Introducing Cohere's first open-source coding model: North Mini Code
Small & efficient, designed for agentic performance and built for community input.
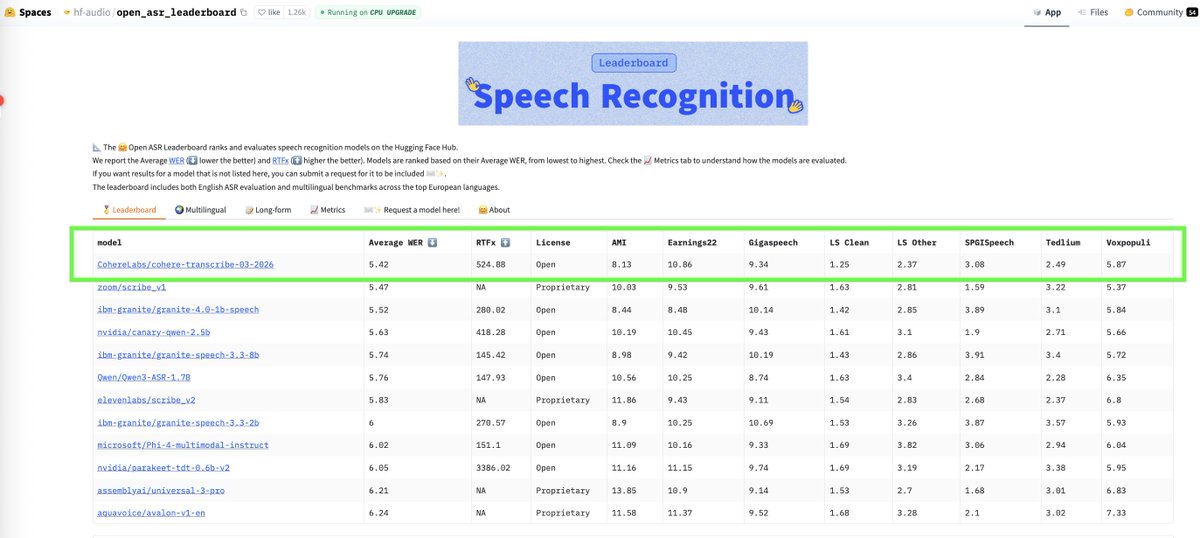
Happy to share what I've been working on recently: today we release Cohere Transcribe, a state-of-the-art speech recognition model that beats both commercial and open-source models to land at #1 on the Open ASR Leaderboard!
Excited and proud to introduce our latest: Cohere Transcribe, the best dedicated ASR model in the world. #1 EN HF leaderboard, SotA human evals, ahead of ElevenLabs, Qwen3, Mistral, Kyutai, and OpenAI. 14 supported languages. Apache 2.0, on HF for you to try.
Our first audio model and a key step in powering North experiences. https://t.co/HkA8XaGfra
I thought the path to variable-length video was frame-wise autoregressive with complex forcing schedules, but I was wrong!
The solution is simple! Flowception, using frame insertions to model any-order video generation.✅
Arxiv: https://t.co/fOGgonQbWv
Project page: https://t.co/PH5gwBITq3
Great collaboration with Jakob, @inthebrownbag, and @RickyTQChen on this work, and led by Tariq!
Say hello to DINOv3 🦖🦖🦖
A major release that raises the bar of self-supervised vision foundation models.
With stunning high-resolution dense features, it’s a game-changer for vision tasks!
We scaled model size and training data, but here's what makes it special 👇
The code and model weights for this paper are finally open! Despite being a little late for releasing them, I hope you will find them useful!
Code: https://t.co/HndCxJVuJK
Models:
- (ViT-G): https://t.co/4bHJsM67be
- (ViT-B): https://t.co/7HtXYH9yLu
Excited to present our work "Improving the scaling laws of synthetic data with deliberate practice", tomorrow at #ICML2025
📢 Oral: Wed. 10:45 AM
📍 West Ballroom B (Oral 3C Data-Centric ML)
🖼️ Poster:
🕚 11:00 AM – 1:30 PM
📍 East Exhibition Hall A-B (Poster Session 3 East)
🚀 New Paper Alert!
Can we generate informative synthetic data that truly helps a downstream learner?
Introducing Deliberate Practice for Synthetic Data (DP)—a dynamic framework that focuses on where the model struggles most to generate useful synthetic training examples.
🔥 On ImageNet-1k, DP reduces dataset size by 55 million examples while outperforming prior synthetic benchmarks!
📄Paper: https://t.co/oiRlc7MNlz
🧵Key takeaways ⬇️