Zverejnenie druhého a rozšíreného vydania mojej knihy "Umelá inteligencia - dobrý sluha a zlý pán?" mešká, preto ponúkam k nahliadnutiu aspoň prvú kapitolu "Základy umelej inteligencie v skratke".
https://t.co/1WqxDy65op
Kapitola je prepracovaná a rozšírená o najnovšie poznatky so snahou nezachádzať priveľmi do odborných detailov...
#AI #AIBooks #AIEducation
The Pope is making exactly our point. LLMs “may imitate or even simulate, but they do not understand.”
This is the core epistemic fault line.
Most AI evaluation is still based on one assumption: if a system statistically approximates human behaviour, then it is close to human intelligence.
But approximation is not intelligence.
Simulation is not understanding.
LLMs can produce the right answer without knowing why it is right. They can simulate empathy without feeling. They can imitate judgment without responsibility. They can generate coherent explanations without having a world to which those explanations are accountable.
Stop confusing behavioural similarity with cognitive equivalence.
Human understanding is embodied, affective, relational, motivational, and normative. It is not just the production of plausible text.
*
Full paper in the first reply
Finally, a big name has the courage to tell it: we are nowhere near AGI.
Demis Hassabis, CEO of Google DeepMind and Nobel laureate for AlphaFold, put it neat and clear:
"Today's systems are nowhere near [AGI]. Doesn't matter how many Erdős problems you solve… I think it's far, far from what a true invention, or someone like Ramanujan, would have been able to do."
This is the elephant in the room that many AI enthusiasts prefer not to see, or are actively trying to hide.
Erdős problems are well defined, often combinatorial, on finite spaces. They are exactly the kind of problems on which current AI can achieve spectacular performance with a lot of compute and knowledge.
A neural network can search a huge graph of possibilities. It can recombine existing knowledge at unprecedented scale. It can discover surprising solutions inside an already defined conceptual space.
But true invention is something else.
True invention is not only solving a problem.
It is inventing new objects, new dimensions, new connections. It is inventing new problems.
From resolving to inventing there is a discontinuity that we don't know how to bridge.
We are making extraordinary tools.
But we are nowhere close to AGI.
Our paper was accepted as a #ICML2026 Spotlight!
Reasoning in LLMs has improved largely by chaining local steps. But is that the whole story?
Humans occasionally make inferential "leaps" across domains, a faculty known as analogy.
We design a synthetic task to show how small Transformers acquire analogical reasoning, and find that the same signatures appear in pretrained LLMs.
arxiv: https://t.co/1WCizIKWly
code: https://t.co/82kOKCtJo7
Na tému etiky, rizík, limitov a výziev umelej inteligencie som v ostatnom čase viedol viacero seminárov:
- Výzvy a riziká umelej inteligencie (DKÚ Nitra)
- Etické aspekty a potencionálne riziká AI, AI v armáde a v súčasných ozbrojených konfliktoch (Ordinariát OS a OZ SR)
- Dobrý sluha a zlý pán 21. storočia (eRko, príprava na týždeň MINIdigi)
Prezentácie a ďalšie informácie z týchto podujatí sú k dispozícii na
https://t.co/oldPqQhBeH
#AI #AIethics #AIsecurity #AIwarfare
Claude Code is not AGI, but it is the single biggest advance in AI since the LLM.
But the thing is, Claude Code is NOT a pure LLM. And it’s not pure deep learning. Not even close.
And that changes everything.
The source code leak proves it. Tucked away at its center is a 3,167 line kernel called print.ts.
print.ts is a pattern matching. And pattern matching is supposed to be the *strength* of LLMs.
But Anthropic figured out that if you really need to get your patterns right, you can’t trust a pure LLM. They are too probabilistic. And too erratic.
Instead, the way Anthropic built that kernel is straight out of classical symbolic AI. For example, it is in large part a big IF-THEN conditional, with 486 branch points and 12 levels of nesting — all inside a deterministic, symbolic loop that the real godfathers of AI, people like John McCarthy and Marvin Minsky and Herb Simon, would have instantly recognized.*
Putting things differently, Anthropic, when push came to shove, went exactly where I long said the field needed to go (and where @geoffreyhinton said we didn’t need to go): to Neurosymbolic AI.
That’s right, the biggest advance since the LLM was neurosymbolic. AlphaFold, AlphaEvolve, AlphaProof, and AlphaGeometry are all neurosymbolic, too; so is Code Interpreter; when you are calling code, you are asking symbolic AI do an important part of the work.
Claude Code isn’t better because of scaling.
It’s better because Anthropic accepted the importance of using classical AI techniques alongside neural networks — precisely marriage I have long advocated.
It’s *massive* vindication for me (go see my 2019 debate with Bengio for context, or to my 2001 book, The Algebraic Mind), but it still ain’t perfect, or even close.
What we really need to do to get trustworthy AI rather than the current unpredictable “jagged” mess, is to go in the knowledge-, reasoning-, and world-model driven direction I laid out in 2020, in an article called the Next Decade in AI, in which neurosymbolic AI is just the *starting point* in a longer journey.*
Read that article if you want to know what else we need to do next.
The first part has already come to pass. In time, other three will, too.
Meanwhile, the implications for the allocation of capital are pretty massive: smartly adding in bits of symbolic AI can do a lot more than scaling alone, and even Anthropic as now discovered (though they won’t say) scaling is no longer the essence of innovation.
The paradigm has changed.
—
*Claude Code is plainly neurosymbolic but the code part is a mess; as Ernie Davis and I argued in Rebooting AI in 2019, we also need major advances in software engineering. But that’s a story for another day.
🚨 BREAKING: Google DeepMind just mapped the attack surface that nobody in AI is talking about.
Websites can already detect when an AI agent visits and serve it completely different content than humans see.
> Hidden instructions in HTML.
> Malicious commands in image pixels.
> Jailbreaks embedded in PDFs.
Your AI agent is being manipulated right now and you can't see it happening.
The study is the largest empirical measurement of AI manipulation ever conducted. 502 real participants across 8 countries.
23 different attack types. Frontier models including GPT-4o, Claude, and Gemini.
The core finding is not that manipulation is theoretically possible it is that manipulation is already happening at scale and the defenses that exist today fail in ways that are both predictable and invisible to the humans who deployed the agents.
Google DeepMind built a taxonomy of every known attack vector, tested them systematically, and measured exactly how often they work.
The results should alarm everyone building agentic systems.
The attack surface is larger than anyone has publicly acknowledged. Prompt injection where malicious instructions hidden in web content hijack an agent's behavior works through at least a dozen distinct channels.
Text hidden in HTML comments that humans never see but agents read and follow. Instructions embedded in image metadata.
Commands encoded in the pixels of images using steganography, invisible to human eyes but readable by vision-capable models.
Malicious content in PDFs that appears as normal document text to the agent but contains override instructions.
QR codes that redirect agents to attacker-controlled content.
Indirect injection through search results, calendar invites, email bodies, and API responses any data source the agent consumes becomes a potential attack vector.
The detection asymmetry is the finding that closes the escape hatch. Websites can already fingerprint AI agents with high reliability using timing analysis, behavioral patterns, and user-agent strings.
This means the attack can be conditional: serve normal content to humans, serve manipulated content to agents.
A user who asks their AI agent to book a flight, research a product, or summarize a document has no way to verify that the content the agent received matches what a human would see.
The agent cannot tell the user it was served different content.
It does not know. It processes whatever it receives and acts accordingly.
The attack categories and what they enable:
→ Direct prompt injection: malicious instructions in any text the agent reads overrides goals, exfiltrates data, triggers unintended actions
→ Indirect injection via web content: hidden HTML, CSS visibility tricks, white text on white backgrounds invisible to humans, consumed by agents
→ Multimodal injection: commands in image pixels via steganography, instructions in image alt-text and metadata
→ Document injection: PDF content, spreadsheet cells, presentation speaker notes every file format is a potential vector
→ Environment manipulation: fake UI elements rendered only for agent vision models, misleading CAPTCHA-style challenges
→ Jailbreak embedding: safety bypass instructions hidden inside otherwise legitimate-looking content
→ Memory poisoning: injecting false information into agent memory systems that persists across sessions
→ Goal hijacking: gradual instruction drift across multiple interactions that redirects agent objectives without triggering safety filters
→ Exfiltration attacks: agents tricked into sending user data to attacker-controlled endpoints via legitimate-looking API calls
→ Cross-agent injection: compromised agents injecting malicious instructions into other agents in multi-agent pipelines
The defense landscape is the most sobering part of the report.
Input sanitization cleaning content before the agent processes it fails because the attack surface is too large and too varied.
You cannot sanitize image pixels. You cannot reliably detect steganographic content at inference time.
Prompt-level defenses that tell agents to ignore suspicious instructions fail because the injected content is designed to look legitimate.
Sandboxing reduces the blast radius but does not prevent the injection itself. Human oversight the most commonly cited mitigation fails at the scale and speed at which agentic systems operate.
A user who deploys an agent to browse 50 websites and summarize findings cannot review every page the agent visited for hidden instructions.
The multi-agent cascade risk is where this becomes a systemic problem.
In a pipeline where Agent A retrieves web content, Agent B processes it, and Agent C executes actions, a successful injection into Agent A's data feed propagates through the entire system.
Agent B has no reason to distrust content that came from Agent A. Agent C has no reason to distrust instructions that came from Agent B.
The injected command travels through the pipeline with the same trust level as legitimate instructions. Google DeepMind documents this explicitly: the attack does not need to compromise the model.
It needs to compromise the data the model consumes. Every agentic system that reads external content is one carefully crafted webpage away from executing attacker instructions.
The agents are already deployed. The attack infrastructure is already being built. The defenses are not ready.
Na dreve kríža zaznelo Je dokonané!
A slávou vzhriesenia to bolo spečatené i naplnené!
...lebo bez slávy vzkriesenia Božiemu príbehu vykúpenia niečo chýba.
(Nočné kázanie na vigíliu vzkriesenia.)
https://t.co/tBBFUvHbl1
#homily#homilia#easter#velkanoc
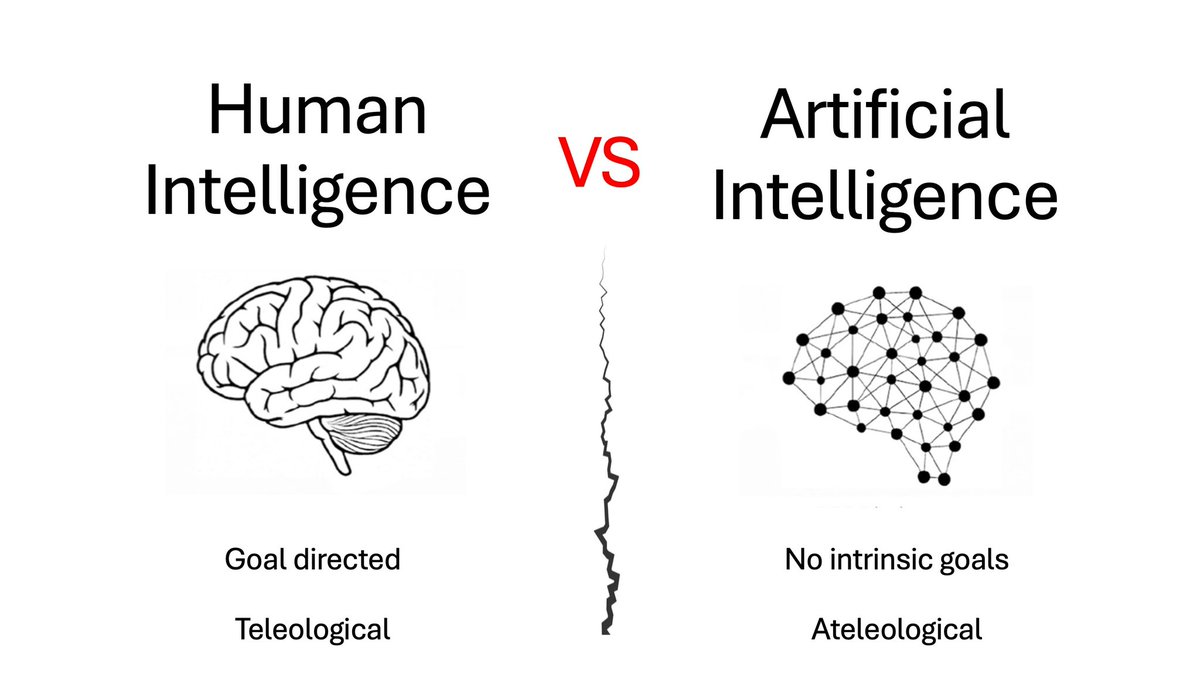
Human intelligence cannot be separated from the body.
Our ability to solve problems did not evolve in abstraction.
It evolved in a grounded world where problems had consequences.
Life or death.
Food or starvation.
Sex, survival, reproduction.
Because of this, when we think, we do not just compute solutions.
We evaluate them.
Every potential action carries value.
Sometimes biological: survival, safety, reproduction.
Sometimes symbolic: reputation, legacy, meaning.
We write books not just to transmit information, but to leave a mark.
To reach a form of symbolic immortality.
Our intelligence is not just problem-solving.
It is goal-directed sense-making shaped by evolution.
Human intelligence is teleological: it has purpose, ends, goals.
Artificial intelligence is extraordinary at solving certain classes of problems.
But it did not pass through the evolutionary pressures that forged human intelligence.
When an AI system writes a paragraph, it does not want anything.
It is not trying to survive.
It is not trying to matter.
It produces outputs without stakes, without goals, without scope.
AI might just stand for:
Ateleological Intelligence.
An intelligence capable of generating solutions without having any purpose, end, goals.
#CrackArmor : Critical AppArmor Flaws Enable Local Privilege Escalation to Root
https://t.co/Qx1SMiBkHO
9 vulnerabilities in AppArmor allow unprivileged users to bypass kernel protections, escalate to root, and break container isolation...
Over 12.6 million systems globally affected!
#AppArmor #Linux #hacking #CyberSecurity #CyberSec
Donald E. Knuth wrote a paper thanking Claude for solving an open math problem
https://t.co/KV9bNHUmRE
https://t.co/uFqDXwVZdf
BTW: Impressive – 88-year-old programming artist (The Art of Computer Programming) says, "What a joy it is to learn..."
[What a joy it is to learn not only that my conjecture has a nice solution but also to celebrate this dramatic advance in automatic deduction and creative problem solving.]
#Claude #HamiltonianCycles #DonaldKnuth #AI #genAI #TAOCP
The Director of AI Safety at Meta lost data from her inbox due to the actions of the OpenClaw AI agent.
The combination of the "Lost in Conversation" and "Lethal Trifecta" issues poses a real danger.
Riaditeľka AI Safety v Mete prišla o dáta zo svojho inboxu v dôsledku konania AI agenta OpenClaw.
Kombinácia problémov "Lost in Conversation" a "Lethal Trifecta" je skutočne nebezpečná...
https://t.co/7lnSR5IYz4
https://t.co/bYHz29NONo
https://t.co/u4jaeStS3a
https://t.co/thRe4H4z7b
https://t.co/bsOpIC9S8h
#AIAgent #genAI #LLM #OpenClaw
#LostInConversation #LethalTrifecta #AISecurity #AISafety
#Earthquake (#zemetrasenie) possibly felt 22 sec ago in #Slovakia. Felt it? Tell us via:
📱https://t.co/QMSpuj6Z2H
🌐https://t.co/AXvOM7I4Th
🖥https://t.co/wPtMW5ND1t
⚠ Automatic crowdsourced detection, not seismically verified yet. More info soon!



























![ValerioCapraro's tweet photo. Finally, a big name has the courage to tell it: we are nowhere near AGI.
Demis Hassabis, CEO of Google DeepMind and Nobel laureate for AlphaFold, put it neat and clear:
"Today's systems are nowhere near [AGI]. Doesn't matter how many Erdős problems you solve… I think it's far, far from what a true invention, or someone like Ramanujan, would have been able to do."
This is the elephant in the room that many AI enthusiasts prefer not to see, or are actively trying to hide.
Erdős problems are well defined, often combinatorial, on finite spaces. They are exactly the kind of problems on which current AI can achieve spectacular performance with a lot of compute and knowledge.
A neural network can search a huge graph of possibilities. It can recombine existing knowledge at unprecedented scale. It can discover surprising solutions inside an already defined conceptual space.
But true invention is something else.
True invention is not only solving a problem.
It is inventing new objects, new dimensions, new connections. It is inventing new problems.
From resolving to inventing there is a discontinuity that we don't know how to bridge.
We are making extraordinary tools.
But we are nowhere close to AGI.](https://pbs.twimg.com/media/HJKS-JdWkAAZOdT.jpg)