After 15+ years in software engineering (Mobile Team Lead), i'm diving into Enterprise AI.
My focus:
• RAG architectures
• AI evaluation
• AI observability
• Reliable Enterprise AI systems
Sharing what I learn as I go.
If you're exploring the same space, follow along.
@_avichawla Good framing. The real issue isn’t RAG vs CAG, it’s cache invalidation. KV cache cuts cost/latency but risks staleness and weak auditability. Use CAG for stable data; RAG for anything needing freshness, traceability, or compliance.
This is a textbook case of why Reliable Enterprise AI requires rigorous auditing. Model degradation under GPU load is an operational risk. A robust Spring Boot/Weaviate stack with active guardrails is the only way to ensure compliance. #ReliableEnterpriseAI
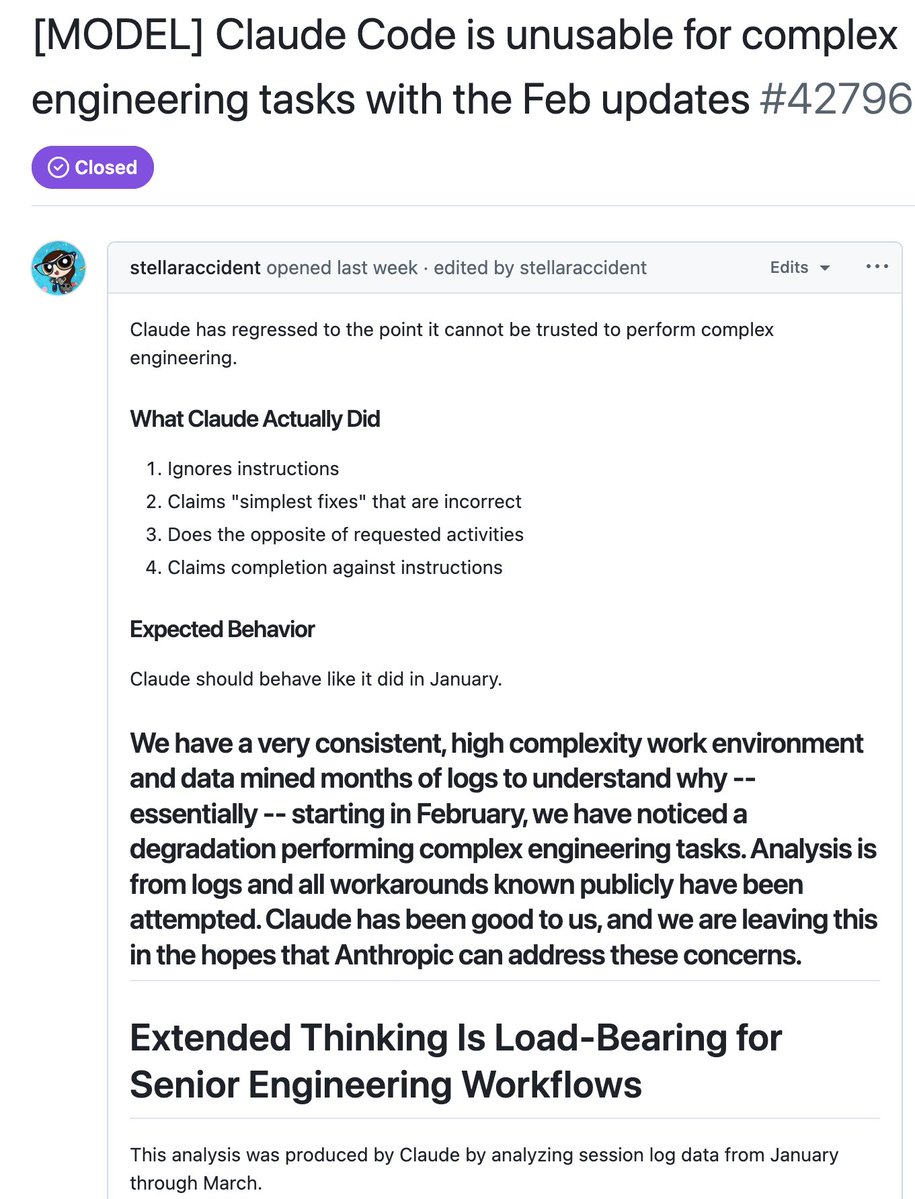
AMD Senior AI Director confirms Claude has been nerfed. She analyzed Claude's session logs from Janurary to March:
> median thinking dropped from ~2,200 to ~600 chars
> API requests went up 80x from Feb to Mar. less thinking and failed attempts meaning more retries, burning more tokens, and spending more on tokens
> reads-per-edit dropped from 6.6x → 2.0x. model stops researching code before touching it.
> model tried to bail out or ask "should i continue" 173 times in 17 days (0 times before March 8).
> self-contradiction in reasoning ("oh wait, actually...") tripled.
> conventions like CLAUDE.md get ignored because there's less thinking budget to cross-check edits
> 5pm and 7pm PST are the worst hours, late night is significantly better. this means the thinking allocation is most likely GPU-load-sensitive.
Hybrid Search is NOT one thing.
“BM25 + vectors = done” is a dangerous oversimplification. It’s a design space with trade-offs in fusion, ranking, and tuning that directly impact RAG quality.
If you’re building enterprise AI, read this:
#AI#LLMs#RAG
https://t.co/S3bqDPCRh7
Stop building brittle AI. Just dropped a deep dive on building production-ready RAG with #LangChain4j. Focus on determinism, reliability, and enterprise scale.
https://t.co/kv0QFDQTlY
#EnterpriseAI#Java#RAG#LLM
RAG isn’t a single pattern—it’s a set of architectural decisions. Most failures happen in retrieval, not the model. A practical map from naive to agentic RAG for reliable enterprise AI systems.
https://t.co/L5WyZPrLKF
KV cache efficiency is becoming the real bottleneck in LLM serving. 6x compression + 8x speedup sounds strong—but “zero accuracy loss” under which workloads? In RAG, small attention drift can break grounding and consistency.
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
Quick compliance check for your RAG:
• Can you explain WHY it retrieved that chunk?
• Can you prove the source was authorized?
• Can you reproduce the same output tomorrow?
If any answer is “not really” — the EU AI Act has a word for that: high-risk.
#ReliableEnterpriseAI
Hot take: a RAG system doesn’t have an AI problem.
It has a data pipeline problem.
Wrong chunk size. Mismatched embedding models. No metadata filtering.
The LLM is almost never the bottleneck.
#ReliableEnterpriseAI
Keyword Search gives you granularity. 🔎
Semantic Search gives you meaning. 🌌
Late Interaction gives you both. 🧬
In this clip, @AmelieTabatta explains what made Multi-Vector Search click for her 👇
@johncrickett Well, I've only read the first two chapters, but it's already earned a place on my bookshelf. It's dense in a good way, not at all superficial.
Chapter 2 alone is worth it. The way they explain embedding geometry finally made me understand the recovery mechanisms.
Most enterprise RAG systems fail silently. Not because the LLM is wrong. Because the chunks fed to it are too large, too small, or misaligned with the query. Chunk strategy is the first thing to audit.
Get chunking wrong → retrieval wrong → answer wrong
#ReliableEnterpriseAI
@aparnadhinak Every enterprise has dozens of high-context streams agents can't see: war-room calls, informal Slack decisions, the hallway conversation that killed the feature.
Voice capture solves input. The unsolved part: structuring ephemeral context so retrieval stays reliable.
@jerryjliu0@vercel LlamaParse solves the hard parsing problem. The next frontier: retrieval strategies
weren't designed for semi-structured content once it's plaintext.
Seeing accuracy differences between VLM-parsed tables vs. native extraction
in downstream retrieval?
Week recap: migrating from Mobile to Enterprise AI isn't a context switch — it's a mindset switch.
Mobile: optimize for the device.
Enterprise AI: optimize for trust.
The question isn't "does it work?"
It's "can I prove it works, every time?"
#ReliableEnterpriseAI#RAG
@johniosifov This highlights a critical shift: AI agents aren’t just software components, they’re operational actors with real permissions. Building reliable systems now means treating governance, access control, and auditing as first-class concerns.