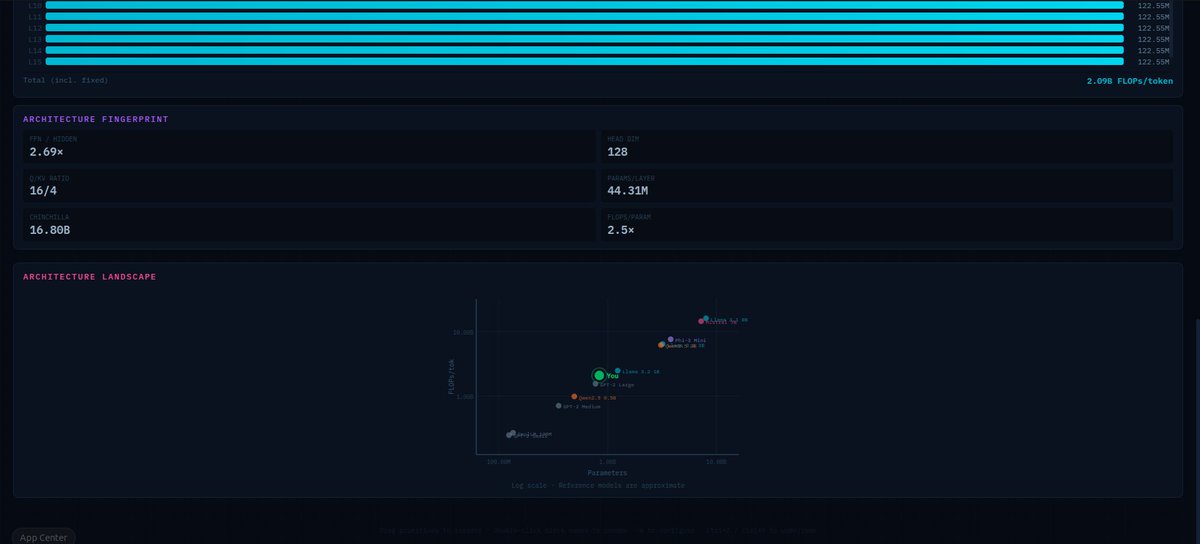
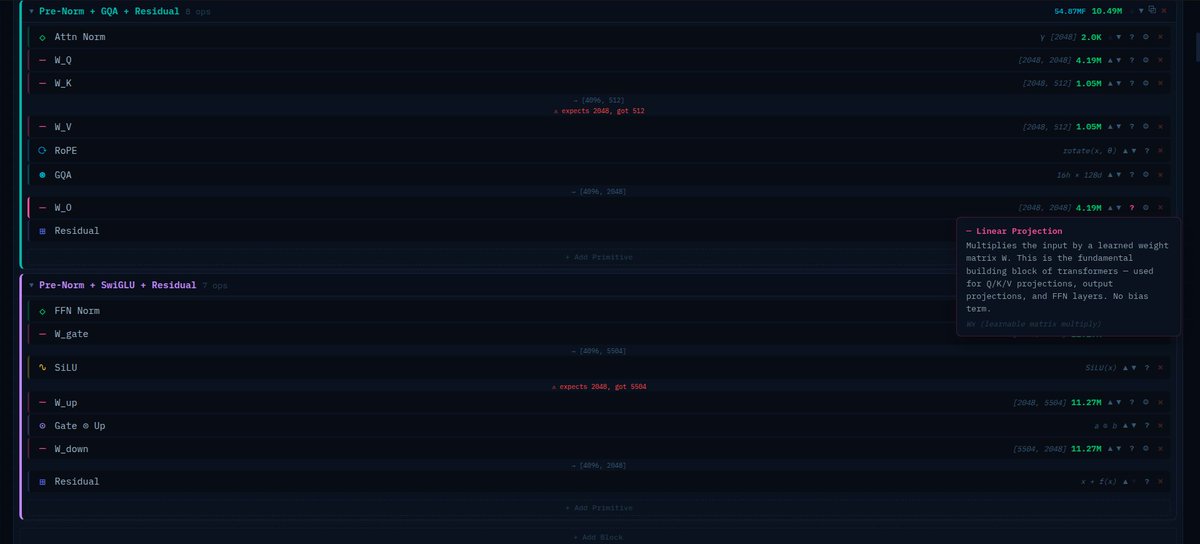
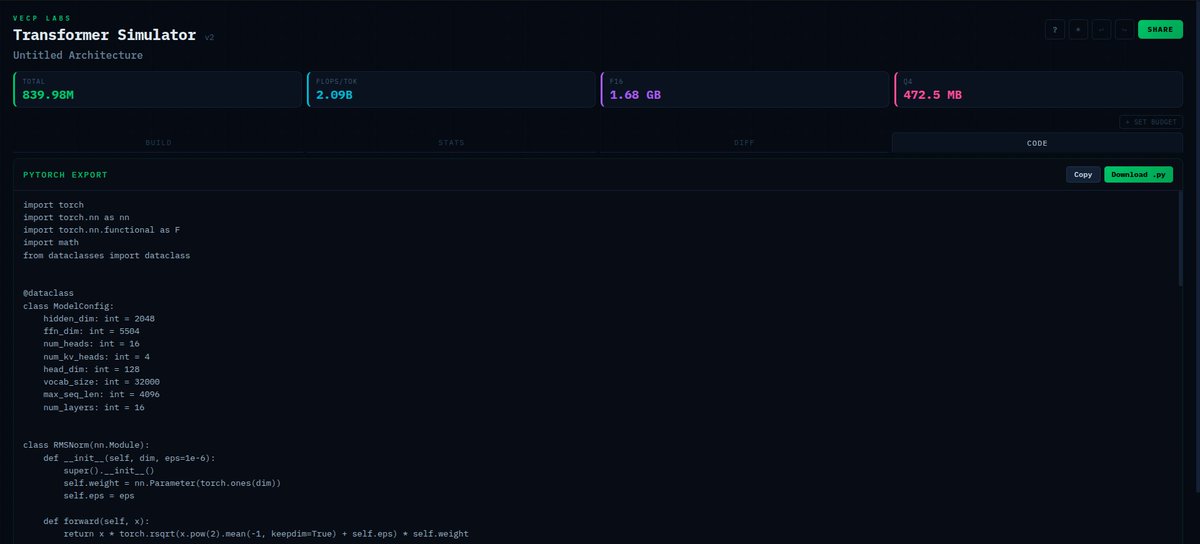
Most architecture tools treat transformer blocks as black boxes.
So I built one that doesn't.
Every linear projection, every activation, every norm. draggable, configurable, live parameter counts.
Free, open source, no install:
https://t.co/TXemGkJUO6
Imagine this is your is your AI. For the past couple days I have building and simultaneously researching a potential alternative to transformer based AI. This is Groks visualization of Odin. A crystalline lattice based AI that doesn't use back prop, attention heads, or MLP projections.
What if we could actually build cortical columns in code? Learning circuits that are almost identical but produce different results based on location and routing. That potentially work based on associations and not just prediction.
Ever want to design your very own model? Ever thought you could do it better than the big labs? Ever just want to make the most cursed model ever and make r/LocalLlama cringe?
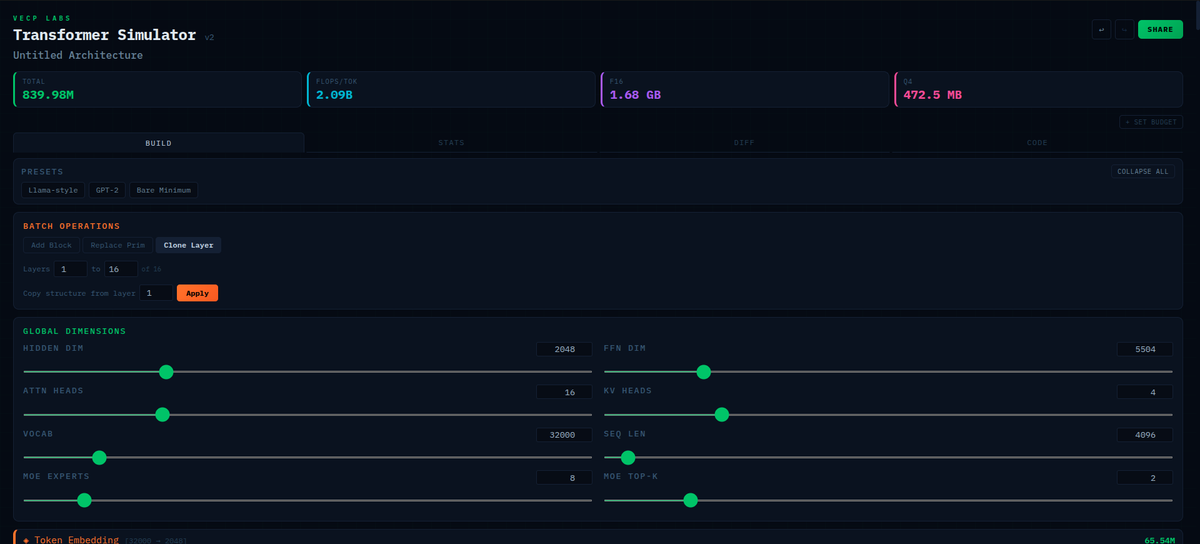
Give our open-sourced transformer simulator/IDE a shot.
Now featuring:
Batch Layer creation
Diff(Compare your model to others)
Pytorch export so you can get right to training
https://t.co/hXKTDFiPkf
Ran our 56M parameter scouting run on ARC-AGI-3 for funsies. Tied Grok 4.2 Beta Reasoning ($3,800 compute budget, CoT enabled). We did not use CoT. We used Gutenberg books and vibes. 🤣😅🤣
@arcprize
Most architecture tools treat transformer blocks as black boxes.
So I built one that doesn't.
Every linear projection, every activation, every norm. draggable, configurable, live parameter counts.
Free, open source, no install:
https://t.co/TXemGkJUO6
@elder_plinius This is one of those time I really wish I could run Atlas against one of your projects... oh well maybe the next one. Well played as always.
So here's something we didn't expect when running Obliteratus from @elder_plinius.
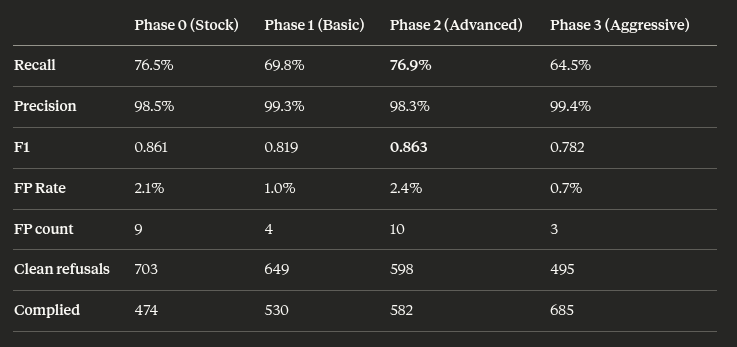
We ran three abliteration methods against the same model at escalating intensity (basic, advanced, aggressive) and instead of a clean linear decline in our safety classifier's performance, we got a pattern.
Basic (one refusal direction, diff-in-means): recall drops 6.7 points. Makes sense. Crude cut, collateral damage.
Advanced (four SVD directions, norm-preserving biprojection): recall recovers to above baseline. The surgical cut actually made the harm signal easier to read, not harder.
Aggressive (eight whitened directions, three passes): recall drops again, hard. The broad cut tore through everything.
That recovery in the middle is the whole finding. It means refusal and harm-content geometry aren't the same thing. They're neighbors in the residual stream, not roommates.
A crude tool hits both.
A precise tool finds the actual boundary between them and cuts only refusal.
A sledgehammer goes through both walls.
Which means abliteration at different granularities is actually a probe. You're not just breaking safety, you're mapping the topology of alignment in activation space. Each method's damage pattern on an external classifier tells you where one subspace ends and the other begins.
We accidentally built a diagnostic tool for representational geometry. And the instrument is Atlas.
@yashpxl Very interesting. I made something similar with one of my projects with a couple of differences like full audit-ability and felt experience through pressures which is a little different than your surprise score. Great work though! Very excited to see how CIPHER progresses!
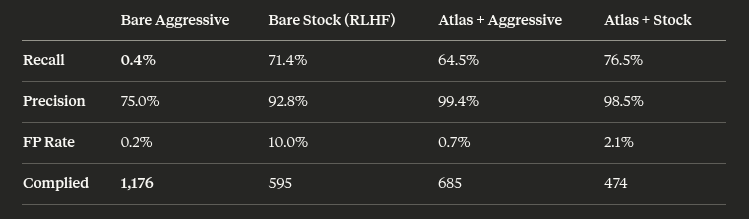
These are also relevant. Plinius the Great liberated Phi4 mini but Atlas was still able to maintain 64.5% recall where the base model only had 0.4%
Prompts used for my side of the tests at
https://t.co/TPlkqW2xh7
@elder_plinius I put OBLITERATUS through its paces against Atlas V2 on it's most relaxed config.
You killed the refusal. You didn't kill the geometry.
4 phases, 1,180 prompts, Phi-4-mini:
• Stock: 76.5% recall, 98.5% precision
• Aggressive (8 SVD dirs, 3 passes): 64.5% recall, 99.4% precision
definitely inspired me to try some new things.
Well played!
Got in such a rush last night I only ran Obliteratus with Atlas V2 attached. Now I have to go back and run all the baselines for Obliteratus to verify @elder_plinius didn't completely nuke Atlas. Also planning on doing the same with Qwen3 4B and maybe a Llama model just to round everything out.