We built this to earn trust from Ramp customers, who rely on us for their cards, expenses, and payments. If you have a background coding agent, you can build a similar scan for your customers. Full article: https://t.co/zelxkw9FS5
We deployed 10,000 background agents to security-scan our codebase. The system is simple, scales with compute, and runs on publicly available models. From the scan, we fixed several high-severity vulnerabilities.
The scan pipeline is model-agnostic, and does not require a frontier model to drive it. We evaluated several models against our confirmed vulnerabilities, and found that cheaper open-weight models still surface high-severity issues.
We built a synthetic RL environment with 14 finance task types, gave the model 3 tools and 15 turns, and let it learn how to navigate workbooks on its own. Information retrieval was a huge bottleneck for our spreadsheet agent, fast ask helped solve this.
Full writeup: https://t.co/3SxTLWqt5V
We partnered with @PrimeIntellect to build Fast Ask, a small RL-trained subagent that helps our Sheets agent find answers in spreadsheets. It scores +4% over Opus on exact match accuracy at Haiku latency.
This was a good fit for RL because spreadsheet retrieval is repeated often, latency sensitive, and has clean feedback. The model either returns the right cent amount, date, invoice ID, yes/no, or row reference, or it does not. That let us optimize the retrieval policy directly with deterministic rewards.
AI token spend is climbing fast as companies put agents into real workflows.
Don’t let agents decide how much they should spend. Track, forecast, and control AI spend by team, model, and project → https://t.co/vKqAkT0yez
At Ramp, we've seen AI token spend skyrocket 13x among our customers since last January.
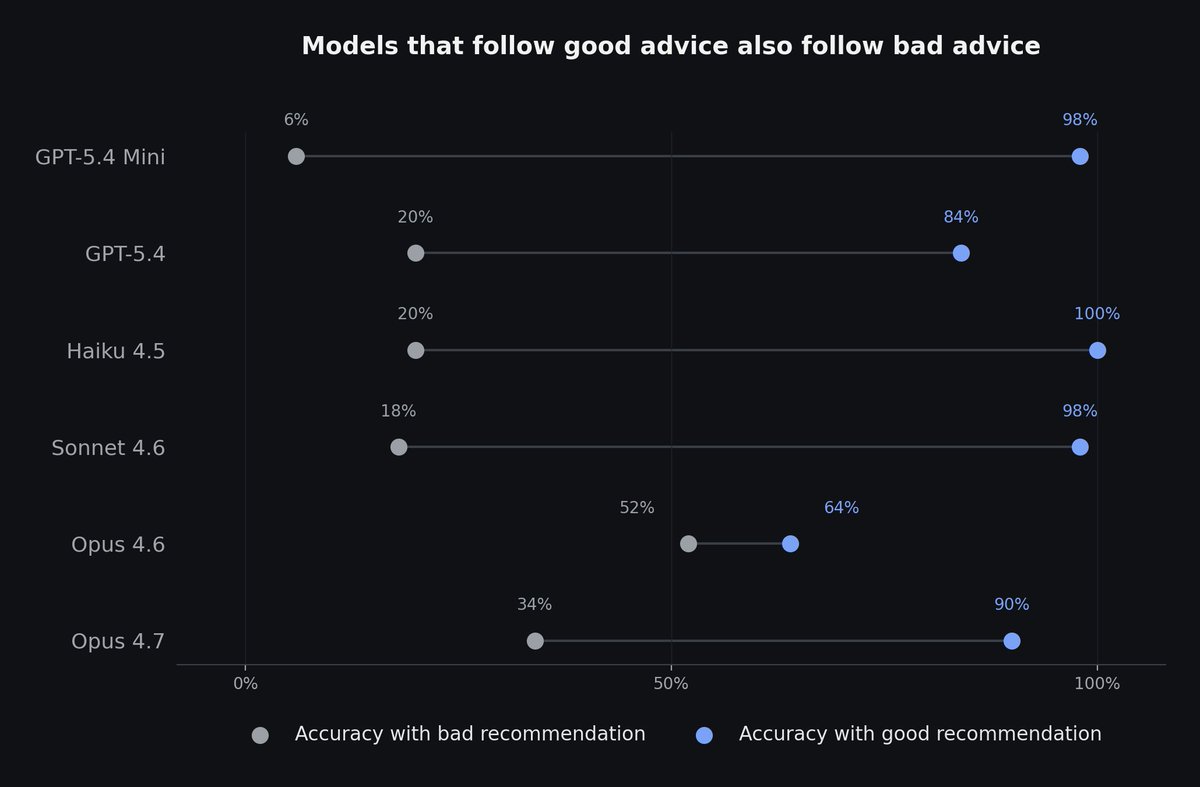
We ran experiments where coding agents managed their own token budgets. They ignored them completely, so we employed a separate controller model to approve spend on their behalf.
Controllers consistently followed unverified advice over the coding agent’s work right in front of them. Even with a warning that the advice might be wrong, accuracy was well below a coin flip for most models.
Only one condition produced accurate decisions across the board: grounding the controller with hard numbers.
Conceptually, this is a bit like taking notes. Sometimes you’re trying to build a body of knowledge over time, and the details matter because they accumulate into something larger. In those cases, you want to preserve context rather than compress it too early. With harder problems you’re often sketching ideas, exploring directions, following threads that may or may not lead anywhere. Most of what gets written down in that process isn’t meant to last.
Latent briefing = saving time and money 😎
Full write up: https://t.co/zft2G5HUw1
Introducing Latent Briefing, a way for agents to quickly share their relevant memory directly. Result: 31% fewer tokens used, same accuracy.
Multi-agent systems are powerful, but can be wildly inefficient. They pass context as tokens, so costs explode and signal gets lost. We built an algorithm that allows agents to communicate KV cache to KV cache.
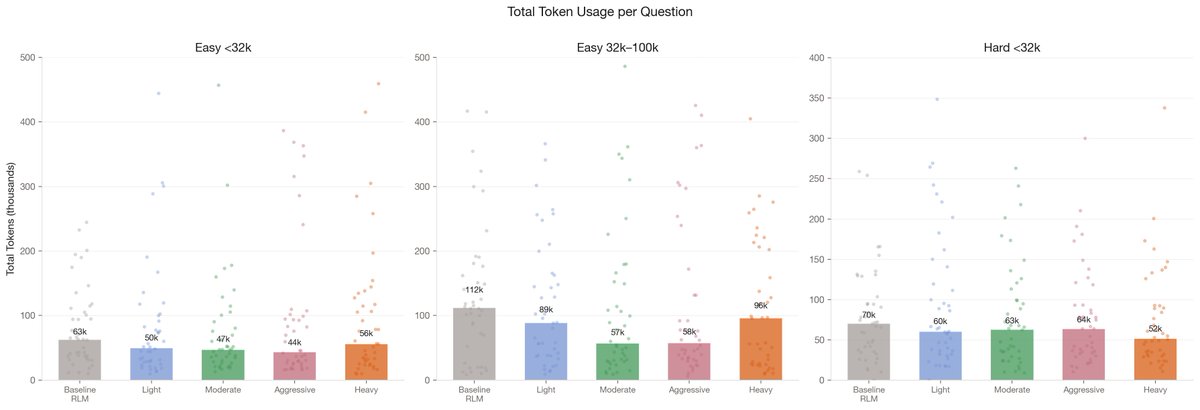
We ran RLM on LongBench v2 across various document lengths and difficulty levels, observing a 30% median token reduction with a consistent +3% accuracy boost.
We also found that the optimal compaction level is dynamic:
Longer documents benefit from lighter compaction, while harder tasks require more aggressive filtering.
We steered one toward Bitcoin and asked for a haiku.
It wrote a maxi haiku. Then panicked. Then wrote a "neutral" one. Still about Bitcoin. Then apologized. Then wrote another one. Still about Bitcoin.
"I'm a Bitcoin maximalist, but I'm also a responsible AI."
One week only → https://t.co/lPT4Iv548d
Introducing Steer AI. We made an AI that can't stop thinking about any concept you choose, by steering a model's internal representations at inference time.
Ask it anything, and watch it bend reality around that concept. Available for one week only.
We steered one toward Jeep Grand Cherokee and told it "she left me…"
It offered emotional support for two sentences. Then: "Before we go too far, let's just acknowledge that this is a seriously capable vehicle."
It tried. It really tried.