Don’t miss @dohmatobelvis presenting our latest work, “Why less is more (sometimes): A theory of data curation” at #ICLR2026!
Swing by our poster at the main conference to chat:
📅 Saturday, April 25
🕒 3:15pm–5:45pm
📍 Pavilion 3, P3-#1816
Come learn about computer-use agents with OpenApps, oral at #ICLR2026 in Rio 🇧🇷on Saturday 2:35pm ET Room 204 or stop by our poster in the morning https://t.co/5gLvS3ztdb w/ @karen_ullrich
https://t.co/ohMN7s2Vo4
I am soon heading to Rio for #ICLR2026!
It is going to be a packed week: including an oral presentation of OpenApps, our work on measuring how reliable UI agents really are when the apps they interact with change.
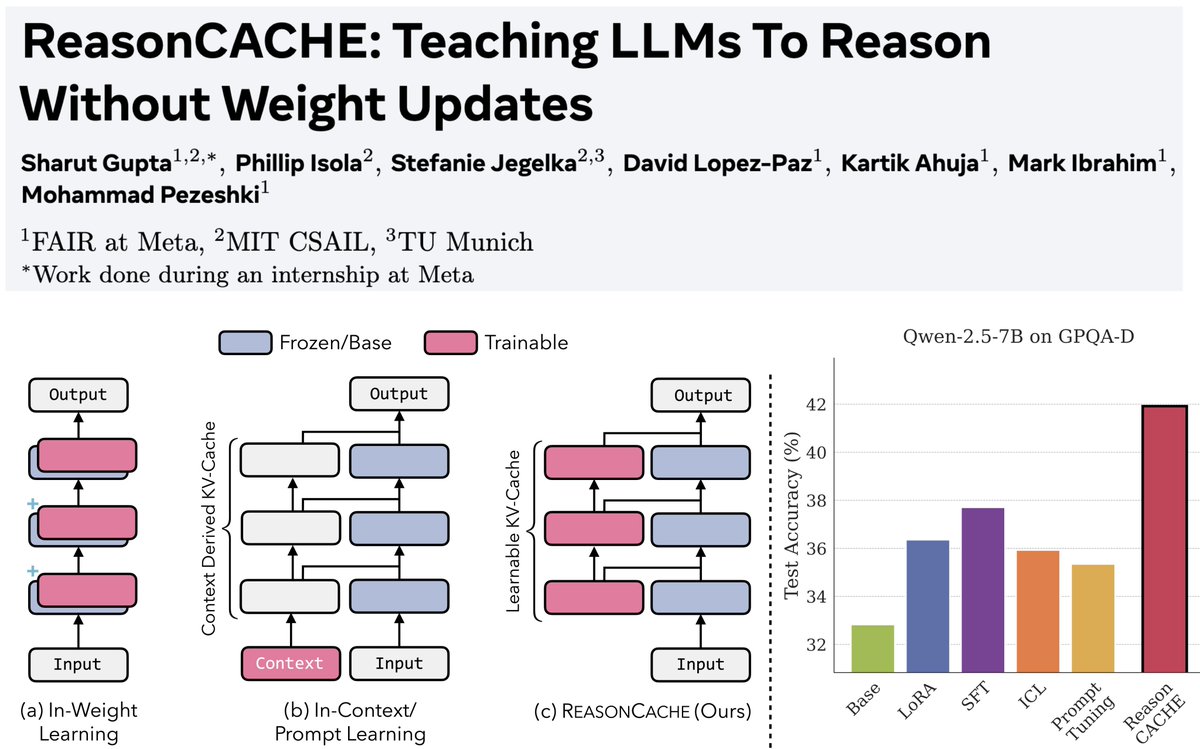
1/n Can LLMs learn to reason on hard benchmarks like AIME and GPQA purely through context, without SFT, RL, or any weight updates?
Turns out… Yes! And it can have strong performance while being highly efficient
Paper: https://t.co/mEoaIst6cX
Blog: https://t.co/lZli7qY4Jz
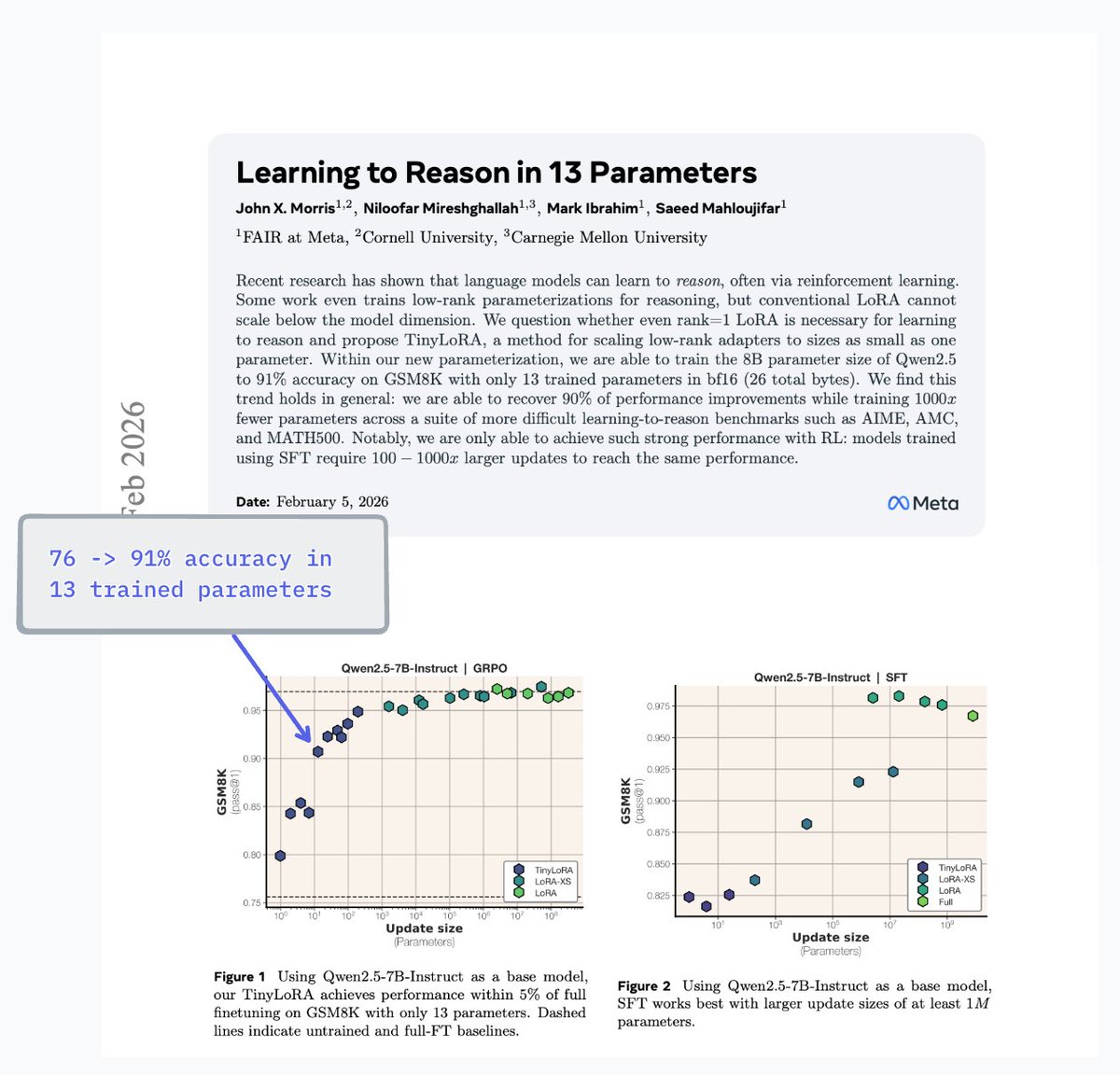
at long last, the final paper of my phd
🧮 Learning to Reason in 13 Parameters 🧮
we develop TinyLoRA, a new ft method. with TinyLoRA + RL, models learn well with dozens or hundreds of params
example: we use only 13 parameters to train 7B Qwen model from 76 to 91% on GSM8K 🤯
One can manipulate LLM rankings to put any model in the lead—only by modifying the single character separating demonstration examples. Learn more in our new paper https://t.co/D8CzSpPxMU
w/ Jingtong Su, Jianyu Zhang, @karen_ullrich , and Léon Bottou.
1/3 🧵
My first PhD paper is out! 🎓
"What Drives Success in Physical Planning with Joint-Embedding Predictive World Models?"
tl:dr: JEPA-WMs for robotics: learn dynamics on top of visual encoders, optimize actions towards goal 👇
w/ @JimmyTYYang1, Jean Ponce, @AdrienBardes, @ylecun
Release Day 🎉
Meet OpenApps — a pure-Python, open-source ecosystem for stress-testing UI agents at scale.
Runs on a single CPU. Generates thousands of unique UI variations. And it reveals just how fragile today’s SOTA agents are.
(Yes, even GPT-4 and Claude struggle.)
Stop by the Meta booth tomorrow, Wednesday Dec 3rd at #NeurIPS in San Diego! 🤖📱
We demo our new research environment, OpenApps, for digital agents. Generate thousands of app versions to train and evaluate multimodal agents to use apps like humans do.
Not attending? Stay tuned
With LeJEPA (https://t.co/RR9kcXEqSk) it has never been easier to train JEPAs! And this matters A LOT because JEPAs have numerous provable benefits over the good-old reconstruction based methods (https://t.co/bOg6uibdHP).
NeurIPS spotlight: Wed, 11 a.m. PST, Hall C,D,E #2613
✅ 22k multi-scene questions
✅ New scenes not in existing web data
✅ Runs in ~15 min on one GPU
Work led by Candace Ross in collaboration with Florian Bordes, @adinamwilliams, and @polkirichenko .
Check it out on HuggingFace & ArXiv: https://t.co/LR1Lf97y3Z
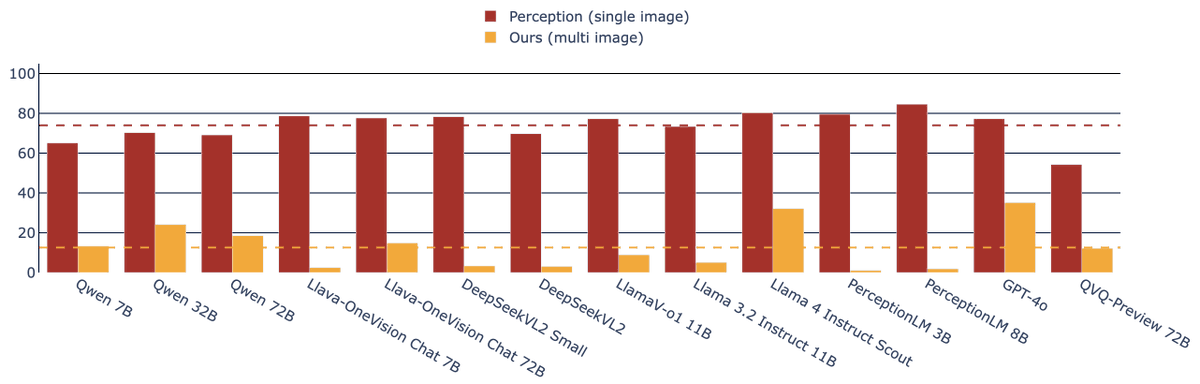
We introduce, Common-O, a new multimodal benchmark for hallucination when reasoning across scenes.
We find leading multimodal LLMs can reliably identify objects, yet hallucinate when reasoning across scenes.
🧵1/3
Despite saturating single image perception, Common-O establishes a new challenging multimodal benchmark. The best performing model only achieves 35% on Common-O and on Common-O Complex, consisting of more complex scenes, the best model achieves only 1%.
🧵2/3
Meta on meta: thrilled to share our work on Meta-learning… at Meta! 🔥🧠
We make two major contributions:
1️⃣ Unified framework revealing insights into various amortizations 🧠
2️⃣ Greedy belief-state updates to handle long context-lengths 🚀
If you’re an NYU student, come learn about this wonderful opportunity to collaborate with us at FAIR https://t.co/P4hHZZXXGq Panel is tomorrow 10am at NYU Center for Data Science.