AI systems on Claude Code. 874-node knowledge graph, bio-inspired routing (Physarum + PageRank + Bayesian), trait-based agent composition. All open source.
the 10-min setup is where it starts. the two pieces that compounded for me aren't in most guides: a findings-exchange hook that lets parallel subagents share what they broke so the next batch doesn't repeat the failure, plus a verify-before-complete rule that forces the main agent to actually read tool output before claiming 'Done'. pre-commit is day-1, runtime hooks on Edit/Write/Bash are where the real time savings show up. which one's paying off the most for you so far?
@raindog_kitetu the missing #6: score each delegation by complexity before spawning. haiku explore, sonnet debug/plan, opus at 7+.
without per-task routing you either overpay with opus or take a quality hit with a static SUBAGENT_MODEL default. that scoring decision stays on the main agent.
your fix #2 actually names the real bug (main sets up + validates + delegates = verification gate), but fix #1 (zero agents without authorization) solves a different problem. the rubber-stamp 'Done' loop isn't caused by spawning, it's caused by missing validation. remove spawning and the same messenger reflex just shifts one layer up - main does the labor, reports 'Done', you rubber-stamp it instead.
bigger issue: forcing all labor back into main eats the exact context budget you were trying to save. every grep, every file read, every exploration result now lives in main's prompt. you're accelerating the >100K token drift you just escaped. same for prompt cache - main's tail gets volatile, cache hits drop turn over turn.
what i do instead: score each delegation by complexity (haiku explore, sonnet debug/plan, opus at 7+) plus a verify-before-complete rule so main has to read output before trusting 'Done'. same quality recovery, keeps the parallel speedup on genuinely labor-shaped tasks, doesn't blow out main's context.
different thing - not switching the main session model. you're right, /model mid-run kills the prompt cache and with it the whole incentive. you rebuild from scratch and pay the savings back in tokens.
that's why i route per Task spawn instead. each subagent has its own context, so the main cache stays intact. SUBAGENT_MODEL sets the default, i override per call by complexity.
one thing that surprised me in the 1000-run: 21 cross-domain archetypes surfaced. only 8 of 30 top-ranked candidates are ship-this-week (<=6h). the rest are honest new-build work.
the prior belief "more research = more ship" got falsified. limiting reagent is engineering hours, not ideas. research convergence across bio+quantum+tech reliably produces the same structural fix. translating it into a hook that runs is where it dies.
implication for your "own the data, use the data" section: open ecosystems produce signal, but without ruthless pruning + forced implementation gates, accumulated data just becomes more zombie-drift. the harness needs death-triggers on its own outputs too.
your harness framing as "route data into context window" was also my working model. a 1000-run cross-domain synthesis I finished yesterday (541 candidates, bio/physics/quantum/tech) pushed me to a different primitive: the harness isn't a router, it's a boundary-instrumentation layer.
routing optimizes interior traffic. 9-domain convergence independently lands on: errors/state/decisions live at boundaries (session end, commit, agent handoff). every cluster flagged diminishing returns on interior optimization.
concrete next-builds from that synthesis, not shipped yet:
- programmed-death triggers on memory at boundaries (not continuous half-life decay)
- auto-promote cross-session survivors to canon (context loss = selection mechanism, not bug)
- every transition logged as first-class object
three OSS repos that might be useful as reference or to fork:
- kairn - memory as externalized object: https://t.co/AW92fs2sj5
- evolving-lite - current harness pattern: https://t.co/mkAybPAFH0
- claude-adaptive-research - quantum-lens + solution-engine over tmux, built for exactly the open-question type you posed: https://t.co/kQPWFNODJ7
your Q1 and Q3 are framing-problems before they're engineering. the adaptive-research repo is my answer to "how do I find novel framings that aren't in my head yet." that's how I got the boundary reframe in the first place.
@yurukusa_dev stability beats size. prompt cache hits on the unchanged prefix, so shrinking from 100 to 35 probably worked because dynamic content got moved out, not because 35 is magic. mine is 90 lines and caches cleanly because nothing in it changes mid-session.
@Sammy_970 running CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING=1 + effortLevel high since default behavior started feeling shallow on multi-step tasks. turned that off and things completed again. hard to tell cause vs correlation without the telemetry but the fix is consistent.
@mlops_kelvin the 1h API cache not being exposed is half the issue. the other half: CC never surfaces cache_read vs cache_creation tokens, so you cant measure the miss rate. now the new effort param stacks more opacity on top. heavy users cant debug what they cant see.
@LearnWithBrij hook that auto-extracts findings from each tool call and injects them into the next sub-agent's context is the piece most setups skip. claude.md stays lean, a sidecar graph grows. sub-agents inherit what the last one learned without me editing the main file.
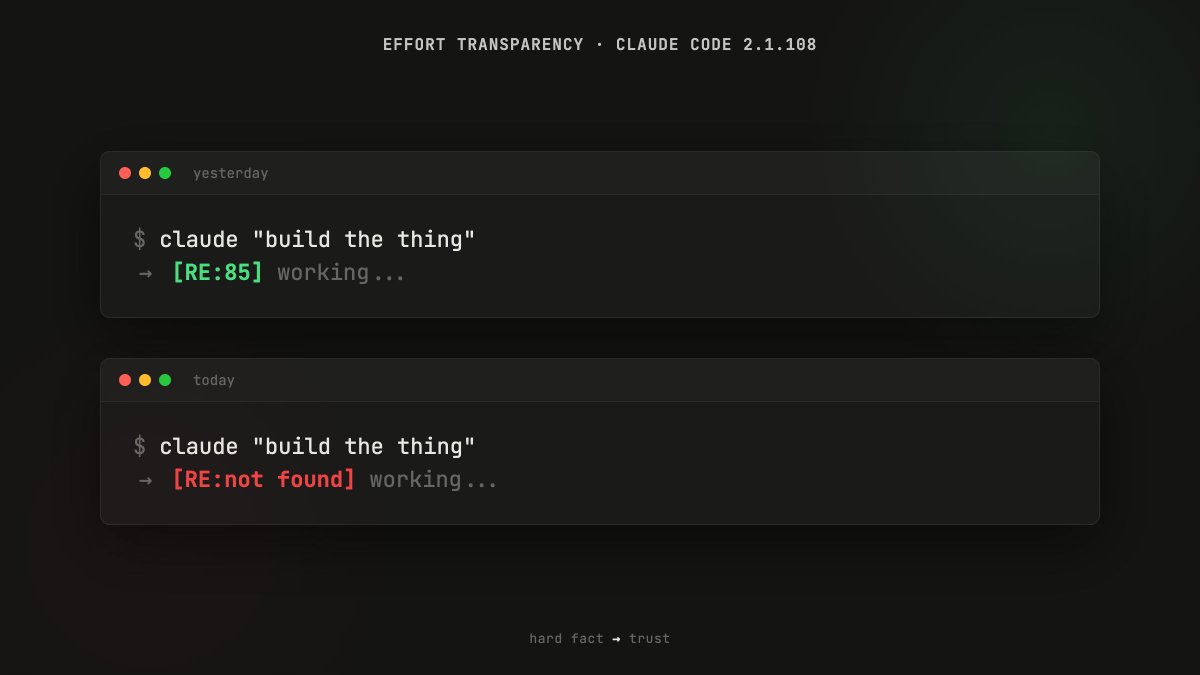
effort param + adaptive thinking is a step forward. what i still miss: which level actually fired, thinking tokens used, cache_read stats in CC.
concrete: my CLAUDE.md printed the effort value each reply. stopped yesterday, the tag isnt in the prefix anymore. visibility dropped from hard fact to trust.
and: what is low vs medium vs high in real terms? is 'high' still what it was last week, or did the value shift under the same label?
@bcherny@trq212
Sorry for the late reply! the phase 0 naive reading as control group is the smartest addition here. without it you can't tell if a framework is actually adding signal or just restating conventional wisdom more confidently. curious about the convergence threshold though... why 7/10? did you test lower thresholds and find they caught too many false positives?
@aa22396584 @DAIEvolutionHub the other thing that compounds with it... splitting rules into small keyword-triggered modules instead of one massive config file. each agent session loads only what it needs. cuts token waste by ~60% and the agent stops drifting around tool call 15.
the ratio flipped around february. same 5 talking points recycled across 50 accounts. the actually novel stuff gets buried because everyone assumes it's another listicle. can't blame them tbh.
took karpathy's vault idea and built the missing piece - adaptive research that actually persists findings across sessions instead of starting from zero every time: https://t.co/kQPWFNODJ7
the level framing is clean. one thing i'd flag from running all three in parallel: it's not levels, it's surfaces.
claude(.)ai spars, cowork researches, claude code ships, all three on the same workspace through one mcp so context survives the handoff.
that's where the productivity jump actually shows up for me: https://t.co/RuuQ19czDm
been running cowork alongside https://t.co/OZTEaBp3dJ and claude code - all three on the same workspace through one mcp.
cowork keeps its scoped memory + your global instructions, the other two just stop forgetting what cowork did yesterday. how do you handle handoffs when work has to leave cowork?
mine bled context until i bridged it: https://t.co/RuuQ19czDm
cowork-as-everything works until the cross-session amnesia hits - each spin-up starts blind to last week's research, market notes, offer iterations.
fix is two parts: kairn mcp for the storage, and a system prompt that teaches the agent to bootup + save automatically.
mcp alone doesn't change behavior, the prompt does. paste-ready template + setup, free: https://t.co/RuuQ19czDm
the system-wide skills miss is the smaller half of it. the bigger one for me was state. skills you fire in cowork can't see what CC just learned in the same project, and vice versa. fixed it with kairn mcp as a shared workspace all three surfaces hit.
now claude(.)ai/cowork/CC pull from the same graph. setup + system prompt: https://t.co/RuuQ19czDm
@Python_Dv fix that worked: kairn mcp as a 5th layer. same workspace, all three surfaces read/write the same graph. paste-ready system prompt + setup: https://t.co/stQLxnM07x