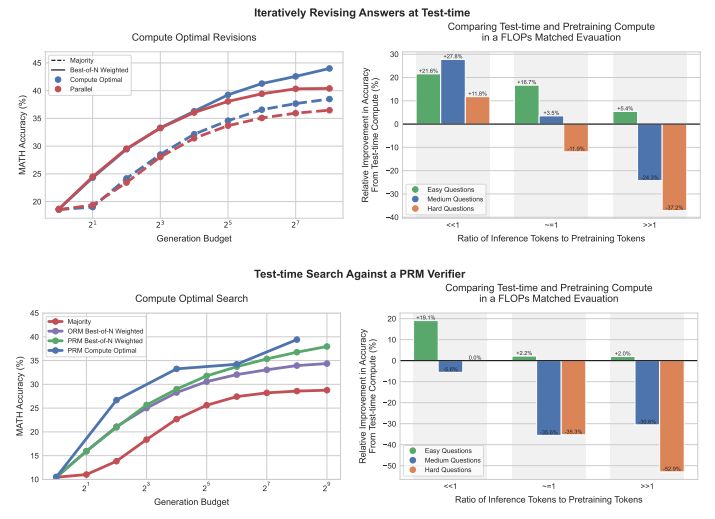
📙 Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Authors: @sea_snell, @hoonkp, @imkelvinxu, @aviral_kumar2
Featured in PTK #127 https://t.co/mhSkZeoQJ3
Paper: https://t.co/h4l8UFZ6TM
📙 The Unreasonable Effectiveness of Easy Training Data for Hard Tasks
Authors: @peterbhase, @mohitban47, Peter Clark,
@sarahwiegreffe
Paper: https://t.co/GmOVgWTzz2
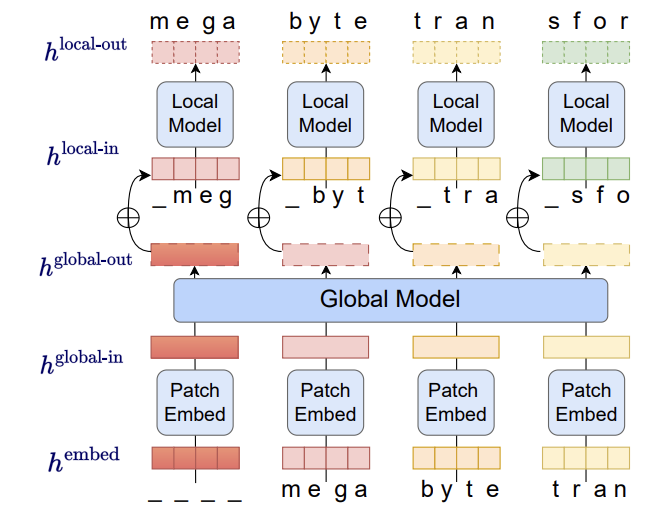
📙 MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers
Authors: Lili Yu, Dániel Simig, Colin Flaherty, Armen Aghajanyan, Luke Zettlemoyer, Mike Lewis
Featured in PTK #124 https://t.co/DpNJu1Qkrt
Paper: https://t.co/jmVvfN1XS5
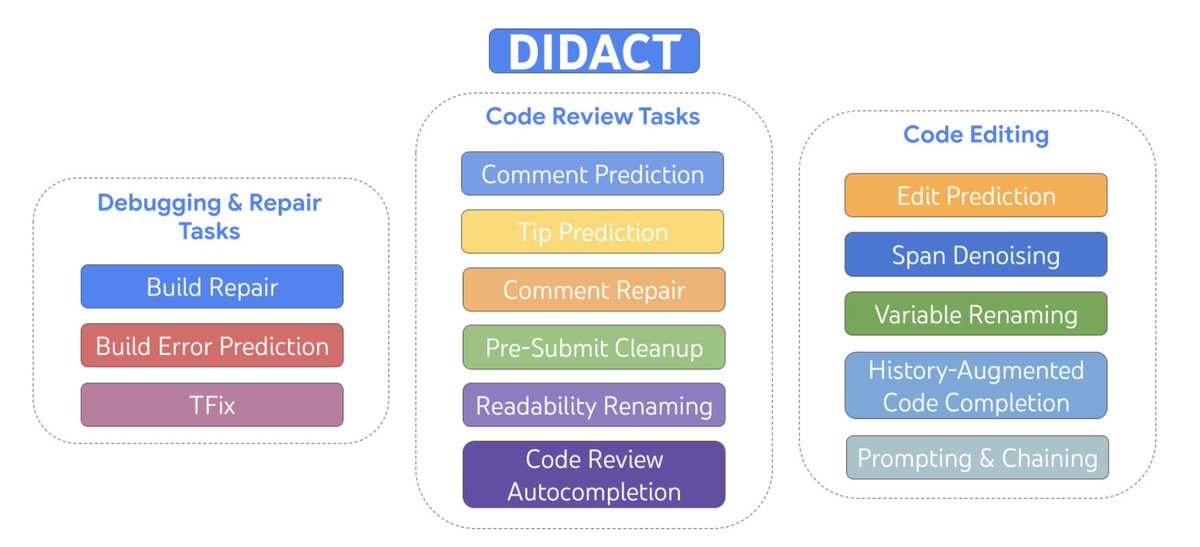
Large sequence models for software development activities by: Petros Maniatis, Daniel Tarlow
Featured in PTK #124 https://t.co/DpNJu1QSh1
Blog: https://t.co/HoIZgHsife
📙 How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
Featured in PTK #124 https://t.co/DpNJu1Qkrt
Paper: https://t.co/IH0Ahqzs8y
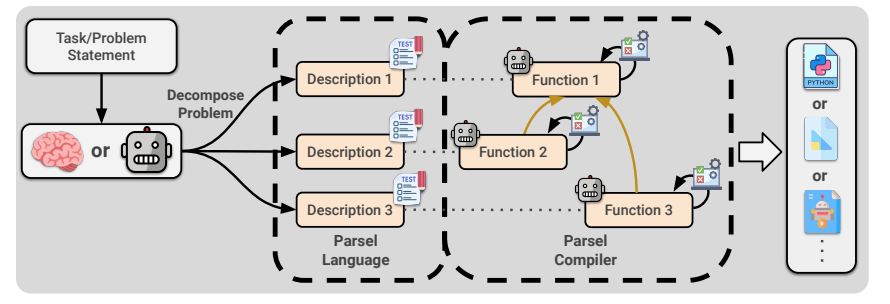
📙 Parsel : A (De-)compositional Framework for Algorithmic Reasoning with Language Models
Authors: Eric Zelikman, Qian Huang, Gabriel Poesia, Noah D. Goodman, Nick Haber
Featured in PTK #121 https://t.co/3asL8nl2xA
Paper: https://t.co/vKXszwhyDP
🖥️ 𝗗𝗦𝗣: The Demonstrate–Search–Predict Framework by: Omar Khattab, Keshav Santhanam, Xiang Lisa Li, David Hall, Percy Liang, Christopher Potts, Matei Zaharia
Featured in PTK #121 https://t.co/3asL8nl2xA
Code: https://t.co/Am0D19Cmol
Paper: https://t.co/IY0GANXuTj
1/ NeevaAI serves abstractive summaries of web pages that are generated in real-time.
We achieved this by a ~10x reduction in latency of a fine-tuned t5-large encoder-decoder model.
TY @asimshankar, @rajhans_samdani, @AshwinDevaraj3 + @spacemanidol
See our lessons learned.. 🧵