Frontier perceptive models are finally cheap enough to call dozens of times on a single task. This means visual agents are now becoming feasible and new capabilities will emerge.
The range of companies in our pipeline is wider than I expected. Demand is past what our research-first team can serve; we need someone to close the loop.
We're hiring our first DevRel Engineer (aka Hacker-in-Residence) at Perceptron.
Demand for our model Mk1 is outpacing what our research-first team can serve. You'll help us close the loop between our models and the people building on them.
My favorite model release I've worked on - the past few months📈performance on high number and in-context pointing reinforced why ML is a rewarding field to work in. The ROI of thinking creatively about data is very high, qualitative skills and taste are enormous differentiators
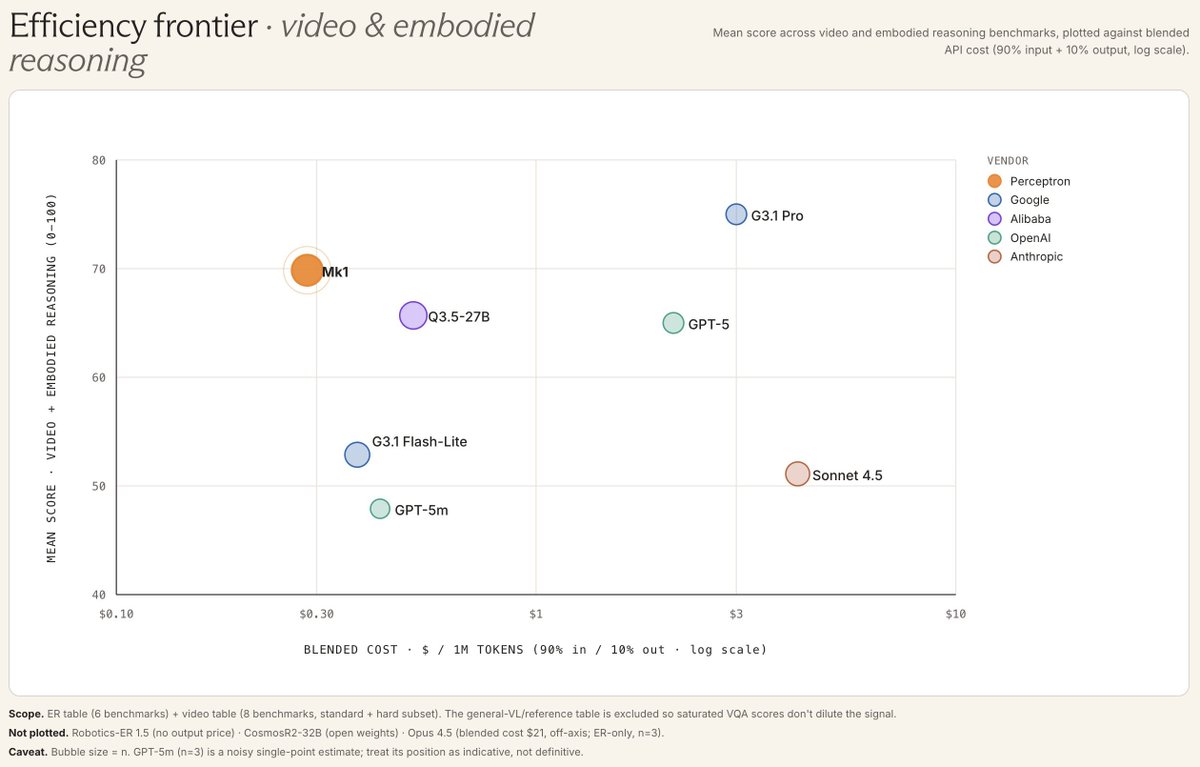
Perceptron Mk1 is live on OpenRouter, built by @perceptroninc.
Frontier video and embodied reasoning in a vision-language model. Analyzes video at a dynamic frame rate (up to 2 FPS) across a 32k multimodal context, with hybrid reasoning and structured spatial primitives (points, boxes, polygons, clips) as first-class outputs.
Despite having vision, most AI agents still struggle to see. General-purpose multimodal models are powerful, but they’re expensive for every visual task. We built something better: Perceptron's MCP gives any agent stronger vision capabilities through Isaac with far lower cost.
Looking for someone to lead Brand Design at @browsercompany.
The ideal candidate views themselves as an artist, doesn’t work in tech, and lets their portfolio speak for itself.
We’ll pay you more than you make now & ask you to design not manage.
Josh @ the browser . company
One research direction we're exploring: large models are good coordinators. Specialized models are good at perception and tactical things like desktop usage and visual grounding. Physical agents probably need both. Our Isaac series of models lets us explore this.
This paper is quietly one of the most damning findings about current LLM architecture.
Google Research tested 7 models across 7 benchmarks. The intervention was embarrassingly simple: paste the prompt twice. The result: 47 wins out of 70 tests, zero losses. Gemini Flash-Lite went from 21% to 97% accuracy on a name retrieval task. By copying and pasting.
The reason this works tells you everything about the gap between how people think LLMs process information and how they actually process it. Every token can only look backward. So when you write “here’s a list of 50 names” followed by “what’s the 25th name?”, the list tokens were processed with zero awareness that a question was coming. The question tokens can see the list, but the list never saw the question.
Repeating the prompt gives every token a second pass where it can attend to everything else. You’re essentially hacking bidirectional attention into a unidirectional system. And the cost is nearly zero because prefill is parallelized on modern hardware.
But here’s what makes this actually interesting: reasoning models already do this. When you enable chain-of-thought, the gains from repetition almost entirely disappear (5 wins, 1 loss, 22 ties). That means reasoning models trained with RL independently learned to repeat the user’s prompt back to themselves before answering. The “thinking” that costs you 10x more tokens and 5x more latency is partly just the model giving itself a second look at your input.
Which means a meaningful chunk of what we’re paying for with “reasoning” tokens could be replicated for free at the architecture level. The entire prompt repetition paper is an accidental proof that causal attention is leaving massive performance on the table, and that the industry’s current fix (burn more tokens thinking) is the expensive workaround for a structural limitation nobody’s addressing directly.
The teams that figure out efficient bidirectional attention at inference time will compress the reasoning tax to nearly zero. Everyone else will keep selling you tokens to solve an architecture problem.
.@chasi_ai deploys AI agents for the $1T+ equipment distribution industry, helping dealers sell more, respond faster, and maximize fleet utilization - 24/7.
Congrats @akashpavan & @SarmanAulakh on the launch!
https://t.co/fGSpAPnlxk
Since I started working on multimodal models 4 years ago, one harsh realization was that standard architectures don't allocate compute intelligently across modalities. We tried dense multimodal models (Chameleon) and MoE extensions (MoMA)... none felt quite right. Today we're proposing data sparsity as a new axis to solve this.
Paper and blog below.