The faster AI scales, the faster confidence in it erodes
For nine years Stanford Human-Centered AI has tracked where AI actually stands and suggests where it’s heading across academia, industry, and government. The 2026 report is out. Here's what stood out.
Adoption is accelerating. Confidence is eroding.
70% of organizations now use AI in at least one business function. But look one layer deeper:
🔹 Among orgs that experienced incidents, those facing 3-5 per year jumped from 30% to 50%
🔹 "Excellent" incident response self-ratings fell from 28% to 18%
Deployment is accelerating. Confidence in handling what breaks is not.
Agentic AI is stuck – and the blocker isn't capability.
🔹 62% cite security as #1 barrier to scaling agentic AI – outpaces #2 by 24 percentage points
🔹 Scaled agent use sits in single digits across virtually every business function
🔹 Only exception: tech sector at 24% in software engineering, 22% in IT, 21% in service ops
Organizations aren't waiting for better models. They're waiting for infrastructure they can trust.
Medical AI hits the same wall – from a different angle.
Medical AI is ready to move into live clinical deployment. Prospective trials grew 28.5% year-over-year (417 → 536 in 2025). The pipeline is there.
But the data isn't:
🔹 Medical imaging training data is roughly 100x smaller than non-medical AI datasets
🔹 Fragmentation across institutions further limits the development of large-scale medical foundation models
The models are ready. The environment to run them on real data is not there yet.
Three sectors. Three blockers. One root cause:
the gap between how fast AI is being deployed and the infrastructure needed to actually trust what it does.
Trust is a vulnerability – and it cannot be legislated away. The policies are already multiplying faster than anyone can implement them – and fragmented regulations across jurisdictions don't provide the technical enforceability that sensitive workloads demand.
It demands proof that you can independently verify, automatically enforce, and continuously audit.
That is exactly what Super Swarm provides. It bridges the gap by delivering cryptographic proof of what actually ran, on which data, and across independently verified infrastructure. Super Swarm makes verifiable confidentiality an architectural guarantee – not a contractual promise.
Ask a hospital to run AI on their patient data. The answer is always the same.
A hospital, a GPU provider, and a medical AI vendor. Everyone has what the others need and none of them can just hand it over. The hospital won't send data to infrastructure they don't control. The vendor won't expose their model. The GPU provider can't take on liability for what runs on their hardware. The model never runs. The patient never benefits.
This is the real reason healthcare AI moves slowly. Not the models. Not the regulations. Trust is a vulnerability. Super Swarm solves it structurally.
In this demo we used a model from the @ProjectMONAI Model Zoo – open source, anyone can take it. The data is another story.
MONAI, originally started by @nvidia and @KingsCollegeLon, is the open-source framework for medical imaging AI. Used at Siemens Healthineers, Mayo Clinic, and beyond. Millions of downloads worldwide.
We deployed one of those models on Super Swarm. The app segments the spleen from a CT scan, calculates volume and area, and returns the results. What makes it different is the execution environment and the verifiable proof it leaves behind.
The computation runs inside a hardware-protected TEE. Patient data is processed within that sealed environment and never exposed to anyone – including us. Whether the infrastructure is public cloud, on-prem, or hybrid. No policy makes that guarantee. The hardware does.
At deployment, Super Swarm generates Deployment Evidence – a cryptographic proof of what code is running, in what environment, on what hardware. No compliance reports. No trust agreements. Access is granted only when the proof matches.
Ask a hospital to run AI on their patient data. With Super Swarm, the answer changes – wherever you run it.
👉 Scan to watch the full demo, or find the link in the comments.
The system works – until you try to automate it.
The trust domain spans every infrastructure, every organization. Data never leaves its sealed environment. Nobody depends on anyone else’s goodwill. And then the product team asks: can we automate this?
AI agents are already operating on behalf of organizations – querying data, calling models, chaining actions across boundaries. Not one request at a time. Thousands per hour. A bank deploys a fraud detection agent. It needs to cross-reference transaction patterns across three partner institutions in real time. Each request takes milliseconds. Each approval takes days. The fraud happened. The access request is still pending.
The verification model still applies. Sealed hardware. Cryptographic proof. A trust domain that spans every cloud and every data center. But the decision about who gets access can't wait for a human to review it. No administrator can keep up. No approval queue moves fast enough. The same rigor that made the first collaboration work becomes the bottleneck that makes the next hundred impossible.
This is Problem #4 of 4. The Access Problem.
Super Swarm solves this with policy-driven access. Each data owner defines their conditions once: what code, what configuration, what hardware qualifies to touch their data. When an agent requests access, it presents a cryptographic proof of its runtime environment – the same proof a human would review manually. The system checks it automatically. Match – execution is allowed. No match – nothing happens. No human in the loop. No delay.
The data owner’s role is simple: define the policy once. The system enforces it at whatever speed the agents operate. A hospital might set conditions as narrow as a specific model, a specific partner, a specific project. Or as broad as any application running inside verified secure hardware with a certified diagnostic framework. The policy reflects their risk tolerance – not the system’s limitations.
Hardware nobody can see into. Proofs that verify in milliseconds. Infrastructure that spans every cloud and every data center. Policies that govern access at the speed AI actually operates. Each piece exists because the one before it made it necessary. None of them works on its own.
That’s the system. That’s Super Swarm.
Trust. Control. Scale. Access. How they connect – link in the comments.👇
The first data collaboration works. Then your AI roadmap asks for ten more.
One partnership took long enough that everyone forgot how it started – legal, compliance, integration, security review. The model trained, the results were good, and everyone moved on. Then the product team came back with more ideas.
Every new partnership becomes its own project – not just operationally, but technically. Even with the same partners, nothing carries over. A new use case means new rules, new pipelines, new approvals. The environment gets rebuilt from scratch.
And the environment itself doesn't stay fixed. What starts as a well-defined setup quickly grows – participants, data, objectives, rules, infrastructure – and becomes impossible to standardize or reuse.
▸ No neutral ground
A global FMCG brand – selling through multiple retail chains – wants to build audience models across three competing retailers. Each retailer sees part of the customer journey. The brand sees patterns across all of them. The value is in combining those views.
They need a shared environment – somewhere all four can bring data without exposing it to each other. But someone has to run that environment. And whoever runs it controls the execution – whether they can see the data or not.
No retailer will use a competitor’s infrastructure. No one agrees on a neutral third party. So they negotiate. And negotiate. Sometimes they never get there. The model never gets built. But even when they do – it works once. It doesn’t scale.
▸ Late to the party
Another version of the same problem. A fourth organization wants to join six months in. In the old model, that becomes everyone’s problem – new agreements, integrations, security reviews. Or they just don’t join at all.
The value is real. Getting there doesn’t scale.
This is Problem #3 of 4. The Scale Problem.
Super Swarm creates one environment all participants can join – a single trust domain that spans infrastructure, for any use case, at any stage.
Each organization stays on its own infrastructure. Data isn’t shared between participants – it only enters the sealed environment for execution and never becomes visible to or controlled by anyone else.
A new organization joins – whether they run on AWS, Azure, GCP, private cloud, or their own infrastructure. It doesn’t matter. Same rules. Same verification. No custom integration. No separate agreements.
To the workload, it’s one environment – without being tied to where it runs or who operates it. Adding a participant doesn’t create a new project – it extends what already exists.
That’s what makes it scale.
Problem #3 of 4. Next: The trust domain now spans every infrastructure, every organization. But what happens when AI agents start operating across it at machine speed – and access has to be granted and enforced without human involvement?
SOC 2 doesn't answer the question that kills the deal.
An enterprise company is evaluating an AI vendor. The demo went well. The use case is clear – processing sensitive contracts and financial records. The price works. And then, one question comes up:
If something changes on your end, or your provider's – what happens to our data?
The vendor points to their SOC 2 certification and their contract with the infrastructure provider. The customer's legal team reads it carefully. It explains how access is managed and what happens if something goes wrong. But it doesn’t define what is technically enforced at runtime – if anything is.
The question behind the question:
🔹 who can access your data at runtime
🔹 who can change how it’s processed
🔹 whether safeguards can be bypassed
Those are questions of enforcement – not just process. The deal goes on hold. Legal gets involved. Months pass. Nothing moves.
The problem isn’t security. It’s control at execution time. This is Problem #2 of 4. We call it the Control Problem.
Super Swarm answers those questions at the level where they matter – execution, not policy.
The encryption keys protecting your environment are generated inside secure hardware on your infrastructure – wherever it is – and never leave it. No copy exists – not with the infrastructure provider, not with us. The code is fully inspectable and runs on standard Kubernetes – your existing stack works without modification. Your infrastructure decisions outlast any vendor relationship.
The system that removes your dependency on partners is itself designed so you never depend on us either.
Problem #2 of 4. Next: you've solved trust between parties and you're not dependent on any single vendor. But what happens when you need to scale across dozens of organizations – all on different infrastructure?
Every enterprise AI roadmap has the same graveyard.
Partnerships that made obvious sense. Models that would have been genuinely better. Deals that everyone wanted – and nobody could close.
The reason is simpler and more frustrating than most people admit: to process data, you have to decrypt it. And the moment it's decrypted, someone on the other side can see it. An admin with the wrong access. A misconfigured bucket. A subpoena nobody anticipated. The exposure doesn't need to be malicious to be real.
So the deal goes to legal. Legal adds clauses. IT adds requirements. Security adds reviews. Six months later, you're still negotiating who gets access to what – and you haven't moved a single row. When the next partnership comes, you start from scratch.
This is why healthcare AI trains on a fraction of the data that exists. Why bank fraud models stay siloed even when sharing signals would catch more fraud. Why the most valuable collaborations – the ones that need data from more than one organization – are the ones that quietly get shelved.
Nobody killed these projects. They just never survived contact with the actual problem.
This is Problem # 1 of 4 that have kept enterprise AI stuck. We call it the Trust Problem.
Super Swarm starts from a different premise entirely.
Your data goes into a sealed hardware execution environment (TEE) – decrypted only inside a processor that nobody outside can access or inspect. The cloud or infrastructure provider can't see in. Your partner can't see in. We can't either.
The obvious question: if nobody can see inside, how do you know what's actually running in there? A black box that keeps attackers out keeps everyone else out too. "Trust us, it's secure" is exactly the kind of answer that got these deals killed in the first place.
So before any data moves, every party gets a cryptographic proof of the exact code, configuration, and hardware their data will run on – verifiable over a standard browser connection, nothing to install. The same way your browser checks a website's certificate, except this one proves the entire execution state, not just identity.
You check the proof. You decide. If anything changes on the other side – different code, different configuration – the proof changes with it, and you see it before your data goes anywhere.
The legal process still takes time. But there's finally a technical answer to the question it could never resolve on its own: how do I know you won't look at my data? The hardware makes it physically impossible – and you verified that yourself, before you sent anything.
Problem # 1 of 4. Next: you no longer have to trust your partners or the infrastructure. So why should you trust us? Spoiler – you shouldn't have to, and we built it that way.
Banks know more about you than almost anyone. And they do nothing with it.
Your salary lands in their account. Your transactions reveal where you go. Their app captures how you behave. Where you live and how you actually live – all visible, all logged.
Customers aren't saying "stop collecting my data." They're saying: "You already have it. Why aren't you using it for me?"
Alex Pyatigorskiy, product executive with a background spanning Disney, global banks, and telecoms, now CPO at Vama, heard this across thousands of customer interviews. And it reframes the whole problem.
Banks are not short on data. But they legally cannot share customer data with partners – and partners won't expose theirs either. So a joint offer that could benefit everyone never gets built. The knowledge stays locked. The customer stays underserved. And loyalty erodes to whoever offers 0.1% more on a savings account.
Super Swarm is the architectural answer to that deadlock – verifiable confidential execution that runs on any infrastructure, so partners can collaborate without the ability to expose what isn't theirs to share.
The bank finally acts on what it knows. The customer gets served. Not by policy. By architecture.
🎥 "Confidentially Yours" with Alex Pyatigorskiy and host Mike Bursell (Advisor, Super Protocol)
Full episode on confidential computing in finance, telco, and agentic AI – where the real use cases are and why trust is still the bottleneck: https://t.co/zN3qED3VA3
67% of companies say security risk is the #1 blocker to scaling agentic AI – according to McKinsey's 2026 AI Trust Maturity Survey.
For a while, the main worry was AI saying the wrong thing – hallucinations, bad outputs, bias.
That’s a model problem.
Agentic AI changes the stakes. As systems become more autonomous, an agent that accesses a database, calls an API, or processes sensitive records is not just a chatbot. It acts.
And the gap between what it's allowed to do – and what actually happens at execution time, and on what data – is where trust breaks down.
That’s an execution problem.
The survey maps it:
🔹 Only ~30% of organizations have mature controls (scoring 3+) for strategy, governance, or agentic AI – meaning 70% are flying partially blind into autonomous systems.
🔹 60% of respondents cite knowledge and training gaps as the leading obstacle to responsible AI implementation (up from 50% last year), showing the skills crisis is worsening, not improving.
🔹 Security/risk concerns (62%) tower over the second-place barrier by over 22% – revealing that fear of autonomous systems outpaces regulatory uncertainty or technical limitations.
This suggests that organizations are less constrained by experimentation capabilities and more by confidence in their ability to safely deploy autonomous systems at scale.
The survey also has a clear signal on the positive side.
Organizations that invest seriously in responsible AI ($25M+) report higher maturity scores and are far more likely to see real EBIT impact above 5%.
And the framing is shifting: AI trust is increasingly seen as a business enabler, not a compliance exercise.
But business-enabling trust requires more than policies – it demands proof you can verify, audit, and enforce.
That's what Super Swarm provides: proof of what actually ran, on which data, and across independently verified infrastructure – even as agentic AI systems operate across environments and organizational boundaries.
There is a tension at the center of every enterprise AI deployment right now.
On one side, clients don't want their data used beyond their own use case – especially when it's proprietary or sensitive. On the other, vendors need data across customers to improve what they deliver. Both sides make sense. And that's exactly the problem. A data processing agreement can document the boundary. But it cannot enforce it.
This is what AI governance frameworks keep running into: the compliance layer describes what should happen. It has no mechanism to prove it did.
Agentic AI makes the problem structurally harder. With a single model call, the risk boundary is relatively clear. With agents operating across tools, APIs, and multi-step pipelines, a failure at one step compounds downstream. Governance written for static systems is already behind – and the frameworks haven't caught up.
The answer isn't a stricter contract. It's removing the need to trust the operator at all.
When AI workloads run inside hardware-isolated TEE environments, the vendor technically cannot access the client's data – not by policy, but by architecture.
Super Swarm provides a cryptographic proof that the execution ran as declared, verifiable by any external party. That is the technical foundation that makes the governance assurance real rather than contractual.
Governance sets the rules. Verifiable execution is what enforces them.
Ray Orife, Head of Data Protection & AI Governance at Evalian, sees the same challenges from the governance side:
🎥 "Confidentially Yours" with host Mike Bursell (Advisor, Super Protocol)
Full episode on AI governance, agentic AI risks, and compliance challenges: https://t.co/MQtjiWBjtx
A physician sees the patient record.
Here's how AI connects the dots – without exposing the data.
🔹 The full picture is there – complaints, history, medications, allergies, notes from previous visits. AI could reason over all of it, flag what matters, catch what's easy to miss. The technology exists. So do the tools. What's been missing is an architecture that doesn't force a choice between using AI and protecting patient data.
When patient data is processed on infrastructure you don’t control, someone else controls how it’s handled – and may access it. Not necessarily – but physically, they can. No contract changes that. No audit prevents it. Some organizations accept that risk. Most can't. So the data stays inside. And the AI stays out.
It doesn't have to be that way.
🔹 How it works
A LangGraph agent collects and structures the patient record from the HIS. The MedGemma model runs in a Super Swarm cluster, inside a confidential execution environment – even outside the clinic, without giving up control. Every request goes through automatic verification before any data reaches the model – ensuring the correct model, the correct configuration, and no operator access. If anything changes, the channel doesn't open. The guarantee doesn't depend on anyone noticing. The pipeline can go further – multiple requests, multiple models, cyclic graphs where one model checks the work of another. LangGraph makes it possible. The confidentiality guarantees apply to every call.
The physician generates a report and watches the pipeline run – each step visible in real time. What's invisible is everything underneath: the verification, the encrypted channel, the confidential execution. What they see at the end is the result: diagnosis, red flags, recommendations. The data stays protected throughout.
🔹 Not just healthcare
This architecture applies wherever sensitive data meets AI.
Banks can’t collaborate on proprietary datasets for fraud detection – not without risk.
Law firms can’t run analysis on client documents using infrastructure they don’t control.
AI governance lacks verifiable proof of what ran, on what data, and how.
With verifiable confidential execution, they can.
The workflow changes.
The guarantee stays the same.
👉 What it looks like in practice – check the full demo https://t.co/5yywY02EuW
Two years ago we validated against the ARM CCA emulator. Today ARM is shipping their own silicon. The TEE landscape just got bigger. Again.
ARM announced the Arm AGI CPU – their first ever production silicon, built on Neoverse V3 cores. Notably: ARM Confidential Computing Architecture (CCA) support is built-in from day one.
Until now, ARM operated purely as an IP licensor – designing CPU architectures and licensing them to manufacturers like Apple, NVIDIA, Qualcomm, Samsung, and AWS, who built their own silicon on top. With the AGI CPU, ARM crosses that line for the first time: expanding from IP provider to silicon manufacturer as well. That shift matters – accelerating ARM CCA adoption across the industry.
ARM CCA hardware is arriving – and more to come:
🔹 NVIDIA’s Vera CPU (including Vera Rubin platform) and Fujitsu’s next-gen server CPU – bringing CCA deeper into AI infrastructure
🔹 ARM AGI CPU is now available to order, with volume shipments expected by end of 2026
🔹 CCC-hosted projects like Islet, led by Samsung, bring ARM CCA to the edge – a signal of where confidential computing is heading next: robotics, IoT, on-device AI
That's exactly why Super Protocol was built TEE-agnostic from the start.
We validated early against the ARM CCA emulator, and later with the Linaro ARM CCA reference stack. Intel TDX, AMD SEV-SNP, ARM CCA, NVIDIA Confidential Computing – our stack is built to support them all. No re-architecture needed. No vendor lock-in.
TEE-agnostic. Cloud-agnostic. Infrastructure-agnostic.
Let's talk.
Everyone is talking about what AI agents are allowed to do. Fewer people are asking whether you can prove they actually did it.
AI agents are moving fast from demos into production – and they are not just answering questions anymore. They access databases, process sensitive records, call internal APIs.
NVIDIA introduced NemoClaw at GTC 2026 to govern exactly that: policy enforcement, network guardrails, privacy routing. The kind of foundation the space needs.
But there is a layer underneath that often gets skipped: Can you verify the environment the agent is actually running in? Because if the infrastructure is not attested, every policy still comes down to trust in whoever is running it.
With Super Swarm, agents run in environments that are hardware-isolated and cryptographically attested – with verifiable evidence of what actually ran and under what conditions, independently verifiable by any party. And critically, execution is not controlled by the same party running the infrastructure.
“Every single company in the world today has to have an OpenClaw strategy,” Jensen Huang said at GTC 2026. OpenClaw is changing how agents are built. NemoClaw helps define how they behave. What’s next is making sure their execution can be trusted too.
Super Swarm makes that verifiable.
Yesterday at OC3, the confidential computing ecosystem shared its insights.
Our COO Yulia Gontar joined the Confidential Computing Consortium (CCC) to showcase the real-world impact of verifiable AI. We brought six projects that solve a universal structural problem: AI workloads require scalable high-performance compute but cannot afford to expose sensitive data or proprietary models to the provider, or any other participant.
The Proof Grid (as presented at OC3):
🔹 Clinical AI: MedGemma-27B achieving a 9.4/10 doctor score inside a verifiably confidential environment.
🔹 Smart Hospital: Real-time EHR-to-Clinician AI on NVIDIA Blackwell (B200) via Nebius.
🔹 FDA Compliance: Cutting AI audit submissions from 4 weeks to 2 hours.
🔹 AdTech: Unlocking 319% growth on external training data for Mars & Realeyes.
🔹 Inter-Institutional AI: Centralized training on decentralized data (Brain Cancer ML in USA) – without exposing a single byte.
🔹 Self-Sovereign AI Cloud: Turning GPU fleets into verifiable environments across cloud and Hyperscalers, like Google – borderless.
The Next Level: Super Swarm – the HTTPS layer for AI. Verifiable autonomous execution that no party can override.
Your Choice of Infrastructure: Our protocol is designed for total flexibility without vendor lock-in. Whether you operate In the Cloud, On-Premise, or in a Hybrid environment, you can scale your AI whenever you need it. This also unlocks one more thing: the latest TEE-enabled hardware – like NVIDIA Blackwell – is available to you the moment you need it, with the exact same verifiable privacy guarantees across the board.
And as you are waiting for the NVIDIA Vera Rubin launch – so are we!
60 seconds. Six proofs. Check below.
PS: @ConfidentialC2 and and Rachel Wan, Outreach Vice Chair of CCC, thank you so much for making us part of your speech!
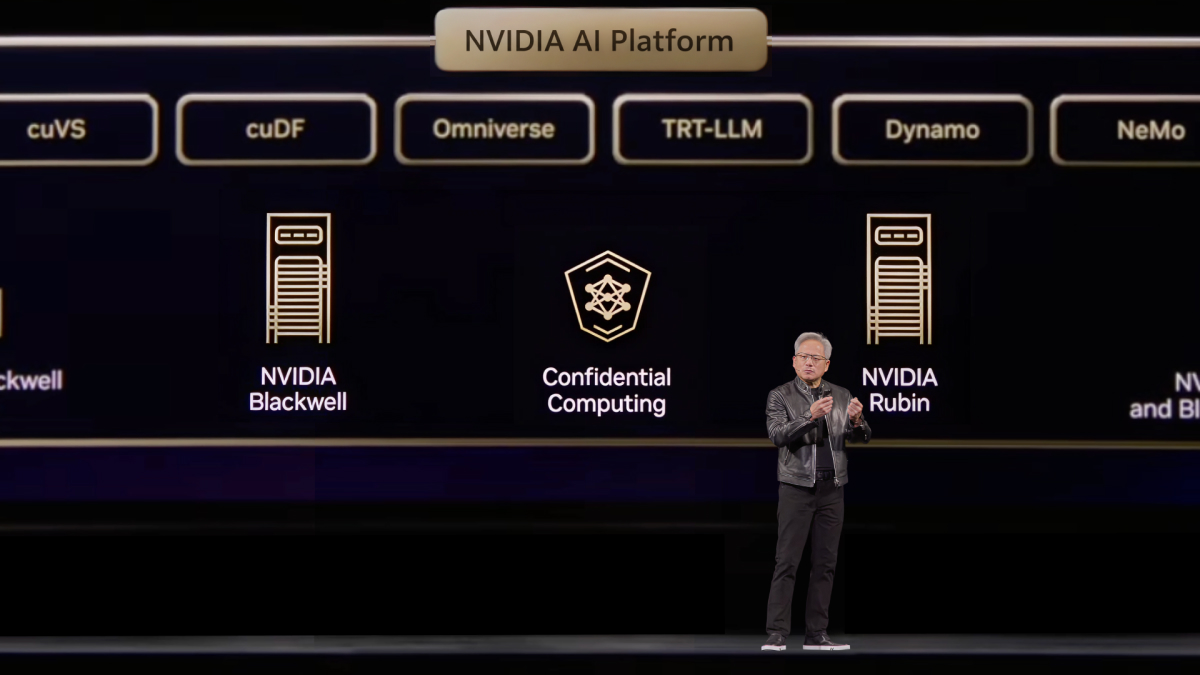
"Confidential Computing is super important." – Jensen Huang, NVIDIA GTC 2026
At GTC 2026, Confidential Computing is placed right at the center of the NVIDIA AI Platform – between Blackwell and Rubin, as part of the foundation.
To scale AI globally, you must protect everything – even from the infrastructure operator itself.
That's the stack we've been building. Super Swarm: open-source by design, self-organizing CC clusters. NVIDIA provides the hardware. Super makes it deployable – any cloud, on-prem, hybrid, and even air-gapped environments. Verifiable by any party, at any time.
🎥 https://t.co/AEC6zVf6O1 on CC (1:02:30)
🔗 https://t.co/BeU63Qzgrw
#GTC2026 #NVIDIA #ConfidentialComputing #TEE #AIInfrastructure #Blackwell #VeraRubin
Sovereign cloud usually means one thing: data stays inside the jurisdiction.
That's necessary. But it's not sufficient.
Jurisdiction defines where data must stay. Compliance defines what the provider is allowed to do with it. But what if the provider simply cannot access it – technically, not just contractually?
That's a different kind of sovereignty. Not a promise. An architectural guarantee.
The demo shows how self-organizing confidential clusters work. The same approach applies if your infrastructure spans different types – on-prem or any cloud setup, single perimeter or distributed datacenters, locked to a specific jurisdiction if required. Including hybrid, when you need to scale out to public cloud with the same security guarantees.
👉 For the complete demo, visit:
🔗https://t.co/dLqmGPtTBE
The early web ran on HTTP. Data moved in plain text. Anyone controlling the infrastructure could read everything – passwords, transactions, records.
HTTPS fixed that. Not by trusting the providers more. By making it impossible for them to read the traffic at all.
Today, AI has the same problem. Your data, your model, your inference – processed on infrastructure you do not own, by providers you can only trust by contract.
We are building the HTTPS layer for AI – based on Super Swarm.
On March 12 the confidential computing ecosystem meets at the Open Confidential Computing Conference (OC3) 2026. As a @ConfidentialC2 member, we are bringing six projects to the conversation.
👉 https://t.co/BeU63Qzgrw
Building proprietary AI is solved. Deploying it safely at scale? That too.
For sensitive industries, the bottleneck is inference. The moment your model and user data must run on infrastructure you don't control, but still depend on for scale. That's the Inference Trust Gap.
Until recently, deployment stagnated at the same structural point: to process complex workloads at scale, you need public cloud compute. But you cannot expose proprietary model weights or sensitive records to the infrastructure provider.
That constraint no longer has to define the architecture.
We ran a benchmark to validate this directly: MedGemma-27B (@GoogleDeepMind) on a single B200 GPU (hosted at @nebiusai) with Super Protocol enabling verifiable confidential execution. MedGemma-27B requires ~54GB VRAM for weights alone. On an H100 (80GB), that leaves minimal headroom for 128K-context workloads at production concurrency. The @nvidia B200 (192GB) changes the equation.
• 64.2 tokens/sec – production throughput
• 128K context window – approximately 300–400 pages of medical history per call
• Input data remains inaccessible to the cloud provider throughout execution
• Model weights, including proprietary fine-tuning, remain protected
This is not just about speed. It is about architectural separation: the cloud provides compute. Execution governance is enforced independently, through hardware attestation – not policy or administrative trust.
Performance, scale, and verifiable confidentiality. Without choosing between them. Check how the full stack works: @vllm_project, TEE-based hardware isolation, and Super Protocol's execution governance layer
👉 https://t.co/R8ndgefdyh
Can you ensure that your LLM deployment is truly confidential?
Large LLMs require significant GPU resources. GPU cloud providers make that compute accessible. But when proprietary model weights or third-party data are involved, deployment becomes more than just infrastructure.
Confidentiality at runtime should not rely on trust in the operator, nor should it introduce operational complexity.
Super Swarm builds on the core Super Protocol principles, with a redesigned confidential infrastructure layer ready for autonomous AI at scale.
To demonstrate how this works in practice, we recorded a new Super Swarm walkthrough covering the full confidential LLM deployment flow – from cluster creation and LLM deployment to independent verification.
Using an inference workload as the example, the walkthrough shows:
- confidential cluster launch
- LLM deployment on cloud GPUs
- automatic generation of Deployment Evidence (cryptographic proof that the environment has not been altered)
- secure model access via both API and application endpoints, with verification preserved in both cases
In previous posts, we discussed the importance of decoupling execution control from infrastructure as the foundation of verifiable confidential AI.
Now you can see it in action.
👉 For the complete demo, visit:
🔗 https://t.co/zKzC1VI6LC
👉👉 Bookmark the Super Swarm demo series to see additional use cases in action:
🔗🔗 https://t.co/ZAe2cIzPKb
Confidential fine-tuning on external data is not just about isolation. The real question is whether training runs under conditions no single participant can alter – and whether that can be independently verified.
When external data is involved, hardware isolation alone is not enough. Data owners require enforceable guarantees that execution cannot be modified or overridden by any party – including the cloud provider.
This is exactly where GPU clouds either become trusted compute platforms for sensitive AI – or remain generic capacity providers.
TEE isolation protects data-in-use. But isolation alone does not enable collaboration across organizations. Fine-tuning on external data requires something fundamentally stronger: provable architectural sovereignty – where execution is governed by cryptographic rules rather than administrative control.
Super Protocol adds a verifiable confidential execution layer on top of existing GPU cloud infrastructure. The cloud continues to provide GPU capacity and operate hardware.
What changes is how execution is governed.
Execution approval becomes architectural and cryptographic – not administrative. Compute supply and execution authority are structurally decoupled. Training proceeds only when predefined conditions are automatically validated through hardware attestation and workload verification. If they are not met, execution does not start. After completion, independent parties can verify that the training ran as intended – without requiring privileged access to the infrastructure.
In this model, the GPU cloud supplies compute – but execution conditions cannot be altered by any single party, including the cloud provider or Super itself. That shift is what allows GPU clouds to host confidential fine-tuning across independent organizations – without requiring data transfer or centralized trust.
This architecture enabled Realeyes to break the fine-tuning deadlock. They gained access to 319% more sensitive training data – resulting in measurable improvements in model quality and deeper insights for global ad optimization.
👉 Check case study:
🔗 https://t.co/QyxbzduAg1
Modern GPUs are becoming standard. What sets clouds apart now is how AI runs on them.
Super Protocol turns #NVIDIA H100, H200, and Blackwell GPU fleets into verifiable, privacy-preserving AI clouds.
It rolls out as a ready-to-run layer on top of existing cloud infrastructure, handling environment attestation, policy enforcement, and integrity checks end-to-end – without requiring providers to redesign their stack.
For customers, it feels like a standard AI cloud with familiar tooling and workflows. The difference is architectural: workloads run in confidential mode and are automatically verifiable.
Open-source by design, Super Protocol removes vendor lock-in and enables collaboration across clouds under the same provable privacy guarantees.
For sensitive and regulated workloads, this is what makes cloud deployment possible. Without verifiable execution, sensitive AI remains limited to isolated pilots, on-prem infrastructure, or tightly controlled environments. With it, entire ecosystems can operate on shared GPU infrastructure.
In one real-world healthcare project, this brought together:
🔹 a GPU cloud provider
🔹 a medical AI solutions provider
🔹 an EHR provider
🔹 and clinics running AI on live clinical data
– All without exposing patient records, proprietary model logic, or relying on policy-based trust.
Super Protocol acts as a neutral, verifiable execution layer across the stack, enabling each party to operate on shared GPU infrastructure while retaining control over its own data, models, and compliance boundaries.
That is what makes GPU clouds ready for sensitive #AI workloads.
👉 Check case study:
🔗 https://t.co/bbbMPhKZuV
#ConfidentialComputing #AIInfrastructure #GPUCloud #TEE