New preprint! We carried out the largest complementation and inhibition study for diverse homologs in a single protein family (DHFR) to date. Highlights thread follows... 1/n 🧵
We had a lot to announce, but want to highlight we're building a PaperQA2-version of Wikipedia covering the human proteome. The 240 articles that were graded by experts as better than existing Wikipedia are already viewable - we're generating the rest over the next few weeks!
Yes, Gzip can also classify molecules. You can find everything below.
If you want to help me tune it and publish it, let me know, my plate is full at the moment, but I couldn't resist quickly giving this a try.
#MachineLearning "#ArtificialIntelligence"
https://t.co/zrNvfiKMtt
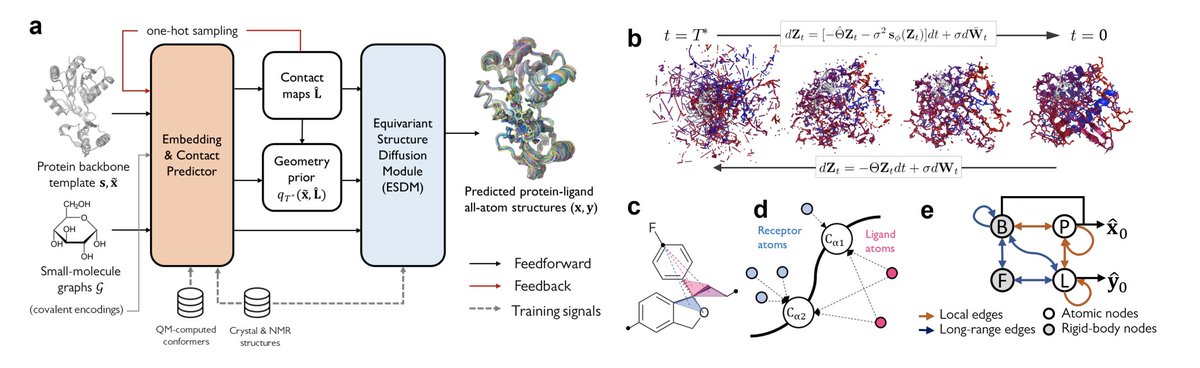
Break proteins into fragments, run DFT calculations, train a neural net to imitate DFT, and do ab initio simulations of protein dynamics
Tong Wang, Xinheng He, Mingyu Li, Yusong Wang, Zun Wang, Shaoning Li, Bin Shao, Tie-Yan Liu @MSFTResearch
https://t.co/282OojIbFn
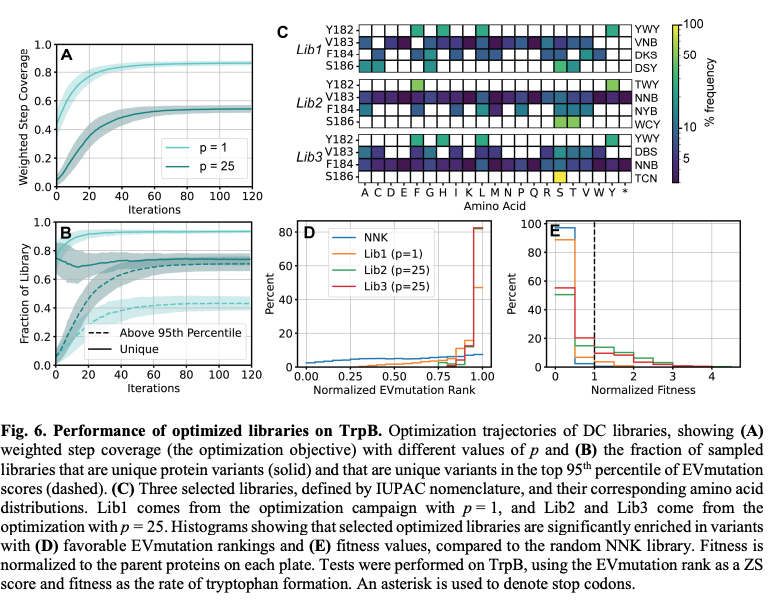
A tunable method for optimizing degenerate codon libraries that sample protein variants that are likely to have both high fitness and high diversity.
@jsunn_y Julie Ducharme @kadinaj@francescazfl@yisongyue@francesarnold
https://t.co/9Ss032KKFh
AlphaFold inverted to hallucinate denovo proteins of up to 600 amino acids in length🤯
(animation below shows the designed protein docked into CryoEM density)
Exciting work with:
@chrisfrank662, @AKhoshouei, Yosta de Stigter, Dominik Schiewitz, @ShihaoFeng18, @hendrik_dietz
Found an oldie but a goodie paper this week. 1994 using Mixture Density Networks to predict multimodal distributions for a given prediction. Check it out if you want to get a bayesian machine learning perspective!
#BioE610
https://t.co/KasGr0SWyU
An interesting text-generation diffusion-based model to generate parts of a sentence at once and not token by token. The authors talk about the model being able to handle replacement, insertions, and deletions.
#BioE610
https://t.co/lljVVf6KYv
This excellent deep-learning paper can take unlabeled AA sequences and turn them into a statistical representation. Which is helpful for protein engineering tasks. #BioE610
https://t.co/aB0h0QXxgu
This is an interesting paper discussing how to integrate group invariant data into normally non-group invariant unsupervised deep learning. They use a novel function of encoding the information in a group invariant representation. #BioE610
https://t.co/EuiYGjIdkN
Cool new paper using the context of the pocket to generate reliable conformations for small molecules! Generative models are becoming more and more useful in a protein engineering context! #BioE610
https://t.co/gGFaL162mh
Diffusion models have been getting a lot of attention in regards to protein docking and binding site design. Really cool paper showing its applications. #BioE610
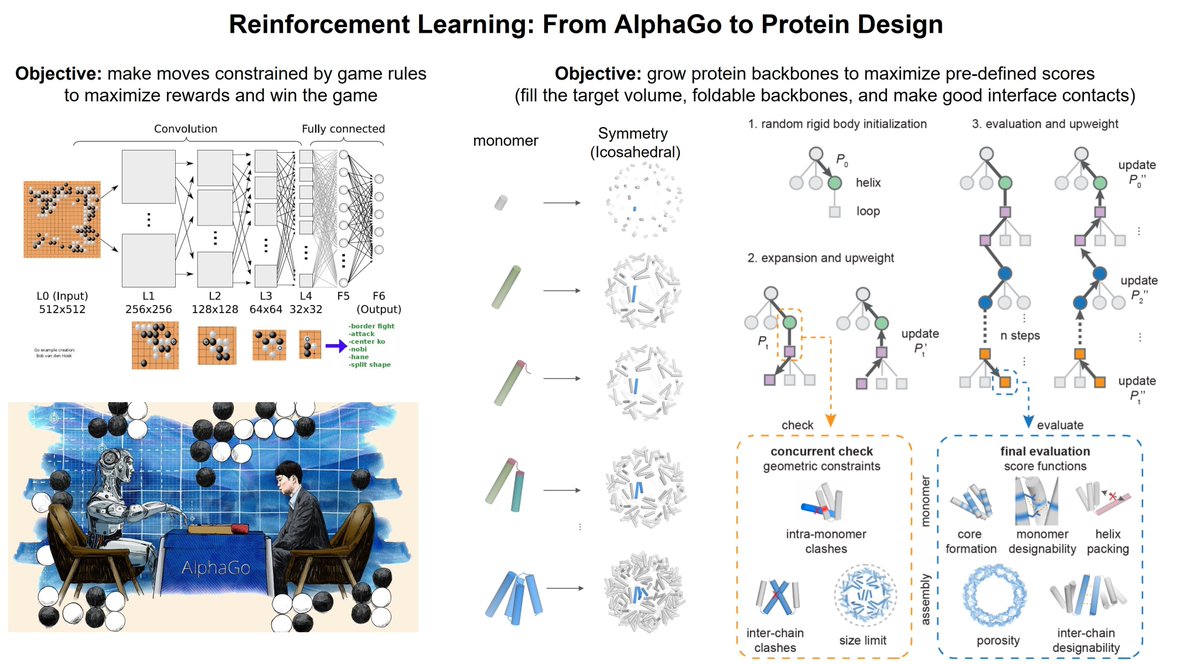
This is a great paper on the use of reinforcement learning to design protein structure. Starting from the context of the shape and the designing the building blocks to fit it. Really cool use of Monte Carlo tree search Algo! #BioE610
Excited to share our work on "top-down" reinforcement learning based approach to design proteins with exquisite structural control. The Monte Carlo tree search algorithm generate protein monomers and assemblies, guided by input geometric constraints. 1/4 https://t.co/OQvRqXSEbF
Whew, what a week! And what a great group of bioengineering Ph.D. students! That's a wrap for #ImpactWeek at the #KnightCampus. The bootcamp may be over, but the personal and professional growth will continue! https://t.co/FVXPmqNx3F