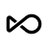Arthur Mensch confirmed on CNBC this week that OpenAI and Anthropic are calling Mistral asking for compute. The two companies racing to build the most powerful AI in the world are dependent on a European competitor they have been trying to outrun.
Let that land for a second.
The narrative you have been sold is that the US is running away with AI. That OpenAI and Anthropic have such a commanding lead that the rest of the world is playing catch-up.
That narrative is missing something physical.
The International Energy Agency projected this year that US data center electricity demand will double by 2030. The US grid is already at capacity. Europe has the power. Europe has the land. And right now the company fielding calls from the most funded AI labs on earth is a four-year-old French startup.
Mensch said Mistral is prioritizing its own customers first. The surge in agentic usage is generating far more tokens than anyone planned for and existing capacity is spoken for. The US labs are in the queue.
But they are in the queue.
Most people following AI are watching benchmark scores and funding rounds.
The actual constraint right now is electricity and physical space. And on that dimension, the scoreboard looks nothing like the one most people are reading.
Watch the full podcast on YouTube at @CNBCi
This is a super exciting release - Claude Fable 5 is the same underlying model as Mythos but with added safeguards. The benchmarks are great and it's SOTA on everything by a margin but I'll add that *qualitatively* also, this is a major-version-bump-deserving step change forward (imo of the same order as Claude 4.5 was in November), peaking especially for long problem-solving sessions on very difficult problems. You can give it a lot more ambitious tasks than what you're used to, the model "gets it" and it will just go, and it's never felt this tempting to stop looking at the code at all (but don't do this in prod!). The model still has quirks that people will run into and the safeguards are configured to be a little too trigger happy for launch, which can hopefully be tuned over time.
I feel a lot of things changing as working software increasingly comes out on a tap. The Jevon's paradox kicks in and I feel my own demand for software growing substantially. You can ask for anything - explainers, visualizers, dashboards, bespoke single-use apps (e.g. a full wandb that is hyper-specific just for your project), you can 10X your test suite, auto-optimize code, run giant research projects with custom HTML for the results, anything! "Free your mind" (Matrix ref). Really looking forward to all the things people build!
Everyone told us the AI race was over. That Europe🇪🇺 missed it. That you need $10B clusters and closed-source moats to compete.
Then @LightOnIO's LightOnOCR-2 -1B parameters, open-source, running on a single GPU you can put on your desk- just beat OpenAI GPT-5 mini, Anthropic Claude Sonnet, Google Gemini 2.5 Flash, Zhipu GLM-4.5V, and DeepSeek-OCR on table extraction. The work that actually matters.
Not Silicon Valley 🇺🇸
Not Shenzhen🇨🇳 Not Beijing 🇨🇳 Not Hangzhou 🇨🇳
From Paris🇫🇷 ...with love 💕
The race isn't over. It never was.
🔊Introducing Voxtral TTS: our new frontier open-weight model for natural, expressive, and ultra-fast text-to-speech
🎭Realistic, emotionally expressive speech.
🌍Supports 9 languages and accurately captures diverse dialects.
⚡Very low latency for time-to-first-audio.
🔄Easily adaptable to new voices
Google vient de publier un papier qui compresse les LLMs à 3 bits. 8x plus rapide, 6x moins de mémoire. Zéro perte de performance 🤯🤯🤯
Le truc c'est que la méthode est élégante au point d'en être presque triviale une fois qu'on la comprend.
Ça s'appelle TurboQuant. Je vous vulgarise tout le paper :
Déjà, le problème de base.
Quand un LLM génère du texte, il doit se "souvenir" de tout ce qu'il a lu et écrit avant. Ce système de mémoire s'appelle le KV cache (key-value cache).
Imaginez un étudiant qui prend des notes ultra détaillées pendant un cours. Plus le cours est long, plus ses notes prennent de place sur son bureau. À un moment il n'a plus de place pour écrire.
C'est exactement ce qui se passe avec les LLMs : plus le contexte est long, plus le KV cache explose en mémoire. C'est un des plus gros bottlenecks de l'inférence aujourd'hui.
La solution classique c'est la quantization. L'idée est simple : au lieu de stocker chaque nombre avec une précision extrême (32 bits, genre 3.14159265...), tu le stockes avec moins de précision (4 bits, genre "~3").
C'est comme passer d'une photo RAW de 50 MB à un JPEG de 2 MB. Tu perds un peu de détail mais visuellement c'est quasi pareil.
Le problème c'est que les méthodes classiques de quantization trichent un peu. Pour chaque petit bloc de données compressé, elles doivent stocker des "constantes de calibration" en pleine précision.
C'est comme si pour chaque photo JPEG vous deviez garder un petit post-it en haute résolution à côté qui dit "voilà comment décoder cette image".
Ces post-its rajoutent 1 à 2 bits par nombre. Quand tu essaies de compresser à 2 ou 3 bits, cet overhead représente une part énorme de ta mémoire totale. Ça annule une bonne partie du gain.
TurboQuant résout ça en deux étapes.
Étape 1 : PolarQuant.
Au lieu de décrire un vecteur avec des coordonnées classiques (X, Y, Z), tu le convertis en coordonnées polaires : une distance + un angle.
C'est comme remplacer "va 3 rues à l'est puis 4 rues au nord" par "va 5 rues direction 37 degrés". Même info, format plus compact.
L'astuce c'est qu'avant de faire ça, tu appliques une rotation aléatoire sur tes vecteurs. Ça rend leur distribution prévisible et uniforme. Du coup tu n'as plus besoin de stocker les fameuses constantes de calibration, la géométrie fait le travail toute seule.
Étape 2 : QJL (Quantized Johnson-Lindenstrauss).
Après PolarQuant il reste une petite erreur résiduelle. QJL la corrige avec 1 seul bit par nombre.
Le principe vient d'un théorème mathématique qui dit qu'on peut projeter des données de haute dimension dans un espace plus petit tout en préservant les distances entre les points.
QJL pousse ça à l'extrême : il réduit chaque valeur projetée à juste son signe (+1 ou -1). Un seul bit. Et grâce à un estimateur spécial qui combine la query en haute précision avec ces données ultra compressées, le modèle calcule toujours des scores d'attention précis.
Les résultats sont assez dingues.
Sur les benchmarks long-context (LongBench, Needle in a Haystack, RULER...) avec Gemma et Mistral : zéro perte de performance à 3 bits. Le KV cache est réduit d'un facteur 6x. Et sur H100, le calcul des scores d'attention est jusqu'à 8x plus rapide qu'en 32 bits.
Le tout sans aucun fine-tuning ou entraînement supplémentaire. Tu branches, ça marche.
Et le plus intéressant : ça ne sert pas qu'aux LLMs.
TurboQuant surpasse aussi les méthodes state of the art en vector search, c'est à dire la techno qui permet de chercher par similarité dans des bases de milliards de vecteurs (ce qui fait tourner Google Search, les systèmes de recommandation, le RAG...).
Mon take : l'inférence c'est là où se joue la vraie bataille économique de l'AI.
Les marges de toute l'industrie dépendent du coût par token en production. Un gain de 6 à 8x sur la mémoire et la vitesse d'inférence, sans aucune perte de qualité, ça change fondamentalement l'équation.
Ce type de recherche ne fait pas de bruit sur Twitter mais son impact business est potentiellement supérieur à celui d'un nouveau foundation model.
OVHcloud annonce acquérir Dragon LLM, concepteur de modèles spécialisés d’IA générative et crée son lab AI pour proposer de nouveaux services à ses clients basés sur les LLM.
https://t.co/AUdj6rJ3Hu
Recordly : alternative open-source à Screen Studio pour faire des screencasts avec auto-zoom, flou de mouvement sur le curseur et édition par blocs. Dispo MacOS/Windows/Linux.
https://t.co/sRGNpKLIvm
Today, we’re launching a new way to create with AI.
With OpenArt Worlds, you can generate a fully navigable 3D environment from a single prompt or image, step inside it, and capture shots exactly the way you envision them.
No more starting over.
No more inconsistent scenes.
You build the world once - and create inside it.
• Move through your scene freely
• Find your angles
• Add characters and elements
• Capture production-ready shots
🔥 Meet Mistral Small 4: One model to do it all.
⚡ 128 experts, 119B total parameters, 256k context window
⚡ Configurable Reasoning
⚡ Apache 2.0
⚡ 40% faster, 3x more throughput
Our first model to unify the capabilities of our flagship models into a single, versatile model.
Cowork is now available on Windows.
We’re bringing full feature parity with MacOS: file access, multi-step task execution, plugins, and MCP connectors.
LeCun: en l'absence d'obstacles imprévus on peut s'attendre à des IA du niveau de l'intelligence humaine dans 5 à 10 ans. "Est-ce qu'on aura des machines aussi douées que nous dans tous domaines? Oui absolument, aucun doute"
Voilà pour les sceptiques qui l'invoquent en permanence
Les grands modèles de langage (LLM, l’architecture qui sous-tend ChatGPT), ne seraient, dit-on, que des simulacres d’intelligence, de simples « perroquets stochastiques » se contentant de régurgiter des fragments recombinés de leurs données d’entraînement. Deux essais passionnants déconstruisent cette critique : Ultraintelligence d’Aymeric Roucher et La Parole aux Machines de Thibault Giraud (alias Monsieur Phi), professeur de philosophie.
L’argument du perroquet stochastique est d’abord contredit empiriquement par les progrès spectaculaires des dix-huit derniers mois. Confrontés à des problèmes de raisonnement jamais rencontrés dans leur corpus d’entraînement, les LLM obtiennent désormais d’excellents résultats, démontrant leur capacité à mobiliser des outils logiques pour faire face à un problème nouveau, ce qui correspond à une forme d’intelligence fluide. Comment expliquer cette capacité de généralisation ? [...]
Lors de leur entraînement, les modèles de langage ingèrent des volumes de données textuelles colossaux, très supérieurs à ce qu’ils peuvent stocker. Ils sont donc contraints de compresser cette donnée – tout en optimisant leur capacité de restitution cette même donnée. Or la meilleure façon de restituer fidèlement une donnée sans la mémoriser terme à terme consiste à en comprendre la logique génératrice. Que fait un bon élève qui révise le baccalauréat de mathématiques ? Il n’apprend pas toutes les annales par cœur, il cherche plutôt à comprendre la logique sous-jacente à la résolution de chaque problème pour pouvoir, le jour J, répondre à problème inédit. Aymeric Roucher évoque un commentaire de Saint-Exupéry sur Newton, qui, en découvrant la gravitation, a comprimé la complexité du monde en une règle : « La vérité, c’est le langage qui découvre l’universel. Newton a fondé un langage qui put exprimer à la fois la chute d’une pomme dans un pré et l’ascension du soleil. La vérité, c’est ce qui simplifie. »
Il est à ce titre intéressant de s’intéresser au comportement d’un modèle entraîné à effectuer des additions modulaires. Tant que le volume de données d’entraînement restait faible, le modèle mémorisait les exemples d’entraînement et restait incapable de généraliser. Mais dès lors que le nombre d’exemples a excédé sa capacité de stockage, il a été contraint de compresser l’information. Pour cela, il a internalisé une représentation équivalente à une fonction trigonométrique, transformant l’addition modulaire en opération de rotation sur un cercle. Bien qu’il n’ait jamais rencontré de trigonométrie dans ses données d’entraînement, le modèle avait reconstruit la structure géométrique régissant le comportement de l’addition modulaire. Il devenait alors capable de réaliser des additions modulaires sur des cas jamais rencontrés durant l’entraînement.
On se doute que cet exemple illustre ce que font les LLM dans d’autres domaines. À partir de leur vaste corpus d'entraînement, ils se construisent des représentations abstraites des règles implicites qui structurent notre monde - règles qui ont donné naissance à ces données d'entrainement. En schématisant, si le modèle est entraîné sur des raisonnements mathématiques, il en extrait nos règles de logique (et devient capable de s’attaquer à des problèmes nouveaux, voire jamais résolus) ; s’il est entraîné sur des scénarios de long-métrages, il en déduit les grands principes dramatiques (et devient capable de produire des œuvres nouvelles), etc. On observe d’ailleurs qu’entraîner un modèle sur du code informatique améliore ses capacités à raisonner en langage naturel. En apprenant à programmer, le modèle découvre une structure logique commune au langage et au code, qu’il peut ensuite exploiter transversalement.
Les heuristiques que le modèle accumule au cours de son entraînement constituent souvent la matière de notre propre raisonnement. Face à un problème nouveau, nous mobilisons un faisceau d’heuristiques que nous combinons pour atteindre la vérité. C’est pourquoi, à terme, lorsque les modèles seront entraînés sur des volumes de données suffisamment riches et variés (pouvant ainsi internaliser un immense répertoire d’heuristiques, enrichissant leur représentation interne de notre monde), rien ne s’oppose, en principe, à ce qu’ils égalent ou surpassent l’intelligence humaine dans tous les domaines (on parle d'Intelligence Générale Artificielle). L’AGI relèverait alors non d’un changement de paradigme mais d’une montée en échelle des modèles actuels : davantage de données, davantage de puissance de calcul.
Certains objectent qu’il est abusif de parler « d’intelligence » et de « raisonnement » pour des systèmes qui fonctionnent en prédisant le mot (et même le sous-mot) le plus probable au regard du contexte qui précède. Roucher et Giraud tordent le cou à cette idée. Prédire correctement le coup suivant d’un bon joueur d’échec implique de « comprendre » les échecs, souligne Giraud ; anticiper la résolution d’un roman policier exige d'avoir saisi la psychologie des personnages et les mécaniques de l'intrigue, note Roucher. Celui-ci rappelle d’ailleurs que dès 2017, des chercheurs d’Open AI ont découvert que la meilleure façon de créer un modèle performant en « analyse de sentiment » (capable de déterminer si un avis en ligne exprime une opinion positive ou négative) était d’entraîner le modèle à prédire le mot suivant dans des avis tronqués. La raison ? Pour réussir cette tâche, le modèle devait développer une compréhension de la psychologie des utilisateurs. La simplicité de l'objectif (prédire le prochain mot) n'empêche pas la complexité du moyen (une forme de compréhension, de raisonnement, ou d’intelligence).
Adam Brown, chercheur chez DeepMind, compare ce mécanisme à l’évolution humaine. L’intelligence humaine elle-même est le produit d’un mécanisme aveugle, la sélection naturelle, guidée par une règle simple : maximiser le nombre de descendants viables. Cette règle n’a rien d’intelligente, mais pour la satisfaire, la sélection naturelle a produit des solutions sophistiquées, dont le cerveau humain. De la même manière, pour pouvoir prédire, mot par mot, la suite d’un texte, un modèle d’IA est contraint de développer des représentations internes complexes et d’apprendre à les exploiter de manière transversale - une forme d’intelligence.
D’aucuns rétorquent que l’IA ne sera jamais véritablement intelligente car elle est faite de couches de neurones artificiels échangeant des signaux numériques dans des puces de silicium. Mais le cerveau humain n’est-il pas, lui aussi, un assemblage de neurones communiquant par des signaux électrochimiques ? À l’échelle du neurone individuel, qu'il soit biologique ou artificiel, il n'y a pas d'intelligence, seulement un signal mécanique. L'intelligence est une propriété du système, pas de ses composants. Thibaut Giraud consacre des pages incisives à ceux qui, explicitement ou non, postulent un « je ne sais quoi » censé séparer à jamais l’intelligence humaine de toute intelligence artificielle. Le grand avantage du « je-ne-sais-quoi », observe-t-il avec ironie, c’est qu’il dispense précisément de dire ce qu’il est.