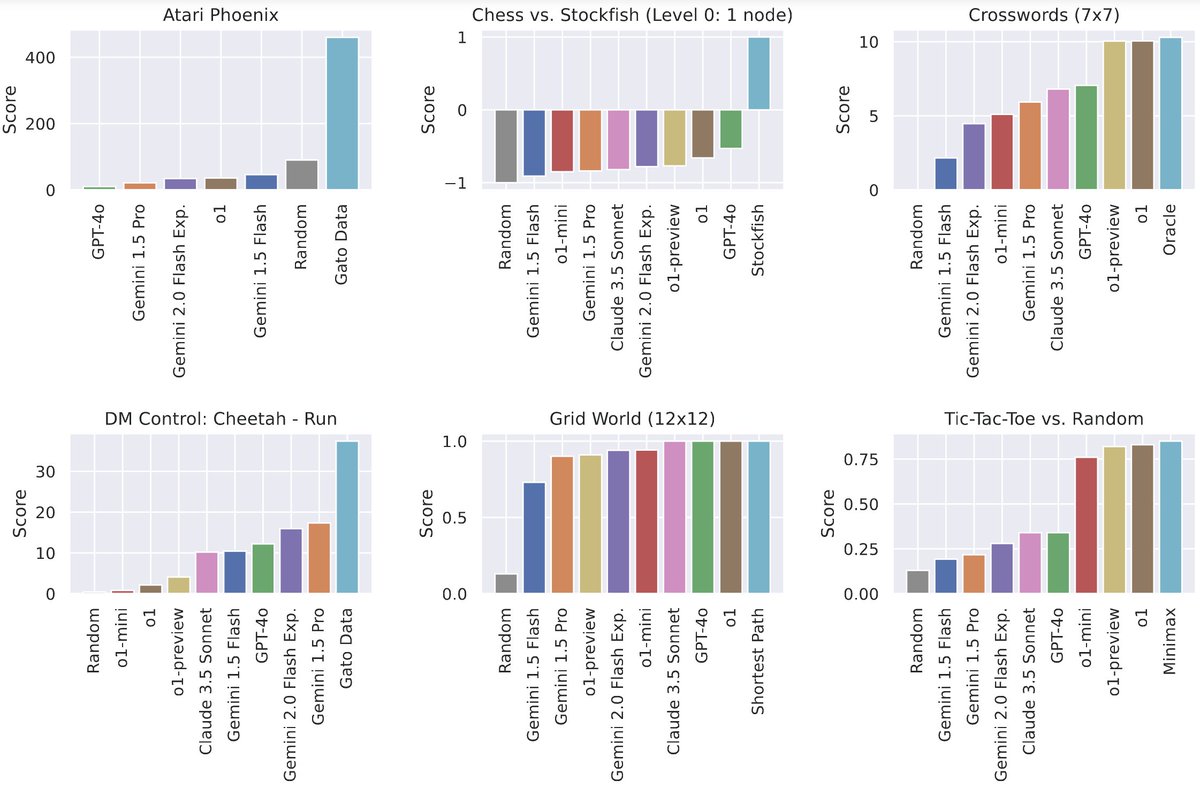
Our LMAct benchmark evaluates LMs in dynamic environments (Atari, chess, DM Control) in the zero-to-many-shot regime (up to 1M tokens)
With @PardoFab, @SirrahChan, @bonniesjli, Volodymyr Mnih, and Tim Genewein
📅 Tue 15 July
⏰ 11:00 – 13:30
📍East Exhibition Hall A-B #E-1804
@hugo_larochelle It's been a real privilege to spend time with you over the past year, Hugo. We'll greatly miss you. I wish you all the best for the future and hope to see you around in Montreal!
Thrilled to be at #NeurIPS this week! Excited to reconnect with friends and colleagues I haven’t seen in a while. If you’d like to meet up, don’t hesitate to reach out, I’ll be stopping by the @GoogleDeepMind booth occasionally.
Genie 2 🧞♂️ is a very impressive model and the perspective of generating endless, unique worlds is incredibly exciting! Collaborating with the team has been a truly fun and inspiring experience 😁
Introducing 🧞Genie 2 🧞 - our most capable large-scale foundation world model, which can generate a diverse array of consistent worlds, playable for up to a minute. We believe Genie 2 could unlock the next wave of capabilities for embodied agents 🧠.
We explored how LLMs tackle low-level control tasks across diverse domains. While there's room to grow, in-context learning and existing image/text tokens can handle diverse observation and action spaces. No special tokens or adapters are needed to play games or control robots!
Ever wonder how well frontier models (Claude 3.5 Sonnet, Gemini 1.5 Flash & Pro, GPT-4o, o1-mini & o1-preview) play Atari, chess, or tic-tac-toe?
We present LMAct, an in-context imitation learning benchmark with long multimodal demonstrations (https://t.co/ZIHCv06EqX).
🧵 1/N
@VittorioLaBarb2 Huge congratulations, Vittorio! 🎉 Your hard work and dedication have really paid off—very well deserved! Looking forward to celebrating this huge milestone with you soon 🥳
The General Agents team at @GoogleDeepMind Toronto is looking for a new Research Scientist. Apply if you have the right skills and want to work with us on building generalist agents that can interact with simulated and real world environments!
https://t.co/J2nPoMKCK5
Google DeepMind announces Vision-Language Models as a Source of Rewards
paper page: https://t.co/Nv8RG18nkO
Building generalist agents that can accomplish many goals in rich open-ended environments is one of the research frontiers for reinforcement learning. A key limiting factor for building generalist agents with RL has been the need for a large number of reward functions for achieving different goals. We investigate the feasibility of using off-the-shelf vision-language models, or VLMs, as sources of rewards for reinforcement learning agents. We show how rewards for visual achievement of a variety of language goals can be derived from the CLIP family of models, and used to train RL agents that can achieve a variety of language goals. We showcase this approach in two distinct visual domains and present a scaling trend showing how larger VLMs lead to more accurate rewards for visual goal achievement, which in turn produces more capable RL agents.
After getting a glimpse of the incredible New Orleans, I'm excited to be at @NeurIPSConf all week! Let me know if you'd like to chat, or come and say hi at the @GoogleDeepMind booth on Tuesday or Wednesday afternoon. I'll be with the #GeminiAI team.
Gemini is a suite of incredibly powerful and general models that push the limits of artificial intelligence. Participating in this massive effort made me feel like I was part of history in the making and I can't wait to see what lies ahead! #GeminiAI
https://t.co/sv2m0eka10
The Gemini era is here. Thrilled to launch Gemini 1.0, our most capable & general AI model. Built to be natively multimodal, it can understand many types of info. Efficient & flexible, it comes in 3 sizes each best-in-class & optimized for different uses https://t.co/VUu1277bC2
I’m very excited to share our work on Gemini today! Gemini is a family of multimodal models that demonstrate really strong capabilities across the image, audio, video, and text domains. Our most-capable model, Gemini Ultra, advances the state of the art in 30 of 32 benchmarks, including 10 of 12 popular text and reasoning benchmarks, 9 of 9 image understanding benchmarks, 6 of 6 video understanding benchmarks, and 5 of 5 speech recognition and speech translation benchmarks. Gemini Ultra is the first model to achieve human-expert performance on MMLU across 57 subjects with a score above 90%. It also achieves a new state-of-the-art score of 62.4% on the new MMMU multimodal reasoning benchmark, outperforming the previous best model by more than 5 percentage points.
Gemini was built by an awesome team of people from @GoogleDeepMind, @GoogleResearch, and elsewhere at @Google, and is one of the largest science and engineering efforts we’ve ever undertaken. As one of the two overall technical leads of the Gemini effort, along with my colleague @OriolVinyalsML, I am incredibly proud of the whole team, and we’re so excited to be sharing our work with you today!
There’s quite a lot of different material about Gemini available, starting with:
Main blog post: https://t.co/NzSycJl7aE
60-page technical report authored by th Gemini Team: https://t.co/CEdMRyYSLo
In this thread, I’ll walk you through some of the highlights.
I am incredibly happy to announce that I am joining DeepMind Toronto as a Research Scientist 🎉🇨🇦 Working at @DeepMind on the team led by @VladMnih is a great honor for me. I can't wait to get started!