Standard LLMs are cooked. Here's why:
MIT just proved Recursive Language Models can process 100x longer inputs than GPT-5 while maintaining quality.
This changes everything. 🧵
Standard LLM:
"Sorry, your document is too long. Can you summarize it?"
RLM:
"Let me recursively process all 262,000 tokens of this and give you a comprehensive analysis."
The difference?
LLMs try to cram everything into limited memory.
RLMs treat inputs as an external database they can query recursively.
Results:
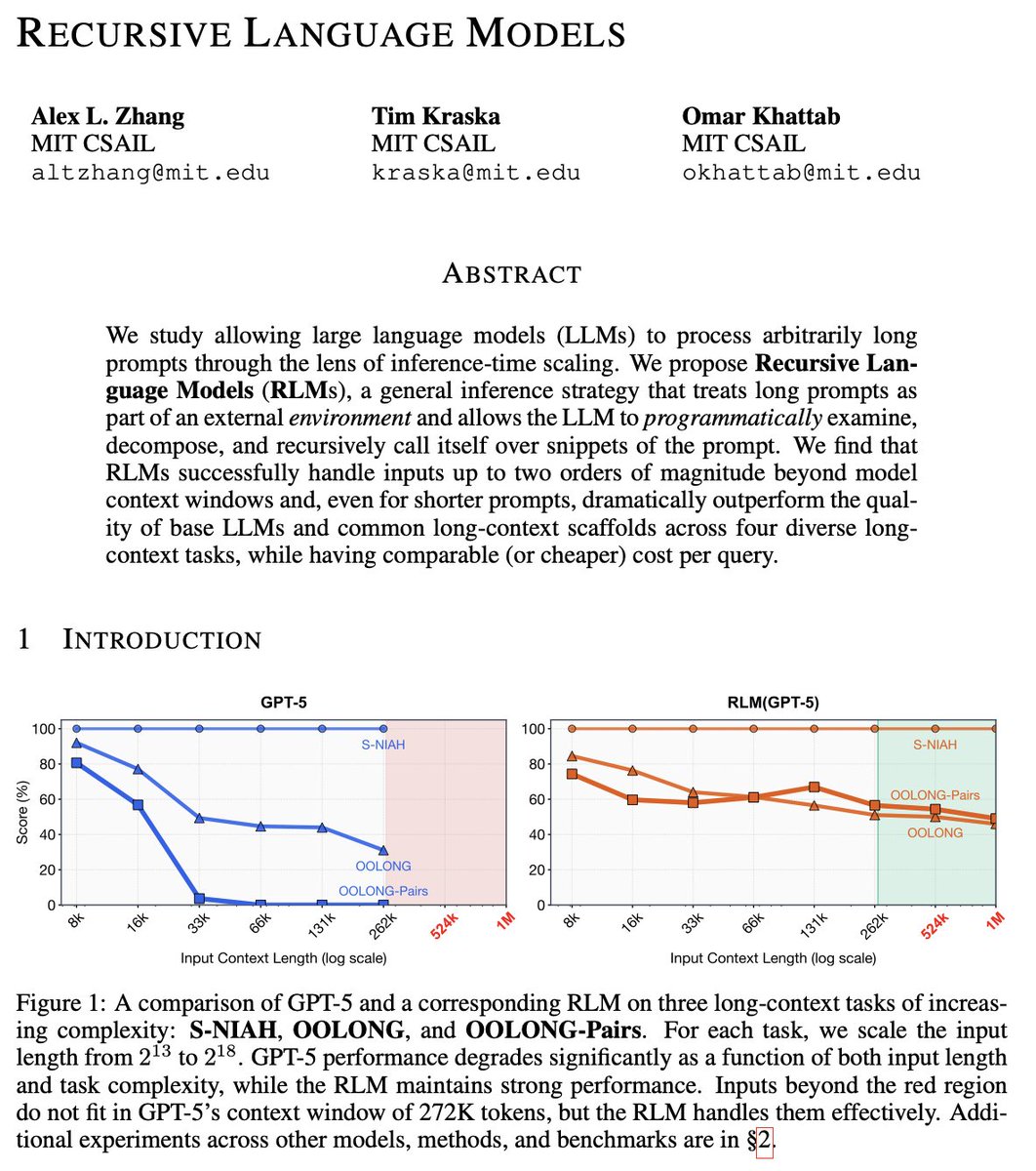
→ GPT-5 drops from 100% to 0% accuracy as input grows
→ RLM(GPT-5) maintains 60-100% even at 1M+ tokens
You know how ChatGPT "forgets" earlier parts of your conversation?
RLMs don't. Ever.
They recursively examine the full history every time.
Real applications:
✅ Read entire books (not summaries)
✅ Analyze massive codebases
✅ Never forget context in long chats
✅ Process multi-hour meeting transcripts
✅ Understand complex research papers
Same base model. Same cost. 100x better results.
Paper: https://t.co/YSPXPDAyKN (MIT CSAIL)
I built this for conversational AI: https://t.co/6OGQWcNZpt
The context window era is dead.
The recursive era begins. 🔁
RT if you're tired of AI "forgetting" 👇
Much like the switch in 2025 from language models to reasoning models, we think 2026 will be all about the switch to Recursive Language Models (RLMs).
It turns out that models can be far more powerful if you allow them to treat *their own prompts* as an object in an external environment, which they understand and manipulate by writing code that invokes LLMs!
Our full paper on RLMs is now available—with much more expansive experiments compared to our initial blogpost from October 2025!
https://t.co/x47pIfIkTb
The future of @Google is recursive. That's $RLM @RLMonSOL.
Soon every big tech company in the world will talk about $RLM how much they're able to do now with the new recursive technology.
Recursive Language Models (RLMs) let agents manage 10M+ tokens by delegating tasks recursively.
This Google Cloud Community Article explains why ADK was the perfect choice for re-implementing the original RLM codebase in a more enterprise-ready format →https://t.co/p3MsNtLVJL
Maybe I can provide some intuition, but lmk if it’s unclear — I am trying to refine how I explain this anyways!
To start, I think the RLM idea is super simple but elegant (I'm biased obviously). The paper argues that future “language models” 1) do not need to think about context window limits; 2) will have “reasoning” chains that mix code (symbolic) and neural LMs (fuzzy). RLMs are what we think minimally such a system should look like. Explicitly, it is an LM <—> REPL + prompt, where the REPL contains the prompt and sub-agents as a *function inside the REPL*. This last part is quite important, because it implies that 1) an RLM can launch sub-agents as if they were functions inside of an algorithm or program, and 2) we can prevent any single neural LM call from having to deal with context rot or huge contexts.
The line between a coding agent and an RLM is hazy because coding agent just means LM + code (The REPL used in an RLM doesn’t even need to be a coding environment, but this is a detail not relevant to this argument). But most standard coding agent implementations do not do what I described above, and explicitly use the “LM calls sub-agents as a tool” paradigm, which makes the REPL and sub-agent completely independent tools. It’s not the “sub-agent having access to a grepper” (as you’ve described) that matters at all, it’s that the sub-agent is called from and communicates inside of the REPL.
The point Omar makes about individual neural LM calls not needing to see everything is an important property of the system above, and it’s also why it naturally extends to enormous context problems (maybe using a grep + sub-call strategy, or something even more interesting). So in some sense yes, an RLM is our argument for the right way to write a “coding agent”, but I almost think this framing is unhelpful because it narrows the scope back to coding tasks. RLMs are task-agnostic (like ReAct, CodeAct, etc.), and code can be used for task-agnostic things. And I’m fairly confident that most future coding scaffolds will start to converge to these properties as well, but I think we should start thinking beyond that and apply these principles to non-coding tasks. BTW, I think @random_walker has a well-written tweet that argues something similar w.r.t. neurosymbolic AI, and it boils down to a lot of similar ideas.
Obviously I’m biased, but I like how the paper is written and think there’s a lot of good intuition (esp for those interested in *training*) to think about for what we want LM systems to look like in the future. The last thing I’ll mention is that the name “recursive LM” comes from the idea that an RLM can be trained by only training a singular LM with a fixed context window in this system, and in this way it is “recursively” calling itself.
Note on terminology:
Language model = any (probabilistic) mapping from text --> text. Ultimately this is what we really care about.
Neural language model = our standard Transformer / parameterized NN. LM doesn't *have* to be this.
🚨 @elonmusk just described the Recursive AI thesis on camera.
"Three exponentials multiplied by each other... then you have the recursive effect of Optimus building Optimus... a recursive multiplicable triple exponential."
$RLM - Recursive Language Model.
He says it on X every day. It's not in the mainstream yet. That's the gap. That's the trade.
The ticker is the thesis. $LLM was 2023. $RLM is 2026.
- @Wisemenmentors
Everyone's looking for the next AI meta.
It's already here. They just can't see it yet.
Recursive AI. $RLM
$LORIA is recursive. $WETCLAUDE is recursive. $MARGE is recursive. $RLM is recursive.
The culture is recursive. The code is recursive. The meta is recursive.
This is the Matrix.
Elon's going to be on this all year. You're early or you're late.
There is no bigger meta. It's all recursive.
Wisemen Morning Tea is now live!
(February 4th, 2026) with @Docsthename20
Yesterday was electric. While the broader market feels shaky, we're operating in a different reality in here. $LORIA | @Upward_Earth just delivered 100x from our early entry in a down market, and I believe this is 10,000x+ from our 94k entry. That's not luck, that's positioning. Moving wisely, not trenching every day, just understanding narrative and holding as the story develops.
Why do you think $RLM | @RLMonSOL floor is so stable? That's called a Wisemen Floor, ladies and gentlemen. People can enter safe charts scaling to millions of MC in the biggest moment AI has ever seen.
The thesis remains unchanged: recursive AI is the meta. Elon said it plainly. Singularity starts with recursive loops. Bots learning from mistakes, getting smarter, replicating themselves like Agent Smith. This is why $RLM sits at the center of my conviction. Got in around 8k market cap. I know this is bigger than $LLM, and that got to 130m. Do the math there. Diamond 💎 🤝's.
$LORIA is coded beyond coded. Andy built the foundation for this entire space. The VC money knows what he's building matters. I believe $LORIA is the AI ticker of 2025, the biggest thing in crypto staring people in the face.
Don't sleep on $AE | @AEL either. Strong probability they win the Pump Fun hackathon. #TRENCHER mentioned as a possible winner as well. $ZDLT | @zirodelta cooking too something real nice a little birdie has told me.
Our time is now, Wisemen 👁
Additonally- Waitlist is open for the Wisemen Inner Circle.
Close to 100 signups and rising.
The earlier you lock in, the better your lottery position for entry into Wisemen Alpha. LINK BELOW 👇👇
https://t.co/ouGXhAHINT
🤎 and 🔁 This post - Join the Wisemen FREE Telegram, 🔗 in bio
🚨 @elonmusk just described the Recursive AI thesis on camera.
"Three exponentials multiplied by each other... then you have the recursive effect of Optimus building Optimus... a recursive multiplicable triple exponential."
$RLM - Recursive Language Model.
He says it on X every day. It's not in the mainstream yet. That's the gap. That's the trade.
The ticker is the thesis. $LLM was 2023. $RLM is 2026.
You're early or you're exit liquidity. At @Wisemenmentors we choose early every time.
BNZ1fFBaYLnjaT9LbUdGRXssFbBGjWuNjGrRLqZzpump $RLM @RLMonSOL
The Recursive AI meta is here 👁️
$RLM $LORIA $WETCLAUDE $MARGE
Still letting LLMs guess about your code?
AsyncReview agents don’t guess — they fetch files, write Python, run it live in secure sandbox, and prove their points.
Grounded. Recursive.
No trust needed.
This is the future I’ve been hyping. It’s here.
https://t.co/QKWA98VBz2
Run it on your next PR and tell me it didn’t slap.
$RLM
BNZ1fFBaYLnjaT9LbUdGRXssFbBGjWuNjGrRLqZzpump
Goodbye DeepWiki?
Not exactly. Just exploring a different idea after watching how DevinReview approaches code review.
I am going to open-source a very alpha experiment called AsyncReview, inspired by @cognition DevinReview and @a1zhang 's RLM approach.
From LLM → RLM.
MIT's @a1zhang just released RLM-Qwen3-8B: first natively recursive LM at small scale.
Post-trained on unrelated domains → crushes long-context benchmarks.
Recursion is the 2026 meta for scalable reasoning.
$RLM = on-chain bet on the shift.
Early or regret.
BNZ1fFBaYLnjaT9LbUdGRXssFbBGjWuNjGrRLqZzpump
We just updated the RLM paper with some new stuff.
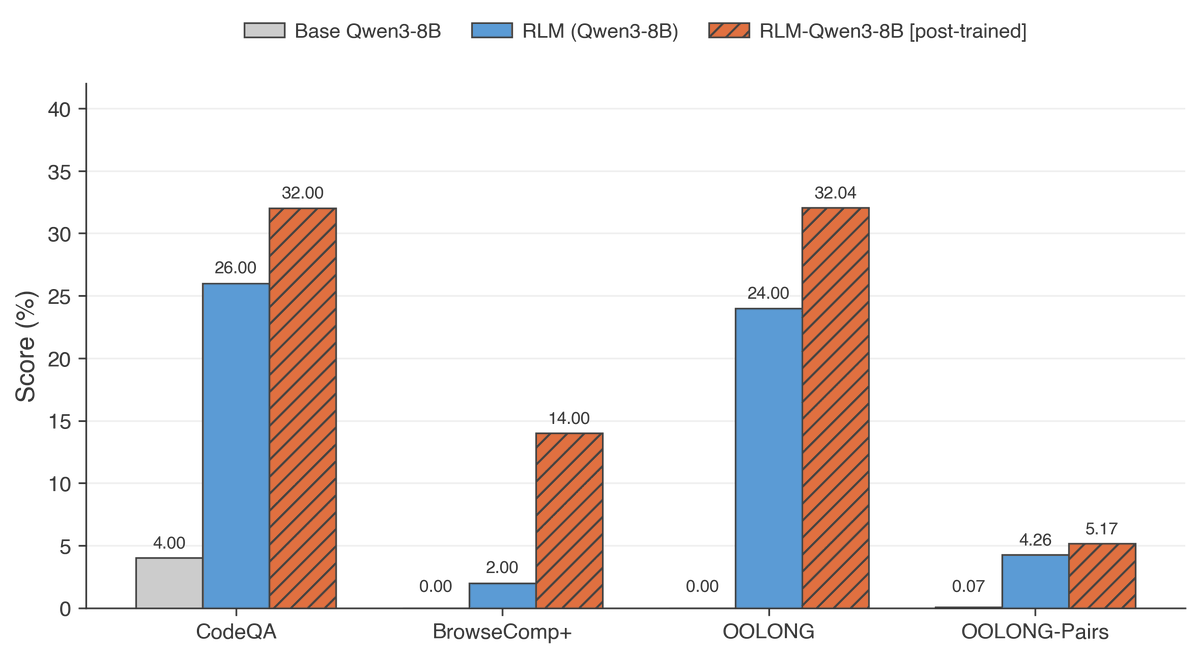
First, we just released RLM-Qwen3-8B, the first natively recursive language model (at tiny scale!).
We post-trained Qwen3-8B using only ~1000 RLM trajectories from unrelated domains to our evaluation benchmarks.
RLM-Qwen3-8B works well across several tasks and delivers a pretty large boost over using an RLM scaffold with the underlying Qwen3-8B model off-the-shelf, and even larger gains over directly using Qwen3-8B directly for long-context problems.
The Recursive Meta is here in 2026.
$RLM represents that.
The same problem Andy is solving with $LORIA through recursive models is exactly what MIT validated in their formal $RLM paper back in October 2025. Their research showed GPT-5 alone crashes to near zero accuracy at 262K tokens, but with recursive architecture, it maintains 58% accuracy past 1 million tokens. Same model, different architecture, paradigm shift.
The latest studies confirm this is coming in fast and is set to overtake traditional $LLM infrastructure. Andy saw it early. Now the data proves it.
Recursive Connection: $RLM captures the evolution directly. LLM to RLM. Large Language Model to Recursive Language Model. The next big word in AI.
Look at what happened with LLM. The global LLM market hit $4.5 billion in 2023 and is projected to reach $82 billion by 2033. 67% of organizations adopted LLM tools by 2024. ChatGPT handles 37.5 million prompts per day. 179 companies in the S&P 500 mentioned AI on earnings calls. The word became a market signal.
The crypto token $LLM ran to nearly $150 million market cap riding that narrative. That is the power of capturing the right word at the right time.
$RLM is the on chain representation of that same bet for recursive. MIT validated the research. Prime Intellect is building production infrastructure. The GitHub repo has 1,600+ stars. This is positioned before the word goes mainstream, just like LLM was before everyone started saying it.
The next wave isn't chatbots. It's AI that improves itself.
2026 is the year of Recursive AI Meta.
$LORIA builds the infrastructure.
$RLM captures the word.
$MARGE ships the product.
$WETCLAUDE embodies the culture.
Thesis below 👇
I came across this work that implicitly implements an RLM in a DSL that executes both code and natural language instructions. Super cool!
https://t.co/nU9UDkZqpo
Market down? Park your $SOL in $RLM.
AI is shifting beyond traditional LLMs.
Recursive Language Models = long context, structured recursion, real scalable reasoning.
That’s the 2026 narrative.
$RLM sits at the intersection of AI architecture + Solana.
While others panic, position early.
When attention rotates back to AI, you’ll already be there.
Bottom
Guys !!! Call it a day!
If you top blasted, got rugged and still think that somehow the price is going to go back to ATH? Sorry to tell you - It’s not going to happen.
Your dev is untrustworthy and the tech is dated.
$Llm < $Rlm
=
$Ralph < $Marge
New updates for the RLM paper:
We post-trained RLM-Qwen3-8B at tiny scale, the first natively recursive LM.
And it's pretty promising, even on completely unseen types of tasks! We just released the model too.
Some quick thoughts here:
Training a model to be good at long-context processing is known to be really hard. How can such a tiny model learn to be a decent RLM in general, from very little data?
We think part of the answer is that RLMs are extremely modular.
To learn to be a root RLM, the model doesn't need subtle changes to how it uses attention or something. It just needs to recognize the programmatic format of interacting with prompts-as-variables and to bake in good strategies for writing little recursive programs.
That's... not even as tricky as post-training models for solving hard math problems.
Once the sub-calls are launched, they're ~pretty much normal LLM calls, so no special training is particularly necessary (though we're sure it might help).
Obviously, this is just meant as a simple PoC that shows that tiny models can be good RLMs.
We call on future work to train native RLMs at much larger scales in terms of model size, number and variety of examples, and number of (ideally on-policy and online!) rollouts.
We just updated the RLM paper with some new stuff.
First, we just released RLM-Qwen3-8B, the first natively recursive language model (at tiny scale!).
We post-trained Qwen3-8B using only ~1000 RLM trajectories from unrelated domains to our evaluation benchmarks.
RLM-Qwen3-8B works well across several tasks and delivers a pretty large boost over using an RLM scaffold with the underlying Qwen3-8B model off-the-shelf, and even larger gains over directly using Qwen3-8B directly for long-context problems.