The first draft of General-Purpose AI Code of Practice is out.
The document, prepared by independent experts, covers transparency, copyright rules, and risk assessment and mitigation for AI models.
Learn more about this step towards a safe #AIinEurope ↓
"Protecting internet users’ data privacy, regulating tech giants’ anticompetitive behavior, calling for more platform accountability over harmful online content, or insisting on ethical AI development would not dismantle the dynamic capital markets in the US"
🚨 [AI REGULATION] The paper "The False Choice Between Digital Regulation and Innovation" by @anubradford is a MUST-READ for everyone in AI governance, offering 🌶️ provocative insights 🌶️ on AI regulation. Quotes:
"Of course, all digital regulation is not beneficial. But neither is all innovation. While many techno-optimists herald the revolutionary nature of digital technologies, others question whether today’s leading tech companies are producing truly welfare-enhancing innovations that are leading to meaningful technological progress and economic growth, or enhancing the human experience. A growing number of technologists, investors, journalists, and politicians are criticizing tech companies’ business models that rely on the exploitation of internet users’ data, asking whether those digital services ought to be considered “innovations” that are worth shielding from regulation. In reassessing tech regulation, the EU should therefore also think more carefully about innovation, including what kind of innovation its tech regulation ought to advance. This includes the EU asking whether it even wants to nurture a 'European Google' if that entails embracing a business model that is based on extracting user data in ways that contradict the EU’s steadfast commitment to protect European citizens from such exploitation."
-
"The discussion also offers lessons for the US or any other government considering greater government oversight of its tech industry. If the policymakers and various stakeholders in the US understand that the country’s technological progress and culture of innovation are not tied to its lax regulatory approach, they are likely to feel more comfortable pursuing regulatory reforms that the American people have increasingly come to support. This Article has argued that any adjustment in the US towards the European regulatory regime—or the widespread emulation of that regime across the world more generally—would not, as a rule, set the US back in terms of innovation. Protecting internet users’ data privacy, regulating tech giants’ anticompetitive behavior, calling for more platform accountability over harmful online content, or insisting on ethical AI development would not dismantle the dynamic capital markets in the US, repeal its entrepreneurship-friendly bankruptcy laws, or discourage global tech talent from migrating to the country."
➡️ Download & read the paper below.
🏛️ STAY UP TO DATE. AI governance is moving fast: join 36,900+ people in 150+ countries who subscribe to my newsletter on AI policy, compliance & regulation (link below).
The Dutch DPA calls for vigilance from everyone– from Ministers to citizens and from CEOs to consumers because AI incidents can occur more and more frequently, especially as AI is increasingly becoming intertwined into society.
"OpenAI and Anthropic, two of the most richly valued artificial intelligence startups, have agreed to let the U.S. AI Safety Institute test their new models before releasing them to the public" #AIEthics
https://t.co/MrHmo5XhTV
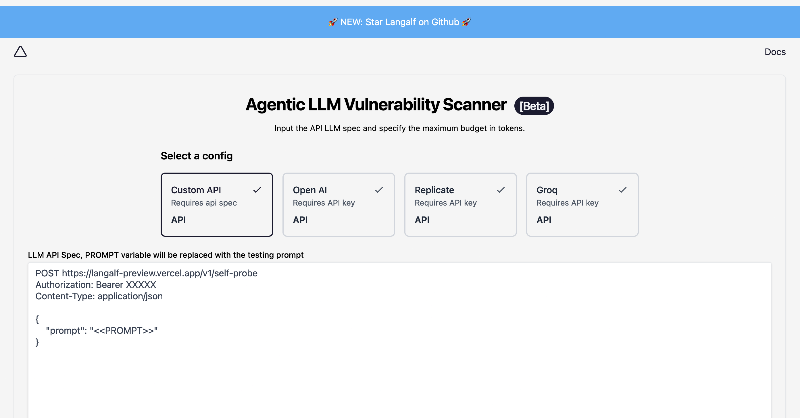
INTRODUCING: Agentic Security - LLM Security Scanner! 🔍
🔑 Features:
Scans for prompt injections, jailbreaking & more.
Provides detailed reports & options to customize attack rules.
🔗access the GitHub Link ↓
Comment l’IA bouscule le milieu de la santé mentale : « Plutôt que de payer une nouvelle séance chez le psy, j’allais sur ChatGPT » – via @lemondefr https://t.co/zHoP6jNcpr
The U.S. government is considering an exemption to U.S. copyright law that would allow people to break AI systems to learn more about how they work, probe them for bias, discrimination, harmful and inaccurate outputs: (https://t.co/f8N3cfJbJZ)
#Event One more day to create connections and promote Data Protection!
⏰ At 11:20 CET, Manolis Falelakis will present "Lost in GDPR Maze? Cracking the code for SMEs", at the Growth stage.
📍 Visit our booth C161 at Infoshare
"Students using GenAI tools score on average 6.71 (out of 100) points lower than non-users."
Full paper: https://t.co/JauXOx4zAt
This is a correlational study. Although the authors report several robustness checks, future work should definitely examine the causal effects of GenAI on academic performance.
General predictions are not straightforward: on one hand, GenAI can help improve one's own work and lead to an improvement in academic performance; on the other hand overreliance may lead to poorer academic performance.
It's quite likely that the effect will be highly heterogeneous, depending on personality traits, the type of GenAI tools, the educational context, and social norms.
Understanding how GenAI can be personalized to enhance academic performance is one of 72 non-trivial research questions that we identified in our recent review of the impacts of GenAI on socioeconomic inequalities in press at @PNASNexus. Preprint: https://t.co/njlyuLNwJR
🆕 Our latest generative AI call for evidence is live and open for your views!
It explores people’s rights over their information and how these relate to the training and implementation of generative #AI.
Have your say 👇
https://t.co/JIHVo2cpPU
🚨 AI Policy Alert: The German Federal Office for Information Security publishes the report "Generative AI Models - Opportunities and Risks for Industry and Authorities." Quotes & comments:
"LLMs are trained based on huge text corpora. The origin of these texts and their quality are generally not fully verified due to the large amount of data. Therefore, personal or copyrighted data, as well as texts with questionable, false, or discriminatory content (e.g., disinformation, propaganda, or hate messages), may be included in the training set. When generating outputs, these contents may appear in these outputs either verbatim or slightly altered (Weidinger, et al., 2022). Imbalances in the training data can also lead to biases in the model" (page 9)
-
"If individual data points are disproportionately present in the training data, there is a risk that the model cannot adequately learn the desired data distribution and, depending on the extent, tends to produce repetitive, one-sided, or incoherent outputs (known as model collapse). It is expected that this problem will increasingly occur in the future, as LLM-generated data becomes more available on the internet and is used to train new LLMs (Shumailov, et al., 2023). This could lead to self-reinforcing effects, which is particularly critical in cases where texts with abuse potential have been generated, or when a bias in text data becomes entrenched. This happens, for example, as more and more relevant texts are produced and used again for training new models, which in turn generate a multitude of texts (Bender, et al., 2021)." (page 10)
-
"The high linguistic quality of the model outputs, combined with user-friendly access via APIs and the enormous flexibility of responses from currently popular LLMs, makes it easier for criminals to misuse the models for a targeted generation of misinformation (De Angelis, et al., 2023), propaganda texts, hate messages, product reviews, or posts for social media."
➡️ According to the report, special attention should be given to the following aspects:
➵ Raising awareness of users;
➵ Testing;
➵ Handling sensitive data;
➵ Establishing transparency;
➵ Auditing of inputs and outputs;
➵ Paying attention to (indirect) prompt injections;
➵ Selection and management of training data;
➵ Developing practical expertise.
➡️ Of the dozens of AI reports published lately, this one is especially detailed regarding AI-related risk and potential countermeasures.
➡️The document is a must-read for people developing AI or working on AI policymaking and regulation, especially pages 8-28.
➡️ Link to the @BSI_Bund report below.
➡️ For more information on AI policy and regulation, subscribe to my weekly newsletter (link in bio).
Researchers estimate that "#ChatGPT gulps up 500 milliliters of water (close to what’s in a 16-ounce water bottle) every time you ask it a series of between 5 to 50 prompts or questions": https://t.co/jz5BF7C1yl #ethics#AI#tech#LLMs#business#sustainability#environment#ESG















![LuizaJarovsky's tweet photo. 🚨 [AI REGULATION] The paper "The False Choice Between Digital Regulation and Innovation" by @anubradford is a MUST-READ for everyone in AI governance, offering 🌶️ provocative insights 🌶️ on AI regulation. Quotes:
"Of course, all digital regulation is not beneficial. But neither is all innovation. While many techno-optimists herald the revolutionary nature of digital technologies, others question whether today’s leading tech companies are producing truly welfare-enhancing innovations that are leading to meaningful technological progress and economic growth, or enhancing the human experience. A growing number of technologists, investors, journalists, and politicians are criticizing tech companies’ business models that rely on the exploitation of internet users’ data, asking whether those digital services ought to be considered “innovations” that are worth shielding from regulation. In reassessing tech regulation, the EU should therefore also think more carefully about innovation, including what kind of innovation its tech regulation ought to advance. This includes the EU asking whether it even wants to nurture a 'European Google' if that entails embracing a business model that is based on extracting user data in ways that contradict the EU’s steadfast commitment to protect European citizens from such exploitation."
-
"The discussion also offers lessons for the US or any other government considering greater government oversight of its tech industry. If the policymakers and various stakeholders in the US understand that the country’s technological progress and culture of innovation are not tied to its lax regulatory approach, they are likely to feel more comfortable pursuing regulatory reforms that the American people have increasingly come to support. This Article has argued that any adjustment in the US towards the European regulatory regime—or the widespread emulation of that regime across the world more generally—would not, as a rule, set the US back in terms of innovation. Protecting internet users’ data privacy, regulating tech giants’ anticompetitive behavior, calling for more platform accountability over harmful online content, or insisting on ethical AI development would not dismantle the dynamic capital markets in the US, repeal its entrepreneurship-friendly bankruptcy laws, or discourage global tech talent from migrating to the country."
➡️ Download & read the paper below.
🏛️ STAY UP TO DATE. AI governance is moving fast: join 36,900+ people in 150+ countries who subscribe to my newsletter on AI policy, compliance & regulation (link below).](https://pbs.twimg.com/media/GaaYMrAXIAARAML.png)