AI beyond the hype. Real insights, real breakthroughs, real methods. Philosophy, benchmarks, quantization, hacks—minus the marketing smoke. Injecting facts into
Microsoft has released MAI-Transcribe-1.5: an exceptionally fast speech transcription model at a speed factor of ~276x, while still achieving 2.4% on AA-WER (#3), leading the accuracy-speed Pareto frontier
MAI-Transcribe-1.5 is Microsoft AI (MAI)’s latest speech transcription model, coming in at 3rd overall on the on the Artificial Analysis Word Error Rate (AA-WER) leaderboard, behind Alibaba’s Fun-Realtime-ASR-preview (1.7% WER), and ElevenLabs Scribe v2 (2.2% WER). The model stands out as the fastest STT model in the top 10 for accuracy, processing audio at ~276x real-time - this is more than double the speed of the second fastest model in the top 10 for accuracy.
The new model supports keyword biasing (improved recognition of rarer vocabulary such as names and medical terminology), in addition to support for 43 languages including English, French, Arabic, Japanese, and Chinese.
See more details below ⬇️
Qwen3.6 35B A3B can't fill out a paper form on its own. But give it NVIDIA's LocateAnything-3B — the #1 trending model on HuggingFace — as its eyes, and the two small models get it done together.
(The test: place each element at the right pixel position on a blank form image, not type into a field.)
Setup:
> Qwen is the brain (main model), LocateAnything is the eyes (helper model acting as a tool).
> I gave Qwen a new tool: ask "where's the email field?" and LocateAnything returns the exact x, y, width, height.
> The blue boxes on the screen are its detections. Look how tight they are — it nails every field.
Result:
> Qwen3.6 35B A3B + LocateAnything-3B: form completed, all info correct.
> Name, DOB, ID, gender, marital status, nationality, email, phone, address, postal code: all landed in the right field areas.
> Character-box alignment still a touch loose, but every value is where it belongs.
> 9m10s, 224.5k input, 24.3k output, 21 turns.
Why it matters:
> Qwen alone can't finish this test. Bolt on a 3B model that does exactly one thing > locate > and suddenly it can.
> A combination of small models can do the work of a single large one.
LLMs learn by predicting tokens. World models (JEPA, data2vec) learn by predicting their own abstractions. Which needs more data? For data with hidden hierarchy, we prove the gap is exponential. https://t.co/r2uuX0lBCu
We’re back to No. 1 on the leaderboard! 🎉 After months of hard work, what a journey! It’s also the best option for fast and low-cost generation.
Meanwhile, we’re cranking day and night on v2 to make it even stronger. Try it and let us know what we can improve — your feedback is invaluable.
→ https://t.co/3qIdWlpjWq
This is the NVIDIA RTX Spark Superchip. A new beginning for personal computers.
Designed for creators, AI developers, and gamers, RTX Spark brings over 30 years of NVIDIA innovation to slim Windows laptops and small, ultra-efficient desktop PCs.
Agents can do whatever humans can do on the web.
Browser Harness can for example :
> Configure a car.
> Store the images.
Tell me your task, so I can demo it.
Or try it urself ⬇️🔗
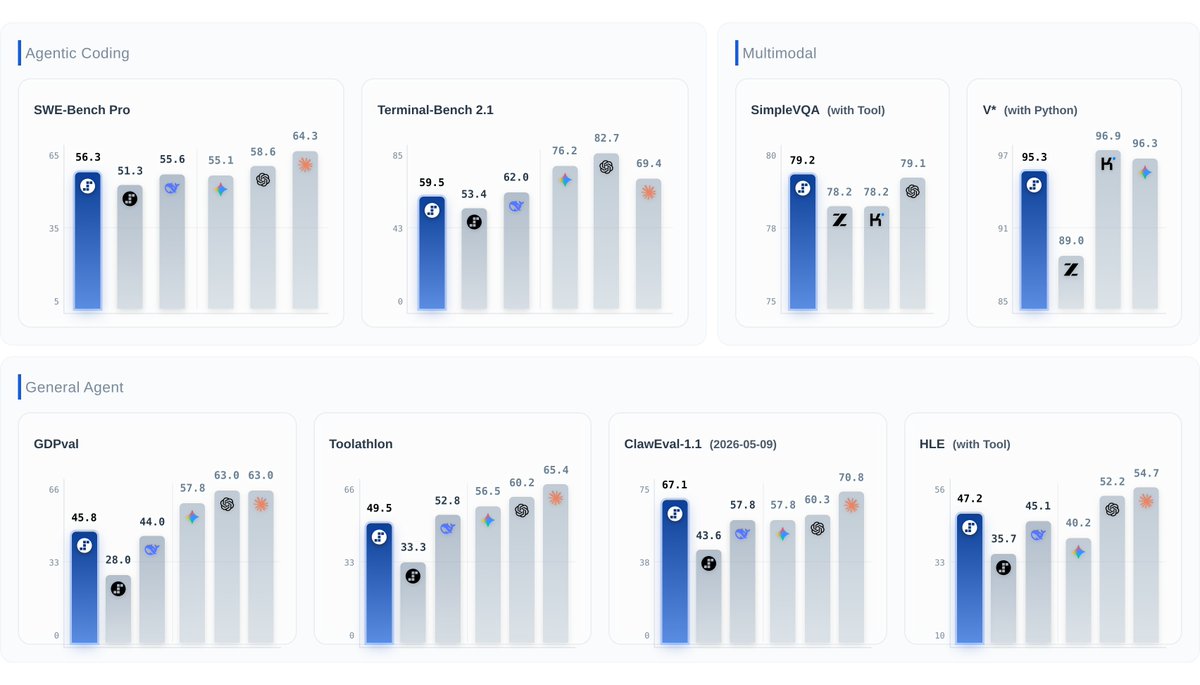
⚡️ Step 3.7 Flash is here: The new frontier is agent efficiency.
#1 ClawEval-1.1 (67.1), #1 SimpleVQA Search (79.2), #2 SWE-PRO (56.3), 95.3 on V* Python. Open weights under Apache 2.0.
Built for agentic, coding, search, and multimodal workflows — balancing speed, cost, and reliable execution.
- 400 TPS. 198B sparse MoE, ~11B active. 256K context, 3 reasoning levels.
- Understands UIs, charts, docs, images — then writes code or calls tools to act on what it sees.
- Web + visual search reaches further: more sources, deeper follow-up.
- Reliable tool use — less drift, fewer broken toolcalls. 98%+ on τ²-bench across all difficulty levels.
- Works with Claude Code, KiloCode, Hermes Agent, OpenClaw, and protocols like MCP.
- Runs locally on Mac Studio M4 Max, DGX Spark, AMD AI Max+ 395.
GitHub: https://t.co/kqlZkVIRHv
HuggingFace: https://t.co/qqceCrgPiw
GGUF: https://t.co/rR6XrnymWG
ModelScope: https://t.co/wney6Tzvqy
API: https://t.co/RvHWzRG7Fu
Blog: https://t.co/BxDiajiQ5G
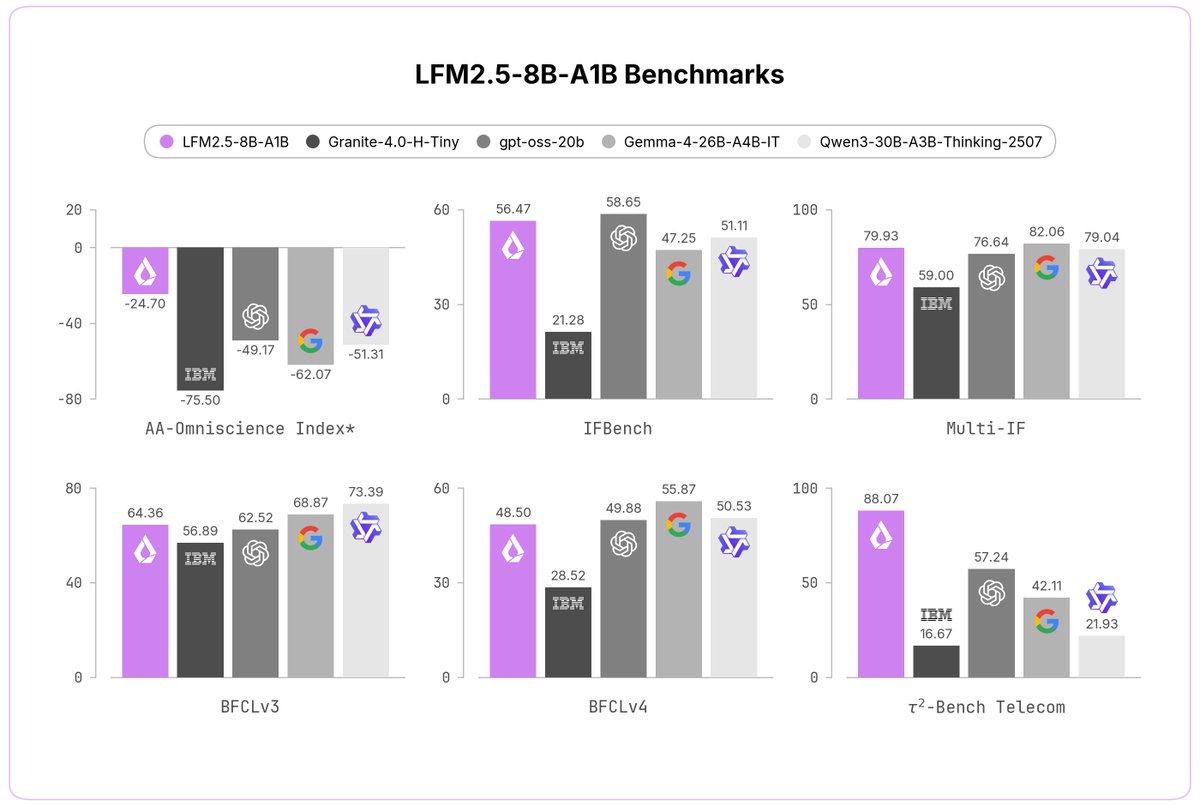
Today, we're releasing LFM2.5-8B-A1B, a device-optimized model designed to power real-life applications on phones, laptops, PCs, robots, and fast & lightweight server-side use-cases.
> 8B MoE, 1.5B active
> Expanded 128K context
> LFM2.5 flagship hybrid MoE architecture
> Trained on 38T tokens + large-scale RL
> fast, reliable tool calling, punching above its weight, comparable to models with up to 4x its size
> customizable on a single GPU for any specialized task
> LFM2 open-weight license
🧵
China is restricting overseas travel for top AI professionals in private firms such as Alibaba and DeepSeek, suggesting an escalation in measures intended to safeguard its technology and catch up to the US in a pivotal sphere.
Government agencies have begun imposing restrictions on individuals involved in advanced AI work and considered strategically important to the country, people familiar with the matter said. https://t.co/WM5Y9gkue9
📷: Qilai Shen/Bloomberg
Converted Qwen 3.6 35b a3b to ROCmfp4 and this is flying. Used the mtp version bc this ROCmfp4 can also incorporate the merged benefits of MTP. 262k. Reasoning On. @FrameworkPuter AMD 💪 🔥
Woot! You can now simulate real world places by grounding Genie 3 experiences with Street View imagery.
Google sitting on the mother lode of real world data, and is starting to put it to work!
Let's dive into some prompts & locations I tested...
Introducing: Cohere Command A+
We’ve created our most powerful LLM yet, optimized it to run on as little hardware as possible, and released it open-source for all.