🎶
* Music sync'd to dance, scene cuts,
* Easily adapt existing TTM models,
* No paired video-music data,
* SOTA objective + human preference.
Exceptional work @yblin98 + @casebeer! w/@mtlong_88@aniruddha26398@gberta227, me
Audio VAEs + VQ-VAEs designed for #GenAI!
* Ultra-fast encoding for on-the-fly training pipelines,
* ~2x more compression (13Hz) w/frontier quality,
* Any format (mono, stereo LR, MS, mel, raw),
* Cont. or discrete latents.
👏 @CasebeerJonah! w/@__gzhu__@zhepeiw03, me
GenAE: An audio autoencoder engineered for generative modeling.
To appear at ICASSP 2026.
w/ @__gzhu__@zhepeiw03@NicholasJBryan
arXiv: https://t.co/akXYENgCZG
Video: https://t.co/udshifZ7tY
This is big. SOTA audio reasoning. SOTA video reasoning. SOTA audio captioning. SOTA sound event detection. Better than Gemini. Better than Qwen.
TAC: Timestamped Audio Captioning
📑 paper: https://t.co/3IVuI6qn4S
🌐 website with more demos: https://t.co/FhoFqqTYQo
@LudovicCreator I've been playing with Generate Soundtrack a lot today. It is pretty great, and really fast.
I've been collecting a bunch of alternate music options from my videos.
Why no one is talking about the new Meta AI - Image and Video generation which is partnered with Midjourney and Black Forest Labs??
The generations are fascinating.
Image and Video generated with @Meta@AIatMeta
Music - @Adobe Generate Soundtrack
@alexandr_wang#MetaAI
Thrilled to announce “MIDI-LLM: Adapting LLMs for Text-to-MIDI Music Generation” w/ @huangcza and Yoon Kim!
🎸 Live Demo https://t.co/6N6AqyrZuW
💻 https://t.co/Z1v82uool5
🤗 https://t.co/k9deMY82Vk
From a text prompt, it generates MIDIs you can edit directly in a DAW 🧵
Tired to go back to the original papers again and again? Our monograph: a systematic and fundamental recipe you can rely on!
📘 We’re excited to release 《The Principles of Diffusion Models》— with @DrYangSong, @gimdong58085414, @mittu1204, and @StefanoErmon.
It traces the core ideas that shaped diffusion modeling and explains how today’s models work, why they work, and where they’re heading.
🧵You’ll find the link and a few highlights in the thread.
We’d love to hear your thoughts and join some discussions!
⚡ Stay tuned for our markdown version, where you can drop your comments!
Adobe's #GenerateSoundtrack is LIVE today! 🎉
Studio-quality music for storytellers🎵
* Trained on #Licensed data,
* Commercially safe, royalty-free, and cleared for any use, &
* Exported with #ContentCredentials for transparency and attribution.
Get started: https://t.co/ICe7jjt2HW
Powered by the #FireflyAudioModel, and built by an incredible R&D team: @j_p_caceres@CasebeerJonah@__gzhu__@zhepeiw03@ailiefraser@NicholasJBryan
Excited for the Team. Much more to come!
#Adobe #AdobeMAX #GenerateSoundtrack #FireflyAudioModel
Introducing "DRAGON: Distributional Rewards Optimize Diffusion Generative Models"!
📖: https://t.co/biSceK5vgQ
🎹: https://t.co/6taiaC8SUZ
A new framework for fine-tuning gen models towards a target distribution.
By Yatong Bai w/@CasebeerJonah@somayeh_sojoudi@NicholasJBryan
Introducing "DRAGON: Distributional Rewards Optimize Diffusion Generative Models"!
📖: https://t.co/biSceK5vgQ
🎹: https://t.co/6taiaC8SUZ
A new framework for fine-tuning gen models towards a target distribution.
By Yatong Bai w/@CasebeerJonah@somayeh_sojoudi@NicholasJBryan