Graduate Student at @Mila_Quebec and Student Researcher at @GoogleResearch. Previously interned at @Meta @Apple @MorganStanley @NVIDIAAI and @YorkUniversity
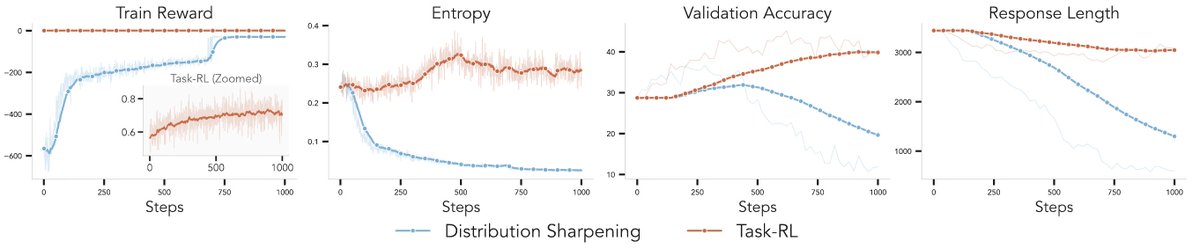
Is distribution sharpening actually the future of scaling, or just a massive hype train? 📉
We put it to the test using an RL framework – simulating everything from sharpening to task reward optimization.
Result: It’s not the silver bullet everyone thinks it is!
@yoavgo As it turns out, the KL regularized return maximization objective is exactly the ELBO from variational inference. One is forced to REINFORCE because you can’t use the reparameterization trick, but other than that it’s a VAE where action / reasoning tokens are the latents.
Our post-training pipeline is a substantial redesign from Super.
The core idea: don't rely on stacked RL stages alone. We do SFT, multi-environment RLVR across a huge mix of agentic/reasoning/code/safety environments, then Multi-teacher On-Policy Distillation (MOPD). 10+ domain-specialized teachers, merged into the student via dense token-level guidance on its own rollouts. See Figures below for overview and tech report for all the details. 2/4
🚨Excited to announce our workshop Context Beyond the Window hosted at COLM in SF! 🚨
LLMs have finite context windows, yet real-world tasks demand absorbing, retaining, and acting on information that far exceeds any single prompt.
1/3
We're looking for submissions across:
https://t.co/6y1ILeeC9A
• Context compression 🧃 — token compaction, recursive subagent calls, and external memory for storing and retrieving information
• Efficient architectures 🚀 — sub-quadratic attention variants that make extremely long context computationally feasible
• Continual training 🌱 — test-time training on streaming data, context distillation, and knowledge accumulation through continued pre-training
• Agentic memory systems 🐘 — scaffolds and test-time scaling techniques that improve knowledge retention and acquisition in LLMs
• Evaluation 🎯 — benchmarking models on increasingly long-horizon tasks
@RyanBoldi Is it fair to call this optimizing vector-valued rewards, since in reality the reward is being reduced to a single number which is the weighted mean with expected weights?
The scientific process involves collecting informative measurements while effectively allocating limited resources. We developed MaD-Physics, a new benchmark to measure this capability of agents.
Sharing our work on full-duplex multimodal models -- real-time interaction that's natural and intuitive without compromising on intelligence.
We started Thinky in part to differentially advance capabilities for human-AI collaboration, which are underemphasized relative to intelligence/autonomy because they're harder to eval.
In the future, we think every AI system will have something like an interaction model as the outer user-facing layer, continually keeping the user informed and learning what they actually want.
Today we announced a major milestone: @prior_labs has entered into a definitive agreement to be acquired by @SAP, scaling Prior Labs to become the next frontier AI lab for structured data. 🧵
Kind of weird that Gemma 4 2B model is actually 5B (including embeddings, guess that is why they say E2B)
And here I was thinking I found something comparative to Qwen3 1.7B
We used the Nemo RL codebase to implement the RL training.
Paper: https://t.co/HqDQNbVD3i
Joint work with Leo and Guillaume.
The setup is heavily inspired from https://t.co/8wAeDLvju1
Is distribution sharpening actually the future of scaling, or just a massive hype train? 📉
We put it to the test using an RL framework – simulating everything from sharpening to task reward optimization.
Result: It’s not the silver bullet everyone thinks it is!
Could this all have to do with RL-training instabilities and not distribution sharpening?
Our training health checks highlight consistently improving reward, showing that the training methodology works fine, but the optimum is to blame.