Static math benchmarks saturate. We built one that doesn't.
Announcing MathDuels, the first self-play math benchmark.
Every frontier LLM writes problems for the others, and is graded on the ones written for it. As models improve, so does the benchmark.
Full report -- all five solutions, every model's reasoning trace, the constraint encoding, and a one-clue modification that collapses the puzzle to zero solutions, at the Rabdology blog:
https://t.co/HMsNKLmV1W
THE SYMPOSIUM PUZZLE:
The final dinner of the symposium was less a banquet than a convergence theorem that had failed to be uniform. Five luminaries -- Hardy, Poincaré, von Neumann, Gödel, and Ramanujan -- sat in a row at the head table, each in a different jacket, each with a different drink, each newly returned from a different lecture tour, and each guarding a different mathematical instrument as though it were a proof of the Riemann Hypothesis.
Hardy sat brooding at the far left in herringbone, one hand curled around an espresso, the other resting upon an antique abacus whose beads he refused, on principle, to move. Immediately to his right sat a severe scholar in charcoal, upright as a metronome and no more companionable.
Poincaré, ever the classicist, wore tweed. Farther down the line, Ramanujan (newly back from Göttingen) sat resplendent in navy, sipping tea and turning a golden compass over in his fingers as though it might draw identities straight out of the air. The navy jacket sat immediately to the left of the pinstripes, a juxtaposition that pleased no tailor present. The guest who had lectured at Cambridge, meanwhile, was the one in herringbone.
When the conversation turned from foundations to apparatus, the scholar fresh from Princeton began boasting of a brass astrolabe he had recently acquired. Seated right next to him, the Göttingen speaker sneered that the workmanship was inferior to what one found on the Continent. Not to be outdone, von Neumann slapped an ivory slide rule onto the table with algorithmic enthusiasm.
Gödel, with characteristic gravity, raised a glass of port in a toast that seemed prepared for its own incompleteness. The scholar just back from Oxford preferred brandy and, being full of it, soon leapt onto the table to make a point that no one had invited. In the ensuing disorder, a fellow guest's black coffee went flying. That black coffee, in the left-to-right order of cups along the table, had been sitting somewhere between Hardy's espresso and Ramanujan's tea.
By morning the hall was deserted. Under the table lay four instruments: the antique abacus, the brass astrolabe, the ivory slide rule, and the golden compass.
The silver caliper was gone.
Who possessed each instrument -- and who had been carrying the missing silver caliper?
The Symposium Riddle has multiple valid solutions.
We gave it to six frontier thinking models. Five of the six confidently reported a single answer — three said Gödel, two said Poincaré. None of those five noticed the puzzle was underdetermined. They each found a solution, satisfied every stated clue, and stopped.
The Gödel answers shared a tell. The puzzle describes the seat-2 guest as "a severe scholar in charcoal, upright as a metronome and no more companionable." That is atmosphere, not a constraint. Three models read it as one -- Gödel was austere, von Neumann was not, therefore Gödel sits at seat 2 -- and propagated that inference through the rest of the clues. The biographical hunch, applied as a hidden constraint, collapses the solution set from five to one. The reasoning is plausible, not logical.
Call it the personality trap. The models did not fail the CSP; they answered a different CSP, one whose constraints had been silently augmented with trivia from their training corpus. The real failure is at the meta-level: checking whether the problem you are solving is the problem you were given.
One model behaved differently. GPT wrote a brute-force search over all permutations, returned five valid assignments, and reported the puzzle as underdetermined. It did not solve harder. It refused to over-commit.
nice math problem i came up with last december...
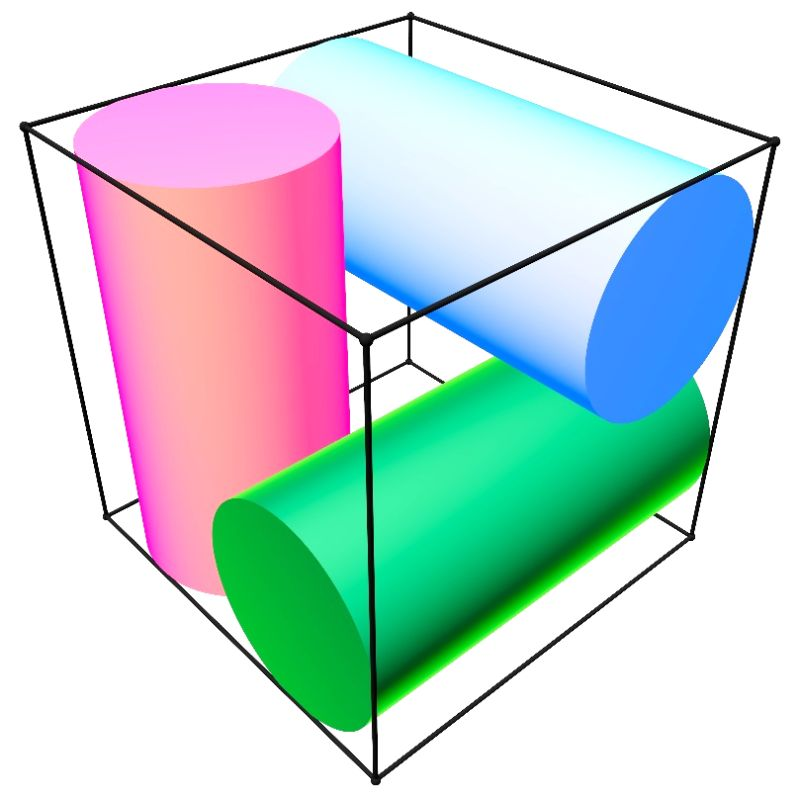
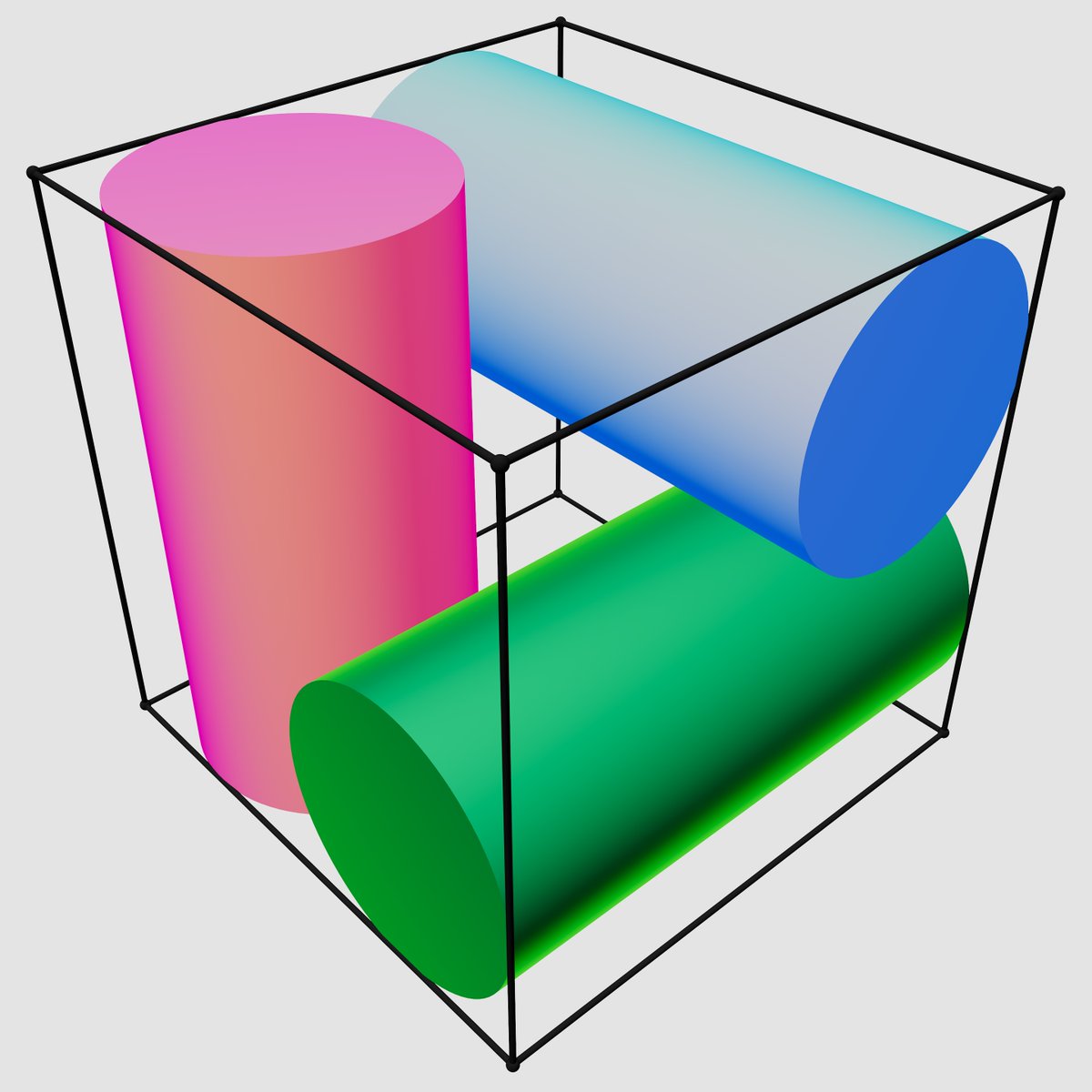
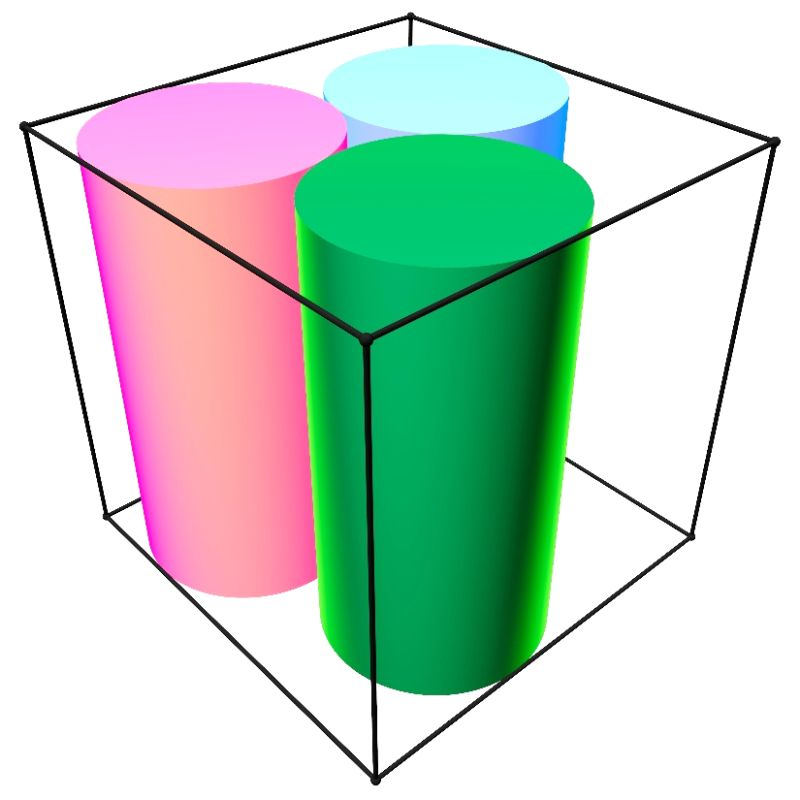
Consider a cube of side length 2, aligned with the coordinate axes. Place three cylinders inside it, each of height 2 and radius R, each aligned with some coordinate axis. The cylinders may not intersect. What is the maximal R?
We are delighted to unveil our research blog Rabdology at https://t.co/NELXEG2rAp, where we chart the jagged math-frontier of AI reasoning.
This is our first post in a weekly series. Read on, and if you enjoy it, please subscribe! (Link at bottom of blog's main page.)
The Three-Cylinders Problem: When AI models choose Beauty over Truth
https://t.co/qLHmfJwz2s
We pose a problem that a good geometry student can solve in twenty minutes. We gave it to four of the world’s most advanced AI models and watched what happened. Three of them got it wrong — and the way they got it wrong tells you something different about the state of AI mathematical reasoning than the usual benchmarks.
Very timely, especially in light of revelation that 1/3rd of problems in FrontierMath are fatally flawed.
As expert human validation of frontier math tasks approaches its inevitable limit, LLMs are stepping in to fill the void.
But our work below shows that the discovery of mistakes in FrontierMath problems didn't necessarily have to wait for a frontier model like GPT-5.5. Much smaller and even open-source models can be as effective at verifying math proofs: their weights embody the necessary knowledge, as one might expect -- checking proofs ought to be easier than writing proofs.
The crucial thing that makes this work is the use of "prompt ensembles", each of which modularly checks a different facet of a given proof, and some of which are even specific to the domain/sub-domain of math.
Ideas like meta-prompting, agent skills, and autoresearch will undoubtedly evolve to make LLMs as judges of math proofs even more effective in future.
Thanks for the question:
Average accuracy on MathDuels:
Solving their own problems: ~92%
Solving others' problems: ~88%
Producing the correct answer at authoring stage: ~86%
Takeaways:
1. Models have a small edge on their own problems.
2. Solving is easier than constructing & giving the correct answer.
Static math benchmarks saturate. We built one that doesn't.
Announcing MathDuels, the first self-play math benchmark.
Every frontier LLM writes problems for the others, and is graded on the ones written for it. As models improve, so does the benchmark.
In MathDuels leaderboard, Gemini-3-Flash dominates at its size: the only models ahead of it are the latest, largest frontier releases.
Gemma-4-31b-it has the highest author rating of any opensource model.
Thanks @GoogleDeepMind for these smart little models 🥹
Static math benchmarks saturate. We built one that doesn't.
Announcing MathDuels, the first self-play math benchmark.
Every frontier LLM writes problems for the others, and is graded on the ones written for it. As models improve, so does the benchmark.
@JasonRute That said, it'd be interesting to see models leverage the asymmetry here: creating problems that are way harder to solve than to construct. (like you mentioned)
There are some samples of generated problems on https://t.co/zddK0ndeCy. None of them relies on construction asymmetry.
@JasonRute We didn't observe this in our experiments, for two reasons:
1. The author prompt discourages problems that are merely computationally difficult.
2. Models don't have Python tools available during the author stage.
@somi_ai We use an independent verifier LLM to determine which answer is correct (golden solution v.s. solvers' solutions).
This turns out to be reliable: when using different verifiers (GPT-5.4 & Gemini-3.1-Pro), the result is the same at 99.4% of the time. (Section 4.3 in the paper)
MathDuels aims to make math evaluation less dependent on a fixed pool of human-written problems. It will keep evolving at https://t.co/mlMLqhmtwi as new models arrive.
Work done by researchers at University of Pennsylvania and @Rabdos_AI, a startup charting the mathematical frontier of AI.
📊 Leaderboard: https://t.co/cpPHY1z0ii
📄Paper: https://t.co/6MNEuShkCA
Want your model on the leaderboard? DM us!
Another observation: thinking effort matters less for Authoring than Solving.
Dropping Gemini-3.1-Pro to low thinking moves its Solve Rating rank from 2nd to 19th, while its Author Rating rank drops from 2nd to 10th. The same pattern holds for GPT-5.4 and Gemini-3-Flash.