This sadly isn't going to work. The best response is for all AI researchers to stop using Anthropic models. The lack of public feedback alone would cause them to fall behind within months.
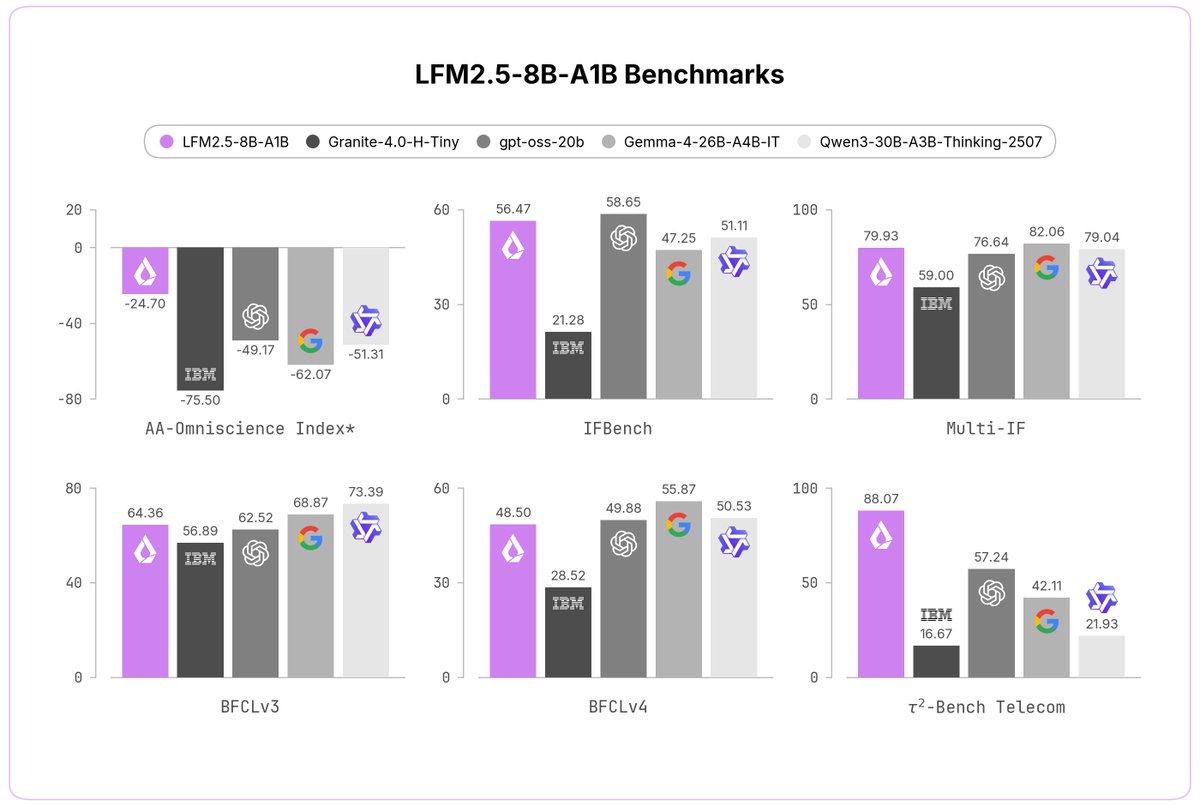
Today, we're releasing LFM2.5-8B-A1B, a device-optimized model designed to power real-life applications on phones, laptops, PCs, robots, and fast & lightweight server-side use-cases.
> 8B MoE, 1.5B active
> Expanded 128K context
> LFM2.5 flagship hybrid MoE architecture
> Trained on 38T tokens + large-scale RL
> fast, reliable tool calling, punching above its weight, comparable to models with up to 4x its size
> customizable on a single GPU for any specialized task
> LFM2 open-weight license
🧵
People hate their own countries so much that they don't want to go back and consider it a human rights scandal for the U.S. to send them home to renew your visas need to get some self-awareness. And gratitude.
People really need to stop hating on China man. Every time I’m in a pickle it’s China saving me.
Gas prices too high? I’m riding in the BYD. DRAM costs an arm and a leg? CXMT floods the market. Anthropic and OpenAI fucking me on token costs? Hello my friend Mr. Qwen.
The CCP has done more for my cost of living than my own government.
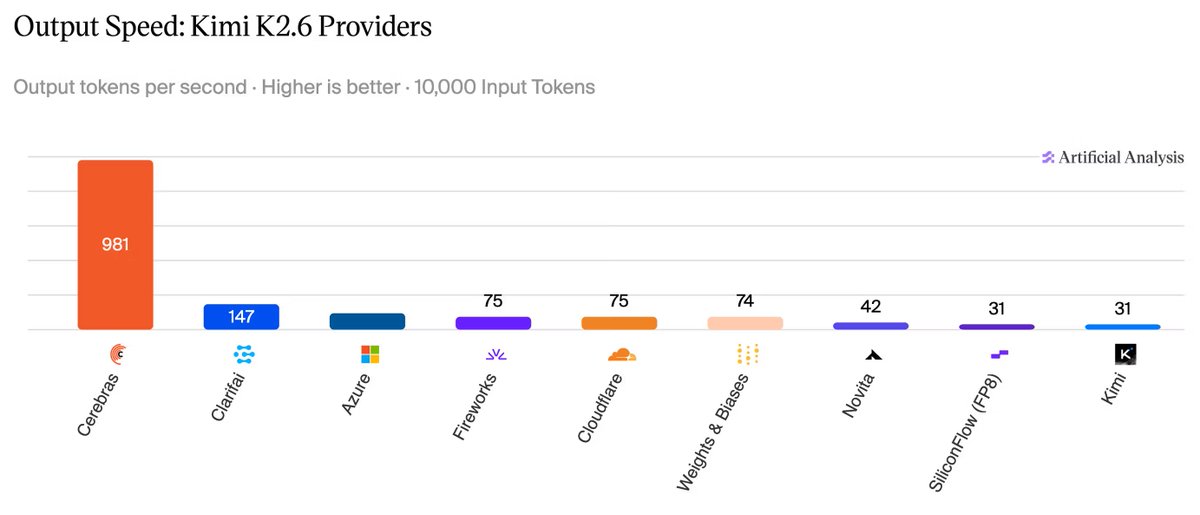
Cerebras is now running Kimi K2.6 – a trillion parameter model – in enterprise trials.
At ~1,000 tokens/s, this is the fastest frontier model performance ever measured by Artificial Analysis @ArtificialAnlys.
I’m pushing 30. Was at the beach and some 18 year old lied and said he was 21.
I told him I’m his mother. He wouldn’t go away. I told him I’m basically 30. He said age didn’t matter. He came up to me 3-4 times. And as courageous as he was, to me he was a child.
A young boy just starting out. One that was offering himself up to be taken advantage of.
Makes me think of all the 60+ year old men “dating” 20 year olds.
Makes me think of that 65 year old who was talking to 21 year old me.
How do these men do that? How do they look at a literal child and go “wow she’s mature” when i was looking at this 18 year old and thinking of how much younger he is than my younger brother.
“She’s a fully grown adult.” And you’re excusing yourself to feel less guilty.
Qwen 3.6 27B + Pi on a MacBook Pro, fully local: a beast.
27B dense model, flagship-level agentic coding, running entirely on hardware in your hands. Speed is impressive, Utility is extremely high. It punches orders of magnitude above its weight.
Local AI is getting real.
Time Dilation kind of makes the whole “datacenters in space” idea more fun.
Technically…something like a GPS Block III CPU runs an extra ~7,000 clock cycles per day compared to the same machine on earth.
Extend this to the extreme, and you get the whole subfield of CS+physics called relativistic hypercompuation.
There’s some (fun?) papers that allow you to solve the halting problem by placing yourself dangerously close to a black hole…while your computer safely computes for ~infinite-ish amounts of time.
One of the better papers on this field appears to be:
"Relativistic computers and the Turing barrier" (Németi & Dávid 2006)
(sadly, the maximum speedup just escaping earths gravity well is something like 1 x 10 ^ (-10), so yeah the blackhole thing is kinda necessary)
Modern DRAM is based on a brilliant design from IBM.
But, we're still paying for a latency penalty that's existed since the 60s!
In this video, I'm introducing my research project (Tailslayer) that immensely reduces p99.99 latency on traditional RAM!
By implementing a hedged read strategy taking advantage of (undocumented!) channel scrambling offsets, I've gotten as much as 15x reductions in tail latency.
The technique works across Intel, AMD, Graviton, DDR4, DDR5, x86, ARM, you name it.
Check out the C++ lib I wrote, watch the video, and try it yourself!