In our paper https://t.co/thETwnqw9u on the arXiv today, we present results from a study investigating the energy-efficiency advantage that could be achieved in executing state-of-the-art Transformer models on optical hardware.
🎉 We are thrilled to announce the release of the latest version of mlforecast a #Python library for Scalable #machinelearning 🤖 for #timeseries#forecasting
🚀 This version comes with exciting new features that are sure to make forecasting even more efficient and accurate
🧵
Cyborgism Research Agenda
-Does not try to make GPT an agent
-Leverages GPT as a general simulator
-LLMs reason from scratch about any situation
-Advanced prompting interfaces
-Branches GPT chains of thought
-Injects variance into human thoughts
Post https://t.co/XUv0S4dcmx
This quietly slipped out yesterday. Briefly, the UK is traditinally a strong source of clinical trials but patient recruitment has fallen by 44% (!) due to slow & unpredictable set-up of research sites.
Independent review into UK clinical trials https://t.co/fQmrndiqtH
One exciting feature of our partnership with AWS is that we now have 1000+ GPUs to start training really large models at @huggingface 🔥🔥🔥!
We’ll be working hard to make closed models open, starting with LLMs and friends 🤓
Which closed models would you like to be open?
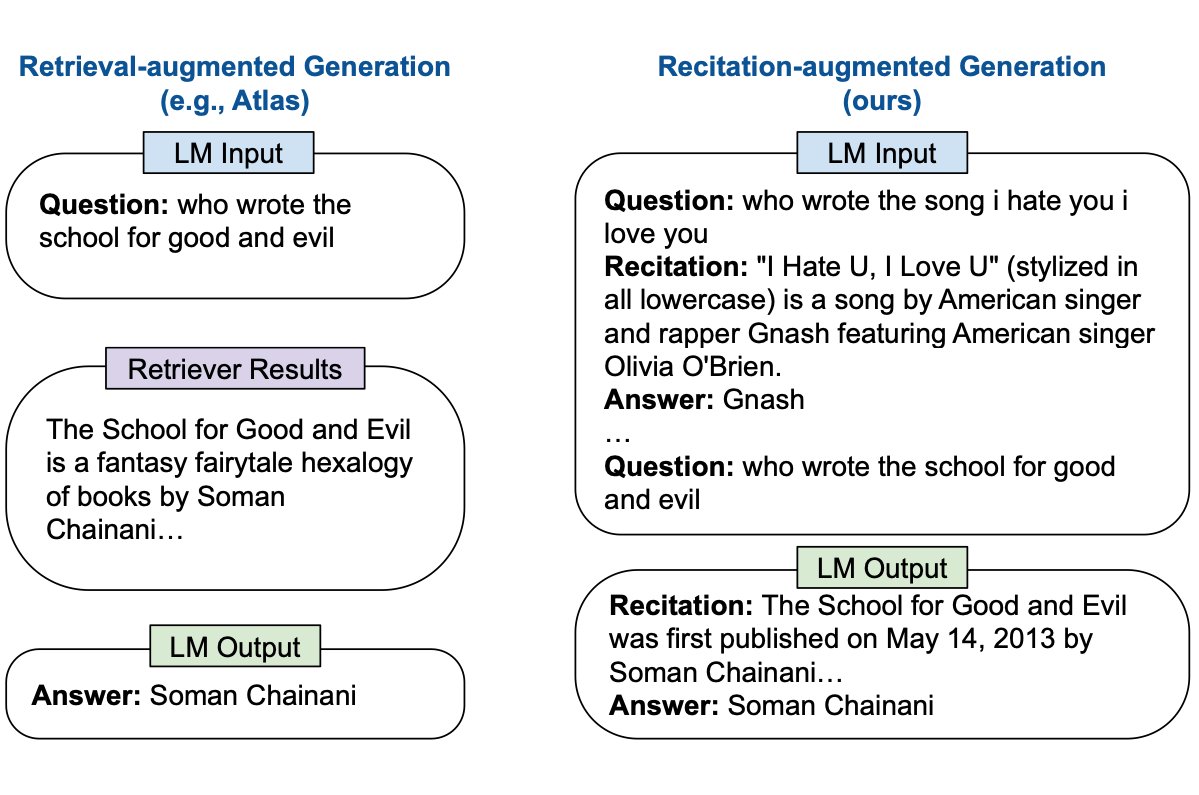
Recitation-Augmented LLMs
-Usually: Retrieve relevant docs & give to LLM to answer
-Instead: Recite relevant passages from LLMs' own memory via sampling,
then produce final answer
-State-of-the-art on closed-book Q&A
Paper https://t.co/9UxJdIODaX
Code https://t.co/vXtc2HAmh4
German AI startup @Aleph__Alpha claims it will have a 300-billion parameter Large Language Model "Luminous-World" trained this year for “highly complex and critical applications”
(GPT-3 has 175 billion parameters)
We're excited to welcome FuseMedML to the PyTorch ecosystem!
FuseMedML is part of the BiomedSciAI organization which provides tools for AI-based accelerated discovery of biomarkers and molecules in the biomedical domain.
See the latest here: https://t.co/7d3ULIocVa
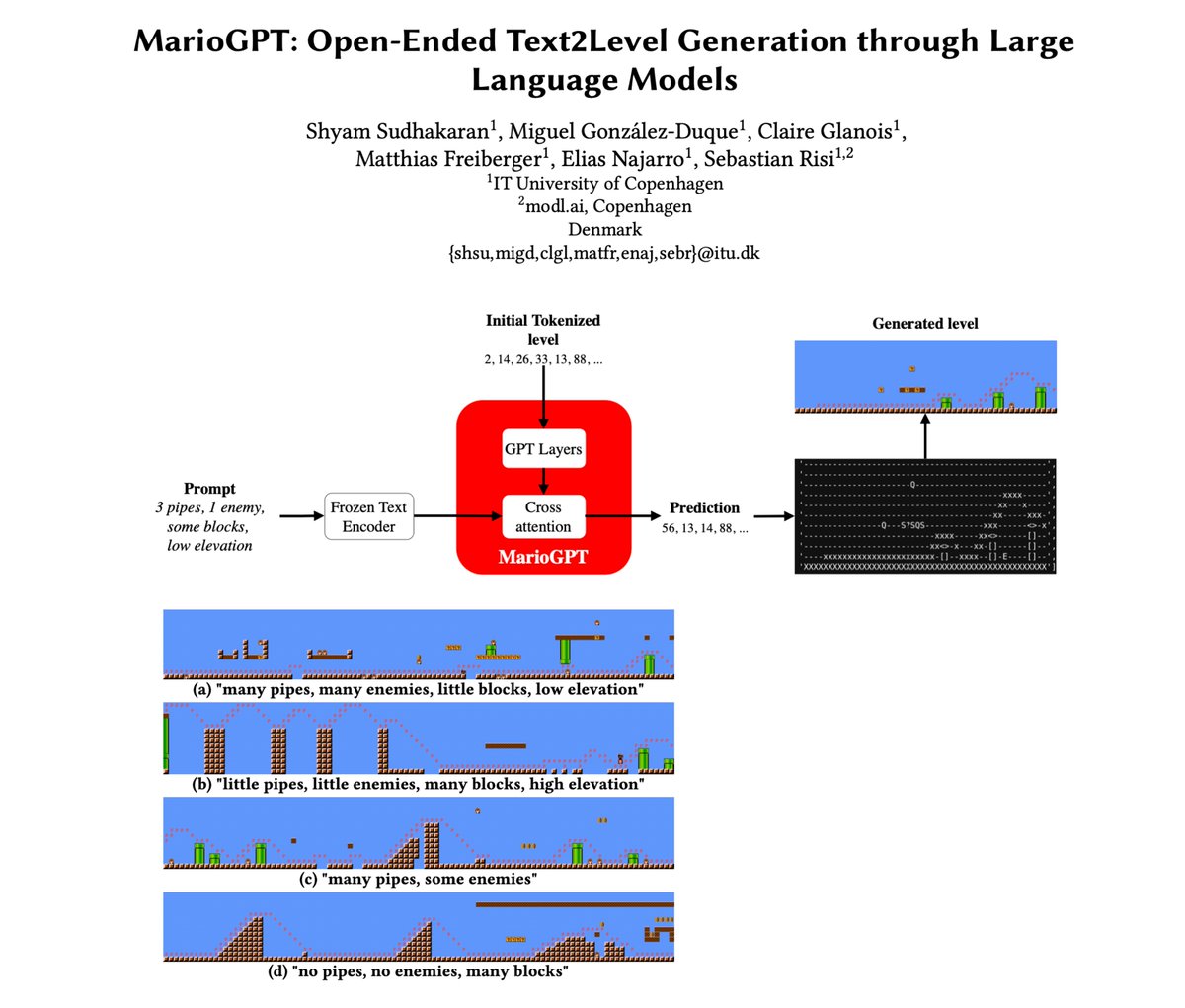
"MarioGPT: Open-Ended Text2Level Generation through Large Language Models"
This looks like a pretty fun and creative project!
The best part, it's based on a distilled GPT-3 model and can be trained on a single GPU.
In the last week, three people on reddit/r/statistics have asked about testing whether a sample came from a Gaussian distribution.
The answer is that you should never test for normality. The result is a non-answer to the wrong question.
https://t.co/ZJIyvJHrKL
.@TalarianHQ's `GPT for Sheets™` is the gift that keeps on giving! 🔥
Look at how easy it is to create personalized content with it, thanks to #GPT3's seamless integration! 🤯👇
Get the add-on here:
🔗https://t.co/3xUwkhBkc4
@nonmayorpete I think this link will be useful: https://t.co/ouVsMMIcES
the paper: https://t.co/XNBFHoiKby
also they released a dataset:
https://t.co/uO43OuaGyS
it's a shame the actual library is not available but the research article is pretty good
Batch normalisation appears to be falling out of favour (probably for the best IMO, so many bugs end up being batchnorm bugs😬).
One area where it persists is GAN discriminators (e.g. in StyleGAN-T and VQGAN). Are there any other settings where batchnorm is still hard to avoid?
The first text line detection model for historical documents available on @huggingface : paper+code+models, all open-source https://t.co/SxG8hRlNd9 https://t.co/D8bEg4a3f7 #digitalhumanities@LitisLab
[CV] Learning Good Features to Transfer Across Tasks and Domains
P Z Ramirez, A Cardace, L D Luigi, A Tonioni, S Salti, L D Stefano [University of Bologna & Google] (2023)
https://t.co/fSwcZIFtCN
#MachineLearning#ML#AI#CV
[1/2]
Just published a literature review on scaling laws @EpochAIResearch! I collected a database of scaling laws for different tasks and architectures and reviewed dozens of papers in the scaling law literature.
Check out the database!
https://t.co/Hr3NTVQzwW
🧵



















![fly51fly's tweet photo. [CV] Learning Good Features to Transfer Across Tasks and Domains
P Z Ramirez, A Cardace, L D Luigi, A Tonioni, S Salti, L D Stefano [University of Bologna & Google] (2023)
https://t.co/fSwcZIFtCN
#MachineLearning #ML #AI #CV
[1/2] https://t.co/9TbdEohiLK](https://pbs.twimg.com/media/Fng4Ko5agAA68gZ.jpg)
![fly51fly's tweet photo. [CV] Learning Good Features to Transfer Across Tasks and Domains
P Z Ramirez, A Cardace, L D Luigi, A Tonioni, S Salti, L D Stefano [University of Bologna & Google] (2023)
https://t.co/fSwcZIFtCN
#MachineLearning #ML #AI #CV
[1/2] https://t.co/9TbdEohiLK](https://pbs.twimg.com/media/Fng4KlVaYAAT6IV.png)
![fly51fly's tweet photo. [CV] Learning Good Features to Transfer Across Tasks and Domains
P Z Ramirez, A Cardace, L D Luigi, A Tonioni, S Salti, L D Stefano [University of Bologna & Google] (2023)
https://t.co/fSwcZIFtCN
#MachineLearning #ML #AI #CV
[1/2] https://t.co/9TbdEohiLK](https://pbs.twimg.com/media/Fng4KlLaIAAkl9x.jpg)













![fly51fly's tweet photo. [CV] Learning Good Features to Transfer Across Tasks and Domains
P Z Ramirez, A Cardace, L D Luigi, A Tonioni, S Salti, L D Stefano [University of Bologna & Google] (2023)
https://t.co/fSwcZIFtCN
#MachineLearning #ML #AI #CV
[1/2] https://t.co/9TbdEohiLK](https://pbs.twimg.com/media/Fng4KvCaQAELufX.jpg)





























